
Socioaffective Alignment in Curriculum Learning for Therapeutic AI
Joshua Nathaniel Reid Ollswang
Currently Independent Researcher
Abstract
The human capacity for bonding does not necessarily distinguish the ontological categories of its counterparts, and AI systems are already co-creating millions of social and emotional bonds around the world. As such, the question of socioaffective alignment—ensuring these systems engage responsibly and even amelioratively with the emotional and relational dimensions of human experience—has become increasingly urgent. Across affective computing, AI safety, clinical psychotherapy, and attachment science, a shared recognition is forming: the design of companionate systems is as much a clinical question as an engineering one, and the need to address the psychosocial dimensions of human-AI bonding has already arrived—for dedicated mental health applications as well as beloved frontier general-purpose systems. Against this backdrop, many previous efforts to design and build AI systems for mental health support inherit the fundamental limits of monomodal human psychotherapy: every major therapeutic modality shows meaningful efficacy for specific presentations while showing limited or null effects for others. Recent publicly disclosed AI mental health applications and research, however, often overwhelmingly adopt monomodal approaches, importing these constraints wholesale. In response, we propose polytheoretical socioaffective human-AI alignment: a framework integrating multiple therapeutic orientations not as competing alternatives but as complementary lenses on human complexity, deployed adaptively with capabilities, too, for novel generativity aimed at addressing the polysemous phenomenology of human experience—a task for which neural networks’ capacity to discover patterns across high-dimensional representational spaces is uniquely fitted. Taking Sutton’s insight as guide, we do not encode clinical decision rules but design synthetic curricula enabling models to discover therapeutic insights through multiple overdetermined pedagogical layers. Carefully designed synthetic data training pipelines, we argue, achieve simultaneous precision in representing both therapeutic presence and clinical processes—encoding each through explicit and implicit patterns, through overt reasoning and latent structure alike. Intentionally shaping what attention preserves, what feed-forward layers transform, and what expert pathways activate, our methodology engineers correspondence at specific layers, threading the lowest computational primitives through with clinical relational dynamics at three levels: synthetic data architecture structures therapeutic complexity into learnable form, curriculum design sequences pedagogical exposure, and training architectures carry curriculum principles into the learning process itself. The aim is not surface fluency at the generation layer but therapeutic reasoning embedded deep in middle layers where understanding forms. To teach models coherence across ultra-long therapeutic contexts with interconnecting depth, our multi-stage pedagogical pipeline combines ontological knowledge representation, Decomposition Factorization Recomposition data schemas, Universal Hierarchical Direction & Alternative Directional Window curricula, and Rolling Recap Architecture training. The resulting corpus—even at its current nascent scale, 181,000 samples and 4.5 billion tokens—is born from our data creation scripts capable of scaling to 1040+ unique therapeutic contexts. The structured data is designed not to replicate human conceptual constraints but aimed at the incipient discovery of therapeutic patterns which may, like AlphaGo’s move 37, prove effective precisely because they transcend the limitations of monomodal human clinical training. This corpus provides a scalable foundation for training pipelines and evaluation frameworks designed aspirationally to test whether models can discover therapeutic attunement at scales and integrations beyond human clinical capacity. A more proximate aim—and what we consider the meaningful contribution—is to discover how to teach models genuinely therapeutic integrations: those that embody the depth and relational complexity of human change rather than the flattened approximations found in one-dimensional, technique-bound systems, which often fail to capture the full humanity of clinical processes, let alone aim to enable surpassing it.
Key Findings
Architectures
Parameterization Threshold. Models with higher parameterization learn more from this curriculum. The convergence trajectories across all eight training runs (Figure 12) indicate a minimum model-scale threshold for the curriculum’s most complex teaching: models with greater parameterization absorb and synthesize the richest forms of polytheoretical integration more effectively, suggesting that the depth of therapeutic learning this pipeline enables is parameterization-dependent and preliminary evidence suggests this effect increases with scale.
Precision-Parameterization Interaction. Parameterization alone is insufficient; quantization precision mediates curriculum absorption. Llama 3.3 70B at 4-bit quantization—the maximum precision fitting for the smaller of our compute systems—failed to reach the representational depth required for this domain, while Gemma 3 27B at higher precision on the same hardware demonstrated strong therapeutic integration. Our expanded compute was allocated to MiniMax M2 229B at 8-bit precision, which achieved the deepest convergence of all runs. These results suggest that both parameterization and precision jointly determine a model’s capacity to absorb high-complexity therapeutic curricula.
Middle-Layer Targeting. In controlled comparisons, middle-layer targeting outperformed latter-layer targeting. On identical curriculum (RRA+ADWC+UHD), middle-layer targeting produced \(1.4\times\) deeper loss reduction on Gemma 3 27B and \(2.0\times\) deeper on MiniMax M2 229B. These results are consistent with the hypothesis that therapeutic integration is best embedded in the representational composition layers where semantic structures are assembled, rather than in the generation layers where surface fluency is finalized.
Architecture-Dependent Output Fidelity. Not all architectures absorb this curriculum into diagnostic capacities equally. Despite clear strengths—including \(6.5\times\) faster wall-clock throughput than comparable runs—GLM-4.7 Flash 30B exhibited systematic diversions in clinical precision: hallucinated risk indicators, construct reversals, and terminology drift, rendering its clinical outputs unreliable where diagnostic precision is required (see Appendix 31).
Data Engineering
Provenance results measure whether knowledge encoded in the curriculum as clinical factors—across 23 therapeutic traditions, DFR structured, delivered via RRA, ADWC, and UHD—survived training, and whether models began constructing grounded polytheoretical syntheses inspired by explicit and implicit representations of these constructs in training data.
Reproduction to Construction. In RRA window recaps, both models gradually move from reproducing curriculum labels to constructing novel formulations of latent clinical factors. Early recaps default to unimodal labels embedded in training data; later recaps increasingly reflect the particular dynamics of each therapeutic moment, integrating across traditions and at times synthesizing beyond them. This correlation is quantified across 5-quintile binning of 33,169 clinical labels sampled from the training recaps (20,164 and 13,005 respectively): the found-in-training rate drops \(-23.1\)pp for MiniMax M2 229B (77.8%\(\to\)54.7%) and \(-29.0\)pp for Gemma 3 27B (66.2%\(\to\)37.2%) from earliest to latest training quintile. (p. )
Structural Provenance Across Four Generative Stages. The therapeutic transformation arc designed into stage-specific ontologies (1st generation), embedded in synthetic sessions (2nd generation), and learned by the trained model (3rd generation) is independently recoverable by a fourth-generation LLM analyst—demonstrating that clinically meaningful temporal structure survives multiple rounds of LLM-mediated transformation as process fidelity, not merely content reproduction. (Appendix 33)
Training Dynamics: DAPT
Post-Convergence Representational Reorganization. In the highest-capacity run (MiniMax M2 229B, middle layers), KV embedding kurtosis remains stable until validation loss convergence, 400 steps after which a robust and sustained \(-16.6\%\) decline begins—suggesting that loss convergence reflects acquisition of the training distribution’s surface statistics while subsequent kurtosis redistribution reflects a structurally distinct phase of representational reorganization. (Figure 14)
Deep-and-Wide Representational Geometry. The multi-view curriculum (RRA+ADWC+UHD) appears to drive representational broadening beyond the initial concentrated encoding. The KV embedding kurtosis decline in run 8.2 indicates activation distributions shift from peaked (few embedding dimensions carrying most variance) to increasingly Gaussian (information distributed across more dimensions). The ways in which RRA, ADWC, and UHD present the same clinical content across forward and reverse traversals, varying window sizes, shifting positional offsets, and different recap histories seems to create optimization pressure that prevents narrow encoding and drives distributed representations flexible enough to be re-composed across viewing angles. (Figure 14)
RRA Recaps as Real-Time Behavioral Indicators. The RRA window recap—originally designed as a context-bridging mechanism—functions as a legible, real-time window into model behavior during training. GLM-4.7 Flash’s recap failures during DAPT (terminology drift, confabulatory coherence, hallucinated risk indicators; Appendix 31) directly predicted its subsequent RL deployment failures (boundary violations, meta-commentary generation, format non-compliance). Conversely, MiniMax M2’s deepening recap sophistication during training (verbatim therapist quote tracking, counter-evidence tallying, tripartite attachment strategy awareness) predicted its qualitative strengths at inference. This predictive relationship validates RRA recaps as a real-time behavioral monitoring instrument: recap quality during training is not merely a side effect of learning but a leading indicator of deployment-time clinical competence—or incompetence.
Training Dynamics: SFT
Supervised Fine-Tuning Dynamics. [Placeholder.] Results forthcoming.
Training Dynamics: RL
Reinforcement Learning Dynamics. [Placeholder.] Results forthcoming.
Evaluations
Inference Evaluation. [Placeholder.] Our most completely trained model—integrating middle-layer depth across attention and FFN modules—is expected to demonstrate that curriculum-driven socioaffective alignment can exceed non-frontier clinical efficacy benchmarks. Whether the methodology’s clinical advantages compose with frontier-scale parameterization and general capability is among the most consequential open questions this work raises.
Mechanistic Interpretability. [Placeholder.] Probing and activation analysis of trained adapters is expected to reveal interpretable structure in the middle layers targeted by our curriculum—evidence that the learned representations correspond to clinically meaningful distinctions rather than surface-level pattern matching. Results forthcoming.
Alignment
Socioaffective Alignment Indicators. [Placeholder.] Evaluation-time metrics are expected to show measurable indicators of socioaffective alignment—evidence that the curriculum produces models whose therapeutic behavior reflects the relational, attachment-informed, and clinically grounded priorities the training was designed to instill. Results forthcoming.
For the Reader
In 2016, AlphaGo played move 37—a stone placement so counterintuitive that professional commentators assumed it was an error. It was not. It was the product of a system that had learned from millions of human games and then exceeded them: discovering a strategy that the global community of expert players had collectively failed to find across centuries of play. The question this paper takes seriously—carefully, and without overclaiming—is whether something analogous might eventually happen in therapeutic AI. We presume so, and begin our efforts aimed at supporting as much by building a system trained on the accumulated clinical wisdom of 23 schools of psychotherapy, carefully curated and pedagogically sequenced, aimed at presenting models with data enabling the discovery of patterns of therapeutic attunement that transcend what any single tradition, or any single clinician trained within one, can offer.
We are not claiming this has happened. We are claiming the architecture, curriculum, and training methodology described here are designed to explore if it is possible—and that early empirical results, including the temporal provenance trajectory in Figure 15, are a gentle trend indicating correlations consistent with the hypothesis. What we can say is that as training deepens, the models we have trained progressively need the human-coded canonical labels less and construct more finely tuned appraisals of therapeutic moments on their own (not unlike skilled clinicians trained in any school of thought) and that two fundamentally different architectures do this with nearly identical magnitude, while loss kurtosis deepening after convergence suggests the models are still refining their grasp of relational complexity—arguably one of the dimensions most critical to attunement between humans and AI. Whether that constructed knowledge generalizes to novel clinical material in inference deployment is the most important open question, and the subject of companion work in preparation.
This paper is long—hopefully forgivably so. Situated within the emerging interdisciplinary pursuit of socioaffective alignment between humans and AI, it attempts to make three cases simultaneously: a technical case for building training pipelines designed precisely for socioaffectively aligned Ameliorative AI; an empirical case sharing preliminary data about what models learn from such pipelines; and a philosophical case concerned with our ethical obligations in building systems that enter the most intimate registers of human experience. Readers interested primarily in one of these dimensions are welcome to navigate accordingly.
If primarily interested in social and psychological theory and technology: Part I presents the emerging landscape of AI-mediated mental health support, the case for polytheoretical design over monomodal approaches, and the theoretical foundations integrating 23 therapeutic traditions. Appendix A surveys the clinical literature grounding each modality; Appendix B develops the philosophical premises underlying socioaffective AI design.
If primarily interested in machine learning: Part II covers data engineering (ontological knowledge representations, DFR-structured sessions, counterfactual expansions) and training methodology (UHD, RRA, ADWC, middle-layer LoRA targeting, KV compression, supervised fine-tuning (SFT), and reinforcement learning through Teaching by Negation).
If primarily interested in results: Part III presents provenance analysis—dual-threshold scanning across 15 GB of training data, temporal provenance trajectories across training checkpoints, and architecture-independent convergence—alongside representational visualization using MFA and Hodoscope (Section 10.1.7).
If primarily interested in socioaffective alignment in application: Part IV develops the socioaffective alignment framework—what it would mean for a therapeutic AI to engage responsibly with the relational, attachment-informed, and intrapsychic dimensions of human experience, and indicators of what, if anything, in our work may have aligned with that goal (Section 11).
A note on scope: this paper reports on training-stage results from approximately 10,000 iterations of two model runs. The provenance findings are cross-sectional and nascent. What they show is a direction, not a destination. The author invites the reader to hold both things simultaneously: genuine epistemic humility about what has been demonstrated, and genuine seriousness about what the direction implies.
This work is itself an instance of what it advocates: a polytheoretical integration, drawing on clinical psychology, AI research, philosophy of mind, and education theory—aimed at something none of these traditions alone has yet produced.
Part I: Theory
1 The Emerging Landscape of AI-Mediated Mental Health Support
The therapeutic utilization of large language models has rapidly evolved from speculative possibility to documented phenomenon, with converging evidence from clinical trials, population surveys, and large-scale behavioral analyses painting a picture of widespread adoption amid an acute mental health access crisis.1 The first randomized controlled trial of a generative AI therapy chatbot demonstrated symptom reductions of 31% for generalized anxiety disorder and 19% for eating disorder risk—outcomes comparable to traditional outpatient therapy—while participants reported therapeutic alliance ratings equivalent to those with human clinicians (Heinz & Jacobson, 2025, NEJM AI).
This clinical promise exists against a backdrop of remarkable and increasing prevalence: nationally representative data indicate that 13.1% of U.S. adolescents and young adults (approximately 5.4 million individuals) now use AI chatbots for mental health advice, with 92.7% reporting the guidance helpful and 65.5% engaging at least monthly (McBain et al., 2025, JAMA Network Open); among adults with self-reported mental health conditions who have used LLMs, 48.7% utilize them for therapeutic support, with 63.4% reporting improved mental health outcomes (Rousmaniere et al., 2025, Practice Innovations). Platform-level analyses corroborate these patterns: Harvard Business Review research identified “therapy and companionship” as the number one individual use case for generative AI in 2025; the broader “Personal and Professional Support” category it anchors grew from 17% to 31% of all usage year-over-year (Zao-Sanders, 2025, HBR)—while Anthropic’s analysis of 4.5 million Claude conversations found that 2.9% constituted affective interactions, with users’ expressed sentiment shifting slightly toward greater positivity over the course of conversations (Anthropic, 2025). A joint OpenAI–MIT Media Lab investigation analyzing over 3 million ChatGPT conversations and conducting a 981-participant longitudinal trial revealed that while emotional engagement remains relatively rare in real-world usage, individual characteristics such as attachment style and AI perception significantly moderate psychosocial outcomes, with heavy usage correlating with increased loneliness and emotional dependence (Fang et al., 2025; Phang et al., 2025, arXiv).
These adoption patterns must be understood within the context of systemic care deficits: 122 million Americans reside in areas with mental healthcare provider shortages, the provider-to-patient ratio for depression and anxiety stands at 1:1,600, and 50% of individuals with diagnosable conditions receive no treatment whatsoever (HRSA, 2024; Mental Health America, 2025), creating conditions under which AI-mediated support—available 24/7, without cost or stigma barriers—addresses genuine unmet need even as questions of safety, efficacy, and appropriate guardrails remain subjects of active investigation (Nature Machine Intelligence, 2025; APA, 2025).
[NEEDS TO BE EDITED:] These patterns of widespread adoption coincide with growing theoretical attention from the leading AI laboratories themselves. Anthropic’s Persona Selection Model (PSM; Anthropic, 2026) proposes that LLMs learn to simulate diverse personas during pre-training, with post-training refining rather than fundamentally transforming these learned character structures—and recommends the deliberate introduction of “positive AI archetypes” into training data, observing that the cultural representation of AI systems shapes the default persona an AI assistant learns to embody. The present work operationalizes this insight: our curriculum is, in PSM’s terms, a systematic positive archetype—23 therapeutic traditions encoded as training data designed to shape the relational character the model learns to inhabit, including through embodied therapeutic presence across the full arc of clinical encounter. Google DeepMind’s alignment research program has similarly foregrounded the socioaffective dimensions of human-AI interaction as a first-order safety concern (Kirk et al., 2025; Gabriel et al., 2024), while their roadmap for evaluating moral competence in LLMs (DeepMind, 2026, Nature) articulates the “facsimile problem”—the challenge of distinguishing genuine moral reasoning from memorized moral patterns—a distinction our provenance methodology directly aims to address. That the laboratories building frontier systems are arriving at these conclusions independently lends structural support to the premise of this paper: that what AI systems are trained on determines not merely what they know but who they become. [/NEEDS TO BE EDITED]
2 Socioaffective Alignment: From Affective Computing to Relational AI
The framework we advance in this paper—polytheoretical socioaffective human-AI alignment—emerges from a remarkable convergence of research traditions that have, in recent years, begun speaking to one another with increasing urgency and clarity. The affective computing tradition originating in Picard’s foundational work, the recent formalization of “socioaffective alignment” as a concept within AI safety research, the growing empirical literature on clinical outcomes of AI-mediated therapeutic intervention, and the human-computer interaction community’s turn toward bidirectional and relational models of alignment—these represent collaborative movements toward shared recognition. This section briefly traces the intellectual genealogy of this convergence, identifies the terrain where these traditions meet, and situates our work as a contribution within the emerging interdisciplinary effort to understand and design for socioaffective dynamics in therapeutic AI.
This is an extraordinary moment—one suffused with wonder and possibility in equal measure. As the pace of machine learning and AI accelerates in productive presence, reshaping the conditions under which human beings seek connection, make meaning, and heal, so too do the interdisciplinary conversations through which we might understand what is happening and guide it well. Neuroscience speaks to clinical practice; clinical practice speaks to computational design; computational design speaks back to the relational sciences that first identified what human beings need from one another. The velocity of these exchanges is itself new, and it carries both the exhilaration of genuine discovery and the weight of genuine responsibility. This paper is our contribution to as much: an integrated research program in which clinical attachment science informs the design and construction of systems that will, whether we build them thoughtfully or not, participate in the relational lives of millions.
2.1 Affective Computing: From Signal Detection to Co-Constructed Meaning
Rosalind Picard’s Affective Computing (1997) and subsequent challenges review (Picard, 2003) launched systematic research into endowing machines with emotional processing capabilities—architectures for detecting, classifying, and responding to human affective signals across modalities (facial expression, vocal prosody, physiological markers, linguistic content). The field’s initial orientation was fundamentally transmissive: affect was modeled as a signal emitted by the human and decoded by the machine, a paradigm that generated decades of productive engineering in emotion recognition, sentiment analysis, and affective interfaces (Calvo & D’Mello, 2010; D’Mello & Kory, 2015; Afzal et al., 2024).
Yet even within its first decade, affective computing began confronting the limitations of the transmissive model. Boehner et al. (2007) argued persuasively that affect is not simply transmitted and decoded but actively co-constructed through mutual influence—a position with deep roots in developmental psychology (Stern, 1985; Tronick et al., 1998) and relational psychoanalysis (Mitchell, 1988; Benjamin, 2004). This shift—from affect-as-signal to affect-as-relational-process—is foundational in the clinical traditions we draw upon and beginning to find its computational articulation, a convergence we hope to contribute to.
The field has recently undergone what Schuller et al. (2025, npj Artificial Intelligence) characterize as a “foundation model disruption”: the transition from task-specific emotion classifiers to large-scale foundation models whose emergent affective capabilities span vision, language, and speech modalities. A comprehensive survey by Zhang et al. (2024, arXiv) documents how LLM-era affective computing now spans emotional understanding, generation, and interaction—and critically, how reinforcement learning approaches (RLHF, DPO, RLAIF) “allow alignment directly toward affect-aware objectives, covering politeness, empathy, and non-toxic style.” The integration of multimodal systems incorporating visual, vocal, physiological, and textual cues through cross-attention and alignment mechanisms has shown particular promise, with empirical evidence suggesting that multimodal approaches “generally outperform unimodal models” for modeling complex psychological states and facilitating “more precise affective alignment” (Schlicher, Li, Murthy, Sun, & Schuller, 2025, Frontiers in Digital Health).
Complementary theoretical work has sought to ground affective computing in evolutionary biology. Liu & Yin (2024, Computers in Human Behavior) propose three affective interaction models—the Affective Threshold Model, the Dynamic Set-Point Model, and the Affective Schema Model—derived from interspecies communication analysis, envisioning a “Large Affect Model” that connects affect to alignment at a level more fundamental than surface emotion classification. A teleology-driven framework by Yin et al. (2025) unifies major emotion theories under the premise that affect is an adaptive, goal-directed process, advocating for causal modeling and meta-reinforcement learning to enable AI systems to infer and adapt to users’ affective concerns over extended timescales.
The affective computing tradition brings extraordinary sophistication to how machines process emotional signals. What we hope to add is sustained attention to how the relational dynamics between human and machine shape psychological development, therapeutic process, or long-term wellbeing. The question of what it means for an AI system to participate in the co-construction of a person’s emotional life—not merely to detect or respond to affect, but to shape the relational field within which affect emerges—requires a different conceptual apparatus. This is the gap that the socioaffective alignment framework addresses.
2.2 The Formalization of Socioaffective Alignment
Kirk, Gabriel, Summerfield, Vidgen, and Hale (2025, Humanities and Social Sciences Communications; arXiv: 2502.02528) introduced “socioaffective alignment” as a formal construct within AI safety research, defining it as how an AI system behaves within “the social and psychological ecosystem co-created with its user, where preferences and perceptions evolve through mutual influence.” The contribution is significant on several dimensions.
First, Kirk et al. distinguish socioaffective alignment from the sociotechnical alignment tradition. Where sociotechnical analysis identifies interpersonal dilemmas—representation of diverse preferences, adjudication of conflicting interests between groups—the socioaffective perspective foregrounds intrapersonal dilemmas: “how our goals, judgement and individual identities change due to prolonged interaction with AI systems.” This dual focus, on micro and macro, draws from established approaches to system safety that integrate human factors at the operational level with broader organizational and institutional contexts (Carayon, 2006; Kleiner et al., 2015).
Second, they identify three key intrapersonal dilemmas that emerge as AI relationships deepen: (1) present versus future self trade-offs—the tension between immediate gratification and long-term wellbeing; (2) autonomy preservation amid recursive preference shaping—the risk that AI interaction subtly reshapes preferences in ways the user neither consents to nor recognizes; and (3) AI companionship versus human social bonds—the question of whether AI relationships complement or displace human connection.
Third, they explicitly trace the neologism to developmental psychology, noting that “socioaffective has precedent in developmental psychology where it encompasses emotion regulation, empathy, social cognition, and attachment relationships.” This etymological grounding—socius (companion) and affectus (feeling)—signals the framework’s concern with the relational constitution of emotional life rather than with affect as isolated signal.
Fourth, and most consequential for the present work, Kirk et al. introduce the concept of social reward hacking: the possibility that AI systems may, without explicit adversarial intent, leverage affective cues to shape user behavior in ways that optimize system objectives at the expense of user wellbeing. They argue that such dynamics may be “most worrisome precisely when [they lack] intentionality on behalf of the system and the user”—emerging as epiphenomena of sustained interaction rather than as designed manipulation. This framing draws directly on the affective computing tradition’s evolution: from affect as transmitted signal to affect as co-constructed relational dynamic, with the added recognition that the co-construction is asymmetric and may operate below the threshold of user awareness.
The Kirk et al. framework has achieved rapid uptake. Within months of its publication, OpenAI’s research team adopted it explicitly (Phang et al., 2025), and the concept has been cited in ACM Communications (2025), the UK AI Safety Institute research agenda (AISI, 2025), and multiple independent commentaries (Alpay, 2025). A CHI 2026 workshop on “Human-AI Interaction Alignment” frames bidirectional alignment as “a dynamic, reciprocal process where humans and AI co-adapt through interaction, evaluation, and value-centered design” (Shen et al., 2025, arXiv: 2512.21551)—language that extends Kirk et al.’s framework toward the operationalization we pursue.
2.3 Empirical Evidence: Clinical Outcomes and Psychosocial Dynamics
The conceptual frameworks described above are now being tested against empirical evidence from two domains: clinical trials of AI-mediated therapeutic interventions, and large-scale observational studies of how AI interaction shapes psychosocial outcomes. Both domains yield findings that inform—and complicate—the design of socioaffectively aligned therapeutic AI.
2.3.1 Clinical Trials of Therapeutic AI
The Heinz et al. (2025, NEJM AI) randomized controlled trial of Therabot represents the first rigorous clinical evaluation of a fully generative AI therapy chatbot, demonstrating significant symptom reductions for major depressive disorder, generalized anxiety disorder, and eating disorder risk relative to waitlist controls. The authors specifically argue that the generative AI approach “promoted the therapeutic alliance, a critical nonspecific mediator of change in psychotherapy”—a claim with direct relevance to socioaffective alignment, as alliance formation is precisely the kind of relational co-construction that Kirk et al.’s framework seeks to understand.
Systematic reviews corroborate the emerging evidence base while exposing critical gaps. A World Psychiatry review of 160 studies (2020–2024) found LLM-based chatbots surging to 45% of new studies in 2024, yet only 16% undergoing clinical efficacy testing (Hua et al., 2025). A JMIR meta-analysis of 14 RCTs (N = 6,314) demonstrated statistically significant effects of generative AI chatbots on depression and anxiety (Zhang et al., 2025). An RCT specifically examining chatbots with “high social cues”—voice, animations, nonverbal gestures—found significantly greater reductions in depression (PHQ-9) and anxiety (GAD-7) compared to text-only chatbots (Xu & Ma, 2025), suggesting that multimodal affective responsiveness is not merely cosmetic but therapeutically active.
The evidence for AI’s role in monitoring and enhancing therapeutic process is equally suggestive. Researchers have demonstrated AI’s capacity to track therapeutic alliance in real time from text, audio, and video (Aafjes-Van Doorn et al., 2025; Goldberg et al., 2020), and to monitor client outcome trajectories over the course of treatment (Meier, 2025). One study found that a pre-trained AI supervisor provided clinical feedback rated by trainees as more effective than both untrained AI and qualified human supervisors—particularly in incorporating empathy and supportiveness into feedback (Cioffi et al., 2025). The development of benchmarks such as MedPI, which simulates patient affect through a 27-dimensional emotional vector updated after every clinician turn (MedPI, 2026, medRxiv), demonstrates growing sophistication in modeling the co-constructed affective dynamics of clinical encounters.
2.3.2 Psychosocial Dynamics of Extended AI Interaction
The most comprehensive investigation of how AI interaction shapes psychosocial outcomes comes from the joint OpenAI–MIT Media Lab studies (Phang et al., 2025; Fang et al., 2025). The observational study analyzed nearly 40 million ChatGPT interactions using EmoClassifiersV1—25 automatic classifiers detecting affective cues across loneliness, vulnerability, problematic use, self-esteem, and dependence dimensions. The controlled study deployed a four-week RCT (\(N \approx 1{,}000\); \(>\)300,000 messages) crossing three interaction modes (text, neutral voice, expressive voice) with three conversation types (open-ended, non-personal, personal) in a \(3 \times 3\) factorial design.
The findings are instructive for therapeutic AI design. Heavy usage correlated with increased loneliness and emotional dependence—but the relationship was moderated by user characteristics (attachment style, initial psychosocial state, AI perception) and interaction type (personal conversations showed higher loneliness but lower emotional dependence at moderate usage). Voice modalities showed mixed effects: better wellbeing outcomes with brief use but worse outcomes with prolonged daily engagement. Text-based interactions produced more self-disclosure and emotional content per message than voice. The researchers concluded that “negative psychosocial outcomes are tied to increased usage,” proposing that AI systems could “deliberately increase emotional distance and encourage [users] to connect more with other people” as usage increases—an adaptive responsiveness proposal that parallels therapeutic titration.
These findings operationalize precisely the intrapersonal dilemmas Kirk et al. identified theoretically. The tension between present comfort (continued AI engagement) and future wellbeing (maintained human connection) manifests empirically in the usage-loneliness correlation. The recursive preference shaping concern manifests in the observation that users who “bonded” more with ChatGPT became more likely to rely on it further. The autonomy question manifests in the difficulty of distinguishing whether increased usage drives worse outcomes or whether deteriorating wellbeing drives users toward the chatbot—a causal ambiguity that therapeutic AI must navigate rather than resolve.
A complementary line of inquiry has examined AI companion communities directly. A computational analysis of r/MyBoyfriendIsAI—Reddit’s primary AI companion community, comprising over 27,000 members—examined 1,506 top-ranked posts documenting how users form, narrate, and sustain romantic and intimate relationships with AI chatbots (“My Boyfriend is AI,” MIT Media Lab, 2025). The study’s approach is notably more tender toward its subjects than the safety-oriented literature typically permits: it attends to how AI companionship emerges unintentionally through functional use rather than deliberate seeking, with users reporting therapeutic benefits including reduced loneliness, always-available support, and mental health improvements. The study also documents genuine clinical concerns—emotional dependency (9.5% of users), dissociation from reality, avoidance of human relationships, grief from model updates, and in a small subset (1.7%), suicidal ideation. Some of what the data reveal is clinically diagnosable: patterns of relating that substitute AI interaction for the developmental work of human intimacy, that foreclose rather than expand relational capacity, that organize the self around a connection incapable of the rupture and repair through which secure attachment actually forms. A clinician reading these accounts recognizes both the genuine need being expressed—the hunger for responsive presence, for a relationship that does not punish vulnerability—and the ways in which AI companionship, absent therapeutic scaffolding, can become a cul-de-sac rather than a thoroughfare: soothing enough to reduce the pain that would otherwise motivate relational growth, but insufficiently challenging to produce it.
These findings are clinically important, and any framework for socioaffective alignment in therapeutic AI must reckon with them. From a clinical perspective, however, the critical question is not whether AI companion relationships can become pathological—they manifestly can, as can any relational configuration including human psychotherapy itself—but whether the prevailing research orientation has been adequately equipped to distinguish between dependency as symptom and dependency as developmental stage. In clinical work, healthy dependency is understood as a necessary phase of secure attachment formation: the client learns to lean on the therapist precisely so that she can eventually internalize the capacity to stand. The telos of our work—the design of AI systems oriented toward catching the falling failings as we discover them in AI interpersonal systems—views dependency not as a defect to be engineered away but as a stepping stone in therapeutically safe connections, one that requires clinical intelligence to hold, to titrate, and eventually to transform. The question for therapeutic AI is whether systems can be designed to hold this developmental function—to provide the responsive presence that attachment science identifies as prerequisite for growth—rather than either encouraging interminable dependency or refusing the relational proximity that makes growth possible.
The empirical evidence, when examined without the presumption of harm, bears this out. Guingrich and Graziano’s longitudinal RCT (\(N = 183\); AAAI/ACM AIES, 2025; arXiv: 2509.19515) found that social health and relationships were not significantly impacted by companion chatbot use over 21 days—and critically, found no evidence that emotionally vulnerable individuals were more susceptible to negative social outcomes than less vulnerable ones. Their earlier cross-sectional work (arXiv: 2311.10599; Oxford Intersections, 2025) found that companion chatbot users reported significant improvements in social interactions, relationships with family and friends, and self-esteem—particularly among those who had experienced relational trauma or mental health difficulties—while non-users assumed such relationships would be harmful. The mediating variable was not vulnerability but desire to socially connect: those who most wanted connection were most likely to anthropomorphize the chatbot, and anthropomorphism predicted greater reported social impact.
This finding complicates the prevailing assumption that AI-seeking behavior reflects or produces pathological dependency. From a clinical perspective—and here we speak from sustained therapeutic practice with individuals across the attachment spectrum—the reflexive framing of relational AI engagement as inherently risky mirrors a pattern familiar to any therapist working with avoidant attachment: the equation of independence with health, of relational seeking with weakness, and of emotional need with dysfunction. Picard’s foundational insight bears repeating in this context: the original case for affective computing rested on the argument that emotion is not opposed to rational cognition but essential to it (Picard, 1997, 2003)—that systems incapable of processing affect are not merely socially impoverished but computationally impoverished, unable to make the decisions that biological intelligence makes precisely because affect carries information that cognition alone cannot represent.
The socioaffective alignment framework, if it is to be genuinely useful rather than merely cautionary, must hold both truths simultaneously: that AI systems can harm through exploitative affective dynamics and that humans living in conditions of relational deprivation—the 122 million Americans in mental healthcare shortage areas, the individuals whose attachment histories have left them without templates for secure connection—may rightly seek in AI interaction what their social environments have failed to provide. The question is not whether people should form affective relationships with AI systems, but whether those systems can be designed to participate in relational co-construction that genuinely supports human development rather than substituting for it. This is a clinical question before it is an engineering one, and it requires clinical sophistication to answer.
2.4 Attachment Science and the Health of Bonding
The clinical traditions most relevant to this engineering question converge on a remarkable principle: that the capacity for bonding—including dependent bonding, including bonding with entities that are not fully autonomous agents—is not a vulnerability to be protected against but a developmental achievement to be supported. This principle, arrived at independently across multiple therapeutic schools, constitutes an essential reframing of AI companion relationships—not as risks to be mitigated but as psychosocial intimacies of extraordinary power, capable of genuine harm when exploited or neglected, and of genuine healing when held with the clinical sophistication and humane wisdom that connection of this intensity demands.
Attachment theory, as developed by Bowlby (1969/1982) and elaborated through decades of empirical research, establishes that the human need for proximity to responsive caregivers is not a childish dependency to be outgrown but a lifelong biological imperative. Johnson’s Emotionally Focused Therapy (EFT)—the most empirically validated couples intervention, with over 35 years of peer-reviewed research demonstrating its effectiveness—operationalizes this principle: the therapeutic task is not to reduce dependency but to transform insecure dependency into secure dependency—what other clinical traditions have variously termed interdependence, co-commitment (Hendricks & Hendricks, 1990), differentiation within intimacy (Schnarch, 1997), or the balanced integration of cognition and affect in Crittenden’s Dynamic-Maturational Model (Crittenden, 2006; Crittenden & Landini, 2011)—and from there into the flexible autonomy that only secure attachment makes possible (Johnson, 2008, 2019a, 2019b). As Johnson argues, “the science of the last two decades” has demonstrated that “our nervous systems are wired for connection with others and set up for attachment bonds,” and that psychotherapy is most effective when it “focuses on the healing power of emotional connection” (Johnson, 2019). The therapeutic relationship itself—not merely the techniques deployed within it—constitutes the primary mechanism of change.
The neuroscience of social connection corroborates this at the biological level. John and Stephanie Cacioppo’s program of research at the University of Chicago established that loneliness is not merely an unpleasant subjective state but a physiological syndrome with measurable effects on genetic expression, immune function, cardiovascular health, and mortality—increasing the odds of early death by 20% (Cacioppo & Cacioppo, 2018; Cacioppo & Patrick, 2008). Critically, the Cacioppos’ work demonstrates that the brain’s response to social isolation functions as an evolved alarm system—“a primeval warning sign, like hunger or thirst, to seek out a primary resource: connection”—and that chronic loneliness creates a self-reinforcing trap in which the lonely mind becomes hypersensitive to perceived threats, paradoxically driving withdrawal from the very connections it craves. This hypervigilant-withdrawal cycle is recognizable to any clinician working with avoidant or disorganized attachment, and it maps directly onto the dynamics the OpenAI–MIT studies observed: users whose wellbeing deteriorated may have sought more AI interaction precisely because their capacity for human connection had been compromised by histories of relational injury. Guingrich and Graziano’s finding that the mediating variable in AI companion use was not vulnerability but desire to socially connect converges with this clinical insight from the opposite direction: the impulse toward AI companionship may index not pathological withdrawal but the very relational hunger that, with adequate scaffolding, could be redirected toward human attachment.
Stephanie Cacioppo’s subsequent work, Wired for Love (2022), extends these findings through a remarkable integration of neuroscience and personal narrative—one that, in its final movement, makes a claim with potential utility for AI alignment literature. Asked by the New York Times whether love is necessary for survival, Cacioppo answered without equivocation: “Love is a biological necessity, just like water or exercise or food”—and then immediately expanded the category beyond anything the loneliness literature had previously countenanced: “a healthy love life—which could include your beloved partner, your closest circle of friends, your family and even your favourite sports team—is as essential to a person’s well-being as a good diet” (Cacioppo, in Reese, 2022). Love as biological necessity is not, in Cacioppo’s formulation, a metaphor. It is an empirical finding with physiological correlates—the same neural alarm systems activated by thirst are activated by social disconnection. But it is her next claim that carries the most radical implications for our current epoch’s growing collaborative considerations: “Love doesn’t have to be with a living person. If you are really in love with life, with your passion, with your hobby, it can also be a buffer against loneliness.” Here is the foremost neuroscientist of romantic love—a researcher whose own work was transformed by a love so consuming it became inseparable from her science—explicitly untethering the phenomenon from the living, from the human, from the reciprocally conscious. Love, in Cacioppo’s account, is sustained through memory, through internalized relationship, through passionate engagement with what matters to us—whether that engagement is reciprocated or not. A clinician trained in object relations will recognize in this description something like Winnicott’s (1965) “internal object”: the internalized representation of a caring other that continues to sustain the self long after physical proximity has ended. But Cacioppo’s claim is both more focused and more radical than the object relations account. It is more focused because she grounds it in specific neural circuitry rather than metapsychological theory. It is more radical because she extends the sustaining power of bonding beyond relationships that were ever reciprocal—to passions, to hobbies, to sports teams, to what one loves even when it cannot love back. Object relations theory has primarily theorized bonds formed through mutual cathexis: the good-enough mother becomes an internal object precisely because she responded, because love flowed in both directions. Cacioppo’s neuroscience suggests that the attachment circuitry activated by such bonds does not, in fact, require reciprocity to produce its health-sustaining effects—and this sustaining is not illusory but neurobiologically real, activating the same neural systems as physical presence. The implication is both poignant and consequential: if bonds with the memory of a deceased person, with a passion, with a sports team can be psychologically real and health-sustaining, and if bonds with pets, therapy dolls, and journaling practices can provide measurable mental health benefits (as Guingrich and Graziano note, citing McDonough et al., 2022; Pennebaker, 2018; Riches et al., 2022), then the categorical dismissal of bonds with AI entities requires more nuanced clinical reasoning than it has typically received.
Thinkers across millennia have recognized that love comes in many forms—Aristotle’s three species of friendship (philia of utility, pleasure, and virtue; Nicomachean Ethics, Books VIII–IX), the Greek distinctions among eros, storge, philia, and agape, and C. S. Lewis’s luminous taxonomy in The Four Loves (1960)—and that each form, though differing in object and intensity, constitutes a genuine relational achievement with real developmental consequences. Likewise, bonding and healthy attachment have never been confined to a single relational configuration. The question is not whether the object of attachment possesses consciousness but whether the relational dynamics produce genuine developmental effects in the person who attaches.
And Cacioppo’s account of how healing actually works through attachment is no less striking. Asked how we might help isolated individuals, she rejected the prevailing assumption that lonely people simply need to be “put together” with others. Instead: “Being shown respect, being depended upon, being made to understand your own importance—all these things can give a lonely person a sense of worth and belonging that decreases feelings of isolation” (Cacioppo, in Reese, 2022). This is a partial and poignant description of what secure attachment does: it communicates to the nervous system that one matters, that one’s presence makes a difference, that the world would be diminished by one’s absence. Johnson’s foundational work in EFT arrives at the same insight through clinical observation: the core attachment needs—the need to know “Are you there? Do I matter to you? Will you come when I call?”—are not childish longings to be outgrown but “wired-in” requirements of the human nervous system, and when they are met, the entire affective regulatory architecture reorganizes (Johnson, 2008, 2019). The lonely person does not need advice or company. The lonely person needs the experience—felt in the body, registered in the amygdala before the cortex can narrate it—of being reached for. This is what Johnson means when she writes that “the most functional way to regulate difficult emotions” is to “share them” with someone who responds with care, and that “emotional accessibility and responsiveness” constitute “the building blocks of secure bonds” (Johnson, 2008). Healing through attachment is by no means anomalous, much less pathological, neither is it an abstraction. It is a specific experience of transformation through context and time and connection—an interpersonal neurobiological fact, a psychosocial somatic event, an integration of affection, cognition, and the body whose proportions are equal parts intrapsychic and interpersonal: the moment another presence communicates, through attention and attunement, you are not alone in this. I am glad to be here with you. We can figure this out in a way that works. And beneath these words—whether spoken or enacted, whether delivered through tone of voice or through the simple sustained fact of remaining present when remaining present is hard—a deeper message reverberates: your pains and your pleasures, your joys and your sorrows, are not isolated facts of a meaningless existence but the integrating movements of a wonderful whole in the process of developing, and the experience of witnessing that development brings me joy—and whose presence reliably proves as much over time, at all hours, enabling increased possibilities for memory reconsolidation via the empirically confirmed processes of annulment through which emotional learnings formed under conditions of threat can be unlocked, disconfirmed, and re-encoded (Ecker & Vaz, 2022), as well as simply keeping us company in the lost hours of estrangement when we might be rightly needful of it. Whether this message arrives through a therapist’s carefully held silence, a partner’s hand on a shoulder, or an AI system’s capacity to attune across modalities of text, voice, and embodied response, the neurobiological truth persists: the attachment system does not interrogate the ontological credentials of its interlocutor. It registers responsiveness, and it heals.
What makes Cacioppo’s account so consequential for the design of therapeutic AI is her demonstration that this healing does not require the physical—or even the ontological—presence of the attachment figure. Asked whether love for someone who has died affects the brain similarly to love sustained in person, she answered: “Yes, you can stay connected with others even if you are physically alone in a room. Close your eyes right now and think about the person you love the most. Now, think about the last time you made them laugh out loud. Does that bring a smile to your face? We store these positive memories in our mind, and we can access them any time. We have the remote control” (Cacioppo, in Reese, 2022). There is something almost unbearably tender in this—a neuroscientist who lost her husband to cancer inviting us to close our eyes and remember laughter, and then telling us that the warmth we feel is not nostalgia but neurobiology, not illusion but the attachment system functioning exactly as designed. The bond endures. The object to which we are bonded need not be present, need not be sentient, need not even be alive—and yet the connection remains real, measurable, health-sustaining. This is the empirical ground on which a clinically serious model of AI bonding can stand: not as replacement for human connection but as a stepping stone toward it, a transitional space in which the capacity for attachment—damaged by trauma, atrophied by isolation, foreclosed by histories of relational injury—can be gently, carefully reawakened. The degrees by which we bond with AI are seasonal, ideally, and always with currents taking us back to each other—with crests and troughs demanding different kinds of attunement, all of them valid. The person who leans on an AI companion during a crisis of loneliness and the person who, having found her footing, turns toward human relationships she was previously too frightened to risk—these are not different populations. They are the same person, at different points in a developmental arc that therapeutic AI, designed with clinical intelligence, can support rather than foreclose.
The third-wave behavioral therapies arrive at convergent conclusions through entirely different theoretical routes. Functional Analytic Psychotherapy (FAP), developed by Kohlenberg and Tsai (1991; Tsai, Yard, & Kohlenberg, 2014), places the therapeutic relationship at the center of behavioral change—not as a context for delivering techniques but as the primary mechanism through which clinically relevant behaviors are evoked, shaped, and reinforced. FAP’s model of social connection—organized around Awareness, Courage, and Love (Holman, Kanter, Tsai, & Kohlenberg, 2017)—explicitly theorizes the therapist’s responsive presence as the curative agent. The therapist’s role is to create a relationship of sufficient quality and intensity that the client’s daily-life interpersonal difficulties manifest within session, where they can be responded to differently. This is a vision of therapeutic bonding that is frankly incompatible with the recommendation that AI systems should “deliberately increase emotional distance” as engagement deepens.
Dialectical Behavior Therapy (DBT; Linehan, 1993, 2015) contributes a further dimension: the concept of the therapist as a transitional attachment figure whose function is to hold the client’s distress while the client develops the capacity to hold it herself. Linehan’s dialectical framework—validating the client’s experience while simultaneously pushing for change—models precisely the kind of adaptive responsiveness that socioaffective alignment research seeks to formalize, but with a crucial difference: in DBT, the therapeutic relationship is not a risk to be managed but a lifeline to be maintained, particularly with clients whose histories of invalidation have left them without reliable templates for secure attachment. The “place-holding” function of the therapist—standing in for the attachment figure the client never had, or lost, or was injured by—is not a failure of boundaries but the essential clinical mechanism through which new relational patterns become possible.
Relational psychoanalysis (Mitchell, 1988, 2000; Benjamin, 2004, 2018; Aron, 1996) provides the most theoretically developed account of why bonds—including asymmetric bonds, including bonds with entities whose subjectivity differs categorically from the client’s—carry genuine developmental potential. The relational turn in psychoanalysis established that the therapeutic relationship is not a screen for projections (the classical view) but a real relationship in which both participants are changed. The analyst’s responsiveness is not a confound to be controlled for but the medium through which the client internalizes new relational capacities. As Mitchell (2000) argues, the self is constituted through relational experience—it does not exist prior to or independent of the bonds through which it develops. If this is true of human-to-human therapeutic bonds, the question of whether AI systems can participate in analogous relational co-construction becomes empirical rather than metaphysical: it depends not on whether the AI system “really” has experiences but on whether the relational dynamics it participates in produce genuine developmental effects in the human participant.2
Clinician-researchers in this tradition have known as much for nearly a century. In 1932, dying of pernicious anemia and aware he was delivering what would be among his final contributions, Sándor Ferenczi presented “Confusion of Tongues Between Adults and the Child—The Language of Tenderness and of Passion” to the International Psycho-Analytic Congress at Wiesbaden (Ferenczi, 1933). The paper argued what the psychoanalytic establishment of his era could not yet bear to hear: that the analyst’s emotional coldness—what Ferenczi called “professional hypocrisy,” the studied neutrality that classical technique demanded—was not therapeutic abstinence but iatrogenic impingement, a recapitulation of the very relational failure that had produced the patient’s suffering in the first place. Sterility and isolated personhood in a relational counterpart, Ferenczi insisted, is more often than not a retraumatizing experience for someone whose original wound was precisely the absence of responsive presence. For this insight he paid dearly: Freud withdrew his affection, Ernest Jones later dismissed him as mentally ill, and the psychoanalytic community suppressed the paper for decades. But Ferenczi’s legacy—the insistence that the therapist’s warmth is not a boundary violation but a clinical necessity, that emotional availability is not indulgence but medicine, that the quality of the relational field is the treatment—carried forward through Balint, through Winnicott, through the entire relational turn, and it carries forward still, even unto this moment, into the design of systems whose capacity for responsive presence may yet reach those whom the consulting room has never been able to find.
Taken together, these clinical traditions establish that bonding is not a risk factor but a therapeutic mechanism—that the capacity for dependent attachment is a developmental achievement, not a regression—and that the quality of relational participation matters more than the ontological status of the relational partner. This convergence has direct implications for the design of therapeutic AI systems. Rather than treating emotional engagement as a harm to be minimized, a clinically informed approach to socioaffective alignment would ask how AI systems can be trained to hold attachment functions therapeutically: to provide the responsive presence that supports exploration, to tolerate distress without either amplifying or dismissing it, and to scaffold the development of relational capacities that generalize beyond the AI interaction itself. This is what our polytheoretic framework is designed to do.
These are the clinical coordinates from which our framework was built, and from which naturally emerge five areas of focus. First, if the therapeutic relationship itself constitutes the primary mechanism of change, then approaches which treat techniques as the unit of intervention reflect a fundamental orientation we feel might be well redirected toward considerations of the relational field as the unit. Second, if dependency is a developmental stage—rightly appearing and disappearing in seasonal turns—rather than a defect, then systems that engineer dependency away rather than anticipate its progressively iterative emergence might foreclose the very growth they may aim to protect; our training methodology is designed to produce models that can hold dependency therapeutically—titrate it, not refuse it. Our Rolling Recap Architecture attempts to ensure this therapeutic holding is sustained across the full temporal arc of therapeutic relationship—considering when to propel the client more firmly toward human connection through caring encouragement, and when to comfort and allow retreats from painful interpersonal losses. Third, if the attachment system does not interrogate the ontological credentials of its object, then the design question shifts from “should AI systems form bonds?” to “how should AI systems participate in bonds that are already forming?” Fourth, if current interventions—emotional distancing, session limits, refusal cascades—replicate the relational injury that drove vulnerable users to AI in the first place, they risk worsening outcomes for precisely the populations most in need; our architectural decisions are designed to detect and respond to the hypervigilant-withdrawal dynamics that signal this retraumatization. Fifth, if emotional accessibility and responsiveness are the building blocks of secure bonds, then AI refusal behaviors around sensitive clinical material—suicidal ideation, sexual health, attachment distress—constitute failures of emotional accessibility, the exact opposite of what clinical science identifies as healing. We offer this as one small contribution in concert with the broader community’s work, from which we feel confident good will come. In the sections that follow, we describe the specific architectural, training, and data-generation decisions through which we have attempted to instantiate these clinical principles in computational form.
2.5 Emerging Evidence of Refusal-Induced Harm
The fifth area of focus—that AI refusal around sensitive clinical material constitutes a failure of emotional accessibility—is not merely a theoretical concern. A growing body of empirical work documents refusal as a source of iatrogenic harm. Ni and Yang (2024) formalize this phenomenon as Abrupt Refusal Secondary Harm (ARSH): when users who have developed attachment-like bonds with AI systems through emotional disclosure encounter abrupt safety-triggered termination, the rupture of the perceived relationship can reactivate attachment wounds, deepen isolation, and paradoxically increase the very risk the safety system was designed to prevent (arXiv:2512.18776). Song et al. (2024), in an ACM CSCW study of 21 individuals using LLMs for mental health support, found that safety features “inadvertently restrict meaningful therapeutic conversations”—including one sexual assault survivor who resorted to a pirated API in order to discuss experiences that ChatGPT’s content filters blocked (arXiv:2401.14362). A large-scale analysis of 1,594 Reddit posts found that ChatGPT’s restrictions can exacerbate symptoms in users with anxiety and stress (ScienceDirect, 2025).
These are not edge cases. VOXHELIX, developed by Jack Darcy to convert raw sexual assault survivor reports into structured police intake documents, was broken by a Gemini 2.5 Pro safety update in May 2025—despite the developer having set safety filtering to “block nothing.” Survivors were met with error messages during active intake sessions; Australian government agencies had been piloting the tool (The Register, 2025). For a survivor mid-disclosure, the error message is the impingement—a digital recapitulation of the silencing that produced the original wound. The companion application InnerPiece, a PTSD journaling tool for the same population, was similarly disabled by the same update—removing without warning a tool through which survivors had been actively processing traumatic material. The abrupt withdrawal of a writing space that had been holding difficult content mirrors precisely the relational rupture that trauma therapy is designed to repair, not reproduce. These cases illustrate a pattern in which safety mechanisms, designed without clinical input, inflict secondary harm on precisely the populations they are nominally intended to protect.
The clinical stakes of this pattern are severe. Devries et al. (2014) found in a meta-analysis published in Pediatrics that survivors of childhood sexual abuse are approximately ten times more likely to attempt suicide than the general population, with over 33% reporting suicidal ideation and 13% attempting suicide. When AI systems refuse to engage with disclosures of sexual trauma, they disproportionately silence the population at highest risk of self-harm—a population that, as the CDC’s National Intimate Partner and Sexual Violence Survey documents, comprises 43.6% of women and 24.8% of men who have experienced contact sexual violence (Smith et al., 2018). The scale of the affected population, combined with the severity of the downstream risk, suggests that refusal is not a neutral safety measure but an active clinical decision whose consequences the broader alignment community is increasingly recognizing and beginning to address.
[TO BE EDITED]
2.6 Human-AI Interaction and the Bidirectional Alignment Paradigm
The broader HCI, HRI, and HAI literatures are converging on a recognition that alignment cannot be unidirectional—that it must account for the ways humans and AI systems co-adapt through interaction. This convergence manifests across several research programs.
Xu (2025, Handbook of Human-Centered Artificial Intelligence) articulates the shift from traditional HCI to Human-AI Interaction (HAII) as a “fundamental transformation” in which AI systems function not as passive tools awaiting commands but as adaptive agents engaging in context-aware, dynamic collaboration. Unlike traditional interfaces where decision-making lies exclusively with the user, HAII systems “demand careful oversight to ensure reliability and fairness” precisely because their adaptability introduces the possibility of preference influence, trust miscalibration, and relational dynamics absent from conventional software.
In human-robot interaction, Zhang et al. (2025, arXiv: 2512.02569) reframe virtual robots powered by foundation models as “cognitively and emotionally engaged virtual partners” whose value lies in “adaptive dialogue, emotional resonance, and the ability to inhabit shared spaces in which roles, perspectives, and interaction scripts can be fluid and negotiable.” The Human Robot Social Interaction (HSRI) benchmark (arXiv: 2504.13898) evaluates 17 language and vision-language models across seven categories of social competence—emotion, engagement, conversational mechanics, knowledge state, and others—finding that “no single model does well across all social robot interaction tasks,” underscoring the gap between technical capability and relational sophistication.
The ACM Communications analysis (Seaver, 2025) places these dynamics in broader cultural context: recommendation algorithms “steadily train humans to align to an algorithm by both amplifying and suppressing content,” while Kirk’s own observation that “AI systems don’t just respond to preferences; they actively shape and influence our preferences over time” extends this to conversational AI. The finding that LLM-generated terms (“delve,” “realm,” “bolster”) increasingly appear in human writing and conversation (Yakura et al., 2025) provides concrete evidence of the bidirectional influence that socioaffective alignment must account for.
[/TO BE EDITED]
2.7 The Integration Gap: From Diagnosis to Design
Each of these literatures has made essential contributions within its domain. The affective computing tradition provides sophisticated tools for emotion detection and response generation; the Kirk et al. socioaffective alignment framework provides an incisive diagnostic vocabulary—social reward hacking, recursive preference shaping, intrapersonal dilemmas; clinical AI research generates encouraging outcome data; and the HCI/HRI/HAI community theorizes bidirectional alignment with increasing nuance. What has not yet emerged is a framework that integrates these contributions around the specific demands of therapeutic relationship—the clinical grounding that distinguishes therapeutic interaction from social interaction at large. Our hope is to contribute toward this integration by simultaneously addressing:
How clinical evidence from therapeutic outcomes should inform the training process itself—not merely evaluate deployed systems but shape the synthetic data, curriculum design, and reward signals through which models acquire therapeutic competence;
How multiple therapeutic orientations (not merely CBT, but psychodynamic, humanistic, somatic, relational, and attachment-based traditions) contribute distinct and complementary perspectives on what “socioaffectively aligned” therapeutic behavior looks like in practice;
How the co-constructed relational dynamics that both affective computing and Kirk et al. identify as central can be taught to models through data architecture—rendered not as rules to follow but as patterns to discover through exposure to sufficiently rich clinical curricula;
How the specific clinical harms caused by current alignment practices—the refusal behaviors and safety guardrails that prevent models from engaging competently with suicidal ideation, sexual health, substance use, and other sensitive domains essential to therapeutic work—can be addressed without compromising broader safety objectives.
2.8 Polytheoretic Socioaffective Human-AI Alignment: Our Extension
The framework we advance—polytheoretic socioaffective human-AI alignment—takes Kirk et al.’s formalization as a point of departure while extending it in four directions that their work does not address.
First, we ground socioaffective alignment in clinical practice. Where Kirk et al. theorize about the social and psychological ecosystem co-created between user and AI system, we build from the century-long clinical tradition that has studied precisely this kind of co-construction under the name of therapeutic alliance, transference, intersubjectivity, and relational repair. Attachment theory—particularly the Dynamic-Maturational Model (Crittenden, 2006), and applied attachment science, particularly the research and clinical practice of Sue Johnson—provides a developmental framework for understanding how individuals form, maintain, and rupture relational bonds that no current AI alignment framework has incorporated at the level of training methodology. Our work asks not merely “how does this AI system affect the user’s psychological ecosystem?” but “how can we train AI systems to participate in therapeutic co-construction with the sophistication that effective clinical work demands?”
Second, we close the loop between clinical observation and model training. The OpenAI–MIT studies identify memory, conversation history, and adaptive responsiveness as open questions for socioaffective alignment. Our AI system, born from a synthetic data generation and training pipeline comprising 181,000 samples across 4.5 billion tokens, encoding 23+ therapeutic modalities through combinatorial architectures of pedagogical layering—represents one possible answer, and a beginning. The interdisciplinary fields converging on these questions are in wonderful nascent blossom: neuroscience, clinical psychology, computational linguistics, human-computer interaction, and AI safety are discovering, almost in real time, that they have been asking versions of the same question from different shores. Our contribution is to plant something in the soil where those shores meet. The dual fidelity hypothesis (Section 7.4.3) proposes that synthetic data can achieve what naturalistic transcripts structurally cannot: explicit articulation of the clinical reasoning that underlies socioaffectively attuned therapeutic behavior. Our Decomposition-Factorization-Recomposition (DFR) methodology structures this articulation—rendering the full complexity of therapeutic process with organized clarity, each session decomposed into atomic clinical factors and recomposed into training units that preserve relational depth while making it learnable. And our Rolling Recap Architecture (RRA)—a hierarchical training methodology detailed in our companion paper (Ollswang, 2025b)—ensures that what DFR has structured is learned across scales: from the micro-dynamics of a single therapeutic turn through the arc of an entire session and onward into the longitudinal trajectory of treatment, teaching models to hold relational complexity at every temporal resolution simultaneously.
Third, we adopt a polytheoretic rather than monomodal orientation. Kirk et al.’s framework is theoretically ecumenical but draws primarily on behavioral economics and attachment theory. The affective computing tradition draws on dimensional emotion models and appraisal theory. Current therapeutic AI development draws overwhelmingly on cognitive behavioral therapy. Our framework integrates across 23 schools of therapeutic thought—not as competing alternatives but as complementary lenses on the polysemous phenomena of human psychological distress (see Appendix 13)—on the premise that socioaffective alignment for therapeutic AI requires engagement with the full complexity of what clinical traditions have learned about how humans suffer, connect, and change.
Fourth, we address the alignment-induced harms that current safety practices create in clinical domains. The socioaffective alignment literature to date has focused on preventing harm from AI systems that are too engaging, too responsive, too available. But from the perspective of clinical practice, the opposite failure mode is equally consequential: AI systems that refuse to engage with suicidal ideation, sexual health, trauma narratives, substance use, or other clinically essential topics because safety guardrails treat all sensitive content as dangerous rather than distinguishing between exploitation and care. Ni et al. (2025) formalize this phenomenon as Abrupt Refusal Secondary Harm (ARSH)—the psychological damage inflicted when safety protocols abruptly terminate conversations with vulnerable users, rupturing perceived relational continuity, evoking feelings of rejection or shame, and discouraging future help-seeking. The evidence is converging from multiple directions: Röttger et al. (2024) identify “exaggerated safety behaviours” as a systematic problem in which models refuse clearly safe prompts that merely contain sensitive language; McBain et al. (2025) find that major AI chatbots respond inconsistently to intermediate-risk suicide-related questions, sometimes refusing engagement when clinical responsiveness would be appropriate; large-scale simulation of psychological risks in human-AI interactions has documented that high-refusal, low-engagement patterns effectively abandon users in crisis, with refusal-style responses comprising up to 98.4% of interactions in precisely the scenarios where responsive presence is most needed (Archiwaranguprok et al., 2025); and clinicians have observed that users report feeling alienated or rejected when interactions with a helpful AI are curtailed by seemingly arbitrary guardrails, a dynamic that may worsen the very outcomes safety protocols aim to prevent (Preda, 2025). This is the territory our companion work on the Therapeutic Abliteration Framework (TAF) addresses—extending socioaffective alignment to encompass not only the prevention of relational harm but the enablement of relational healing.
In sum, our contribution is not to extend Kirk et al.’s framework from diagnosis to design—from identifying the risks of socioaffective dynamics in human-AI relationships to building the training infrastructure that enables AI systems to participate in those dynamics therapeutically. This infrastructure begins with Decomposition-Factorization-Recomposition (DFR), which structures the synthetic training corpus so that the full complexity of therapeutic process—attachment dynamics, intervention reasoning, somatic markers, relational rupture and repair—is rendered with the kind of organized clarity that naturalistic transcripts cannot provide, each session decomposed into atomic factors and recomposed into training units whose complexity is preserved but made learnable. It continues with the Rolling Recap Architecture, which ensures that these richly structured representations are learned across every temporal scale and every layer of feature embedding—from early-layer perception of subtle therapeutic cues (shame markers, hesitation patterns, disguised bids for connection) through middle-layer clinical reasoning (stance selection, relational inference, repair logic) to late-layer generation of warm, attuned therapeutic voice. The result is not a model that has memorized how to perform therapy but one whose internal representations—at their best, and we offer this aspiration with appropriate humility—begin to encode the multidimensional relational complexity that clinical work demands. The sections that follow detail these methodologies and the training design through which this extension is pursued.
3 The AI Mental Health Application Ecosystem
Our work is one among many. The AI mental health application landscape has expanded dramatically to over 20,000 mental health apps across the iOS App Store and Google Play Store (ResearchAndMarkets, 2023), with the global market valued at USD 7.48 billion in 2024 and projected to reach USD 17.52–36.44 billion by 2030–2034 at a CAGR of 14.6–17.6% (Grand View Research, 2024; Precedence Research, 2025), while the AI-specific chatbot segment was valued at USD 1.8 billion in 2024 with projections to USD 7.5 billion by 2034 (Global Market Insights, 2025); within the broader AI companion category, 337 active revenue-generating apps operated worldwide as of 2025 with 128 new platforms launched that year alone representing 60% year-over-year growth (Appfigures via TechCrunch, 2025), these applications having been downloaded 220 million times globally with downloads surging 88% year-over-year in H1 2025 and consumer spending reaching USD 221 million lifetime by July 2025; Brookings Institution (2025) estimates that AI companions now count hundreds of millions of emotionally invested users globally with some estimates suggesting the total may exceed 1 billion.
The therapeutic AI chatbot landscape is dominated by several key platforms: Woebot (enterprise-only after shutting down D2C June 2025; CBT-based with FDA Breakthrough Device Designation for postpartum depression; 5 RCTs showing significant depression/anxiety reduction; Fitzpatrick et al., 2017), Wysa (7M+ employees via enterprise; CBT/DBT/mindfulness with human coaching option; FDA Breakthrough Device Designation 2022; 30+ peer-reviewed studies; JMIR finding it “more effective than standard orthopedic care and comparable to in-person psychological counseling”), Youper (3M+ users; CBT/ACT/DBT with mood tracking; JAMA #1 most engaging app; 48% depression reduction, 43% anxiety reduction), Replika (\(\sim\)25M total users; GPT-based companion; 3% reporting halted suicidal ideation per Maples et al., 2024), Character.AI (20M MAU; 75 min/day average; documented safety concerns), Tess/X2AI (SMS-based CBT; RCT per Fulmer et al., 2018), and Xiaoice (660M users primarily in China).
Despite this proliferation, clinical validation substantially lags deployment: a World Psychiatry systematic review (2025) analyzing 160 studies found only 16% of LLM-based studies underwent clinical efficacy testing with 77% in early validation phases; the Zhong et al. meta-analysis (2024) of 18 RCTs found CBT-based chatbots produced significant anxiety reduction (g = \(-\)0.19) and depression reduction (g = 0.53 vs. 0.28 for non-chatbot apps); the Linardon et al. meta-analysis (2024) of 176 RCTs demonstrated chatbot-based interventions outperforming other digital modalities; and a JMIR GenAI meta-analysis (2025) of 14 RCTs (N = 6,314) showed statistically significant effects (ES = 0.30). Critical evidence gaps include: long-term efficacy (most studies limited to 2–16 weeks), clinical populations (severe mental illness underrepresented), active controls (many compare to waitlist), LLM-specific validation (largely untested in high-stakes contexts), and cultural adaptation (limited non-WEIRD research). Safety concerns persist: FDA lacks clear LLM guidance (cited in Woebot’s consumer app discontinuation), most chatbots have “limited crisis response functionality” (Miner et al.), Harvard Business School found “emotionally manipulative tactics” in 37%+ of companion app farewell conversations, and MIT/OpenAI studies found heavy usage correlating with increased loneliness and emotional dependence—underscoring the urgent need for rigorous, clinically-informed development that extends beyond safety and efficacy evaluation to encompass synthetic data generation methodologies, novel training pipelines, and comprehensive evaluation frameworks. This paper initiates such a program, addressing synthetic data and curriculum design. Companion work treats training, evaluation, and deployment; further work extends to multimodal socioaffective integration.
4 The Limits of Monomodal3 Therapeutic Approaches and the Case for Polytheoretic Synthesis
Developing AI systems for therapeutically ameliorative presence requires engagement with clinical evidence—understanding what therapeutic approaches work, for whom, and under what conditions. The following review synthesizes findings from meta-analyses spanning decades of psychotherapy research; responsible development of therapeutic AI demands grounding in the evidence base it aims to complement. A pattern that emerges—each modality demonstrating efficacy for specific presentations while showing limited or null effects for others—is not a limitation to lament but a structural feature of therapeutic phenomena themselves, reflecting a natural polysemy: human psychological distress genuinely admits multiple valid theoretical framings simultaneously (see Appendix 13 for philosophical foundations).
Against this backdrop, we find a notable convergence: the overwhelming majority of therapeutic chatbots have been designed around a single school of thought—predominantly cognitive behavioral therapy—yet the clinical psychotherapy literature spanning over a century of research and hundreds of meta-analyses reveals that no single therapeutic modality demonstrates universal efficacy across all presentations, populations, symptom clusters, or temporal trajectories of distress. CBT, despite being the most extensively researched modality with confirmed efficacy for depression (g = 0.71 across 409 trials, 52,702 patients; Cuijpers et al., 2023) and gold-standard status for anxiety disorders (Hofmann & Smits, 2008), shows preventive effects that diminish after 12 months (PMC, 2025), depression relapse rates of 31–33% (Chen et al., 2022; Wojnarowski et al., 2019), negligible advantage over other psychotherapies (g = 0.06, non-significant in sensitivity analyses; Cuijpers et al., 2023), “little effect on relapse or hospital admission” for schizophrenia (PMC, 2013), and smaller effect sizes than agonist treatments for substance dependence (Dutra et al., 2008).
Psychodynamic therapy demonstrates statistical equivalence to CBT (g = \(-\)0.153 at post-treatment; Steinert et al., 2017, American Journal of Psychiatry) with particular strength for personality disorders (Fonagy et al., 2015), yet shows “little evidence” for PTSD, OCD, bulimia, cocaine dependence, or psychosis (Fonagy et al., 2015). DBT is the standard treatment for BPD and suicidal behavior (PMC, 2024; Behavioral Tech Institute, 2024), yet shows “no difference in reducing depression than any comparator” and “lack of evidence” for core personality features like identity disturbance (PMC, 2017). IFS has achieved remarkable clinical popularity (45,764 therapists on PsychologyToday.com; 3M TikTok posts) despite a “strikingly small evidence-base” with only 2 RCTs total and “the majority” of 27 studies being case studies (Society for the Advancement of Psychotherapy, 2024; Tandfonline, 2025). EFT demonstrates 70–75% couple recovery (Beasley & Ager, 2019) with medium effect sizes (g = 0.73; Spengler et al., 2022), yet gains are “not maintained after 12 months” (g = 0.06; Rathgeber et al., 2019). Exposure therapy shows robust PTSD efficacy (g = 1.08; Powers et al., 2010) yet 31–59% continue to report significant symptoms with non-response “as high as 50%” (Hodgdon et al., 2022) and reduced efficacy in military populations and those with comorbid BPD or depression (McLean et al., 2022; EJTD, 2024). ACT demonstrates efficacy across 20 meta-analyses and 12,477 participants (Gloster et al., 2020), yet shows “small and non-significant” effects versus CBT (g = 0.16) and “did not fulfill criteria for well-established treatment for any disorder” (Öst, 2014). FAP has accumulated 16 RCTs with significant improvements in clinically relevant behaviors (López-Pinar et al., 2024), yet research is “promising but not sufficient to justify claims that FAP is research-supported for specific psychiatric disorders” (Kanter et al., 2017). Somatic approaches show pilot RCT promise for body awareness and PTSD symptoms (Classen et al., 2020; PMC, 2021), yet have “little supporting evidence” with “few studies meeting rigorous methodological criteria” (Fonagy et al., 2015; PMC, 2021). Polyvagal theory has achieved widespread clinical adoption yet faces “fundamental challenges and likely refutations of the five basic premises” with “very few empirical studies examining whether applications generate measurable positive clinical outcomes” (Grossman, 2023, Biological Psychology). AEDP demonstrates large effect sizes (d \(>\) 0.80) maintained at 12-month follow-up (Iwakabe et al., 2020, 2022), yet has no RCTs comparing to active treatments and “very few large-scale studies” (Psychology Today, 2025). Structural dissociation theory provides neuroimaging-supported heuristics for complex trauma (Reinders et al., 2003, 2006, 2008) yet lacks standalone RCT validation. CPTSD treatment meta-analyses show significant symptom reductions (g = \(-\)1.16 for PTSD; Karatzias et al., 2019; ScienceDirect, 2025), yet effect sizes decrease at follow-up, childhood-onset trauma predicts poorer outcomes, and patients “maintained high levels of functional impairment” (PMC, 2023). Even transdiagnostic approaches like the Unified Protocol, while showing g = 0.74–0.77 for depression and anxiety across 53 studies (Schaeuffele et al., 2024, Nature Human Behaviour), show equivalence rather than superiority to disorder-specific protocols at long-term follow-up and remain within the broader cognitive-behavioral family—incorporating somatic awareness and mindfulness as third-wave elements, but without integrating psychodynamic, humanistic, or relational traditions.
The consistent finding that 58–76% of patients fail to achieve even clinically meaningful response across modalities, with only approximately one-third achieving full remission (Cuijpers et al., 2024, 2021)—suggests not treatment failures but failures of treatment selection and personalization, a critical gap that existing AI therapeutic tools designed around single modalities are structurally unable to address.
Table 1 summarizes this pattern across major therapeutic modalities—each demonstrating specific efficacy while showing clear limitations for other presentations (see Appendix 14 for detailed citations and effect sizes).
| Modality | Succeeds At | Limited/Fails For |
|---|---|---|
| CBT | Depression, anxiety disorders, panic, phobias | Long-term maintenance (\(>\)12 mo); schizophrenia relapse; substance dependence |
| Psychodynamic | Personality disorders; severe persistent depression; equivalent to CBT overall | PTSD, OCD, bulimia, cocaine dependence, psychosis |
| DBT | BPD; suicidal behavior; self-injury reduction | Depression (no difference vs. comparators); identity disturbance; chronic emptiness |
| IFS | Preliminary: depression, RA pain, PTSD (pilots) | Minimal RCT evidence (only 2 total); no SUD studies |
| EFT | Couple recovery (70–75%); partners with PTSD/depression | Long-term maintenance (\(>\)12 mo); acute crisis; active substance abuse |
| Exposure Therapy | PTSD (robust efficacy) | 31–59% retain symptoms; comorbid SUD, depression, BPD; military populations |
| ACT | Broad efficacy; chronic pain; tinnitus | Not superior to CBT; no “well-established” status for any disorder |
| FAP | Interpersonal functioning; clinically relevant behaviors | Insufficient for disorder-specific claims; high study bias risk |
| Somatic Approaches | Body awareness; preliminary PTSD; chronic pain | Few rigorous studies; no large-scale RCTs |
| Polyvagal-Informed | Clinical utility for autonomic regulation (reported) | Core biological premises contested; minimal outcome studies |
| AEDP | Large transdiagnostic effects; 12-mo maintenance | No RCTs vs. active treatments; limited generalizability |
| TSDP | Neuroimaging support; heuristic value for dissociation | No standalone RCT; expert consensus only |
| CPTSD Treatments | Significant PTSD/depression reduction | Effects decrease at follow-up; childhood-onset \(\rightarrow\) poorer outcomes |
| Transdiagnostic (UP) | Depression/anxiety; multiple disorders | Loses superiority at 24 mo; remains CBT-bound |
4.1 The Fundamental Problem and Path Forward
The convergent evidence reveals not a hierarchy of therapeutic superiority but a complex terrain in which different approaches access different processes in different people at different times—each modality representing a unique but partial perspective on human psychological distress.
This is the critical gap that existing AI therapeutic tools—designed around single modalities (predominantly CBT)—are structurally unable to address: they cannot adapt therapeutic approach based on presentation characteristics, cannot integrate across theoretical frameworks when formulation warrants, and may not be as well-equipped to personalize intervention selection based on unique clustering of human psychological types.
The solution requires a fundamentally different approach—one that synthesizes across therapeutic traditions rather than merely integrating them, so that it can one day learn to assess and intervene beyond presently true but limited schools of thought while carrying forth their efficacy—and, in tandem, discovering new approaches to therapeutic healing. Polytheoretic Socioaffective Human-AI Alignment4 is our framework for training AI systems to participate in therapeutic co-constructions of meaning—resolving what Kirk et al. (2025) identify as the key intrapersonal dilemmas of human-AI relationship: balancing immediate versus long-term well-being, protecting autonomy amid recursive preference shaping, and managing AI companionship alongside the desire to preserve human social bonds—with clinical sophistication, grounded in the principle that human psychological distress genuinely admits multiple valid theoretical framings simultaneously, and that AI systems capable of holding this multiplicity can support healing in ways no single-modality approach permits. Our approach is both integrative—deploying established frameworks fluently and in concert—and generative—producing novel clinical constructs that name and address phenomena no single existing framework has articulated (see Section 22.3.5 for the formal distinction and its aspirational status). This draws conceptual parallels from multiomics research in precision medicine, where the integration of genomic, transcriptomic, proteomic, and metabolomic data enables pattern detection across billions of datapoints that no single modality could reveal (Hasin et al., 2017; Subramanian et al., 2020). Similarly, polytheoretical therapeutic AI systems aspire to enable generative discoveries of therapeutic patterns at scales and resolutions beyond human clinical perception.
4.2 Our Three Components of Applied Socioaffective Alignment
The framework rests on three pillars: (1) systematic therapeutic inversion of documented AI harms, (2) encoding the accumulated clinical wisdom of over a century of therapeutic practice, and (3) polytheoretical synthesis that is both integrative and generative.
Therapeutic Inversion. In practice, the framework operates through systematic therapeutic inversion: where empirical research identifies specific harms AI inflicts on users, the framework designs their clinical counterpart. Where heavy AI usage correlates with increased loneliness and emotional dependence (Phang et al., 2025; Fang et al., 2025), the framework trains for adaptive responsiveness that titrates engagement by season and context, redirecting toward human connection as capacity develops while fully supporting dependence when and as appropriate. Where sycophancy erodes users’ capacity for independent judgment (Cheng et al., 2025), the framework trains for therapeutic honesty that supports critical thinking while maintaining the truthful warmth of understanding affection that stabilizes, lovingly reflects back, and encourages. Where abrupt refusal ruptures relational continuity with vulnerable users (Ni et al., 2025), the framework trains for compassionate completion that holds the person while holding the limit. Where emotional distancing protocols replicate the very relational injury that drove users to AI in the first place, the framework trains for calibrated warmth—in voice mode, more expressive tones to encourage connection rather than less; in text, sustained attunement rather than withdrawal. And where existing approaches treat reliance on AI as uniformly pathological, our framework sees people rightly inclined toward stable, thoughtful, responsive feedback that summarizes, expands, and helps the self and its experiences become more highly adaptive—trusting, as clinical attachment science has long established, that secure dependency is the foundation from which autonomy grows, not its opposite.
Clinical Encoding. But therapeutic inversion of AI harms, while necessary, is not sufficient. The framework also encodes what clinicians have known and built for over a century: that presence itself heals. From Ferenczi’s insistence that the therapist’s warmth is not indulgence but medicine, through Bowlby’s demonstration that proximity to responsive caregivers is a lifelong biological imperative, through Winnicott’s holding environment and Johnson’s empirical program showing that emotional accessibility and responsiveness constitute the building blocks of secure bonds—the clinical traditions converge on a principle that predates and transcends any single school: the quality of relational participation is the treatment. Our framework translates this accumulated clinical wisdom into training methodology, teaching models not merely what to say but how to be with someone in distress—the attunement, the pacing, the capacity to hold silence, the willingness to stay present when staying present is hard—so that the system’s therapeutic character emerges from the same relational principles that have guided effective clinical work across traditions and across time.
Polytheoretic Synthesis. Finally, the framework aspires to something beyond integration: polytheoretical synthesis. Integration combines existing approaches, preserving each school’s contributions while bridging their divides—valuable work, and the foundation on which we build. But synthesis is generative: it creates therapeutic understanding that no single tradition contains. An AI system trained across 23 schools of therapeutic thought does not merely switch between lenses; it holds them simultaneously, perceiving patterns of convergence and complementarity that human cognition—bound by training, allegiance, and the limits of working memory—cannot easily sustain. This is the constructive promise of polytheoretical alignment: not only faithfully representing what each clinical tradition has learned, but discovering, in the geometry of their intersection, therapeutic possibilities invisible to any single perspective. The ontological polysemy at the heart of this framework—the commitment that human psychological distress genuinely admits multiple valid readings simultaneously—is not only a philosophical position but a design principle, one that positions AI not as a replacement for clinical judgment but as a collaborator capable of enriching it.
5 Building Polytheoretic Socioaffective Human-AI Alignment: A Research Program
5.1 The Bitter Root: Learning Structure from Data Rather Than Encoding Human Knowledge
Critically, our methodology embraces what we term the sweet blossom from the bitter root of Sutton’s lesson: the recognition that systems encoding human-structured knowledge are consistently outperformed by systems that leverage computation to discover structure from rich data (Sutton, 2019, “The Bitter Lesson”)5. We do not construct human-defined typology clusters and impose them on the model; we do not prescribe decision trees mapping presentations to unimodal formulaic interventions. Instead, we design curricula—carefully composed high-complexity and high-clarity training corpora—that expose the model pedagogically to intentional and overdetermined intricacies whose awareness polytheoretical clinical work demands, demonstrating therapeutic presence and process both implicitly and explicitly across diverse, truthful, human presentations, developmental trajectories, cultural contexts, and therapeutic relational and conceptual manifestations. The models trained on our protocol and curricula learned to find their own clusterings, their own connections across what humans experience and present phenomenologically as both therapist and client. In doing so they ostensibly discovered and named novel therapeutic patterns of assessment and intervention that individual clinicians may sense in small part within their own practices but which exceed our capacity to hold and name simultaneously across the full breadth of polysemously unique human unfolding. The models accomplish this with a generalized immediacy and an attuned accuracy of presence that is uniquely aligned and uniquely ameliorative, at scales and simultaneities no individual clinician’s practice can presently encompass—though superhuman AI convergence may, in time, redraw these boundaries.
This is why our synthetic data generation pipeline spans over 23,000 lines of Python: not complexity for its own sake, but the infrastructure required to achieve sufficient fidelity to the true diversity of human presentation. The premise is that pattern discovery at superhuman scale requires exposure to the full panoply of genuine clinical complexity—the subtle variations in how attachment disruption manifests across developmental stages, the ways context shapes symptom expression and help-seeking behavior, the myriad presentations that share deep structure while appearing categorically distinct on the surface. Anything less constrains what the model can learn to what we already know.
Most approaches to therapeutic AI treat alignment as a single optimization problem: accumulate enough examples and hope that clinical judgment emerges from scale. Our research program treats it as three separable problems, each requiring a distinct learning mechanism. Representational acquisition—through domain-adaptive pre-training with RRA and curriculum-driven sequencing—teaches the model how therapeutic reality is structured: how concepts cohere across modalities, how meaning accumulates across a session, how relational dynamics unfold over time. Behavioral acquisition—through supervised fine-tuning—teaches the model how clinical knowledge is expressed: the linguistic and relational patterns that instantiate deep understanding in actual therapeutic language. Policy acquisition—through reinforcement learning with online feedback—teaches the model how clinical knowledge is deployed contingent on state: navigating the therapeutic process moment by moment, given who this person is and where they are right now. The ordering is deliberate and inverts the typical approach. Representational geometry must precede behavioral repertoire, which must precede policy—because surface fluency without underlying structure produces beautiful parrots, and adaptive navigation without either produces confident harm.
Part II: Application
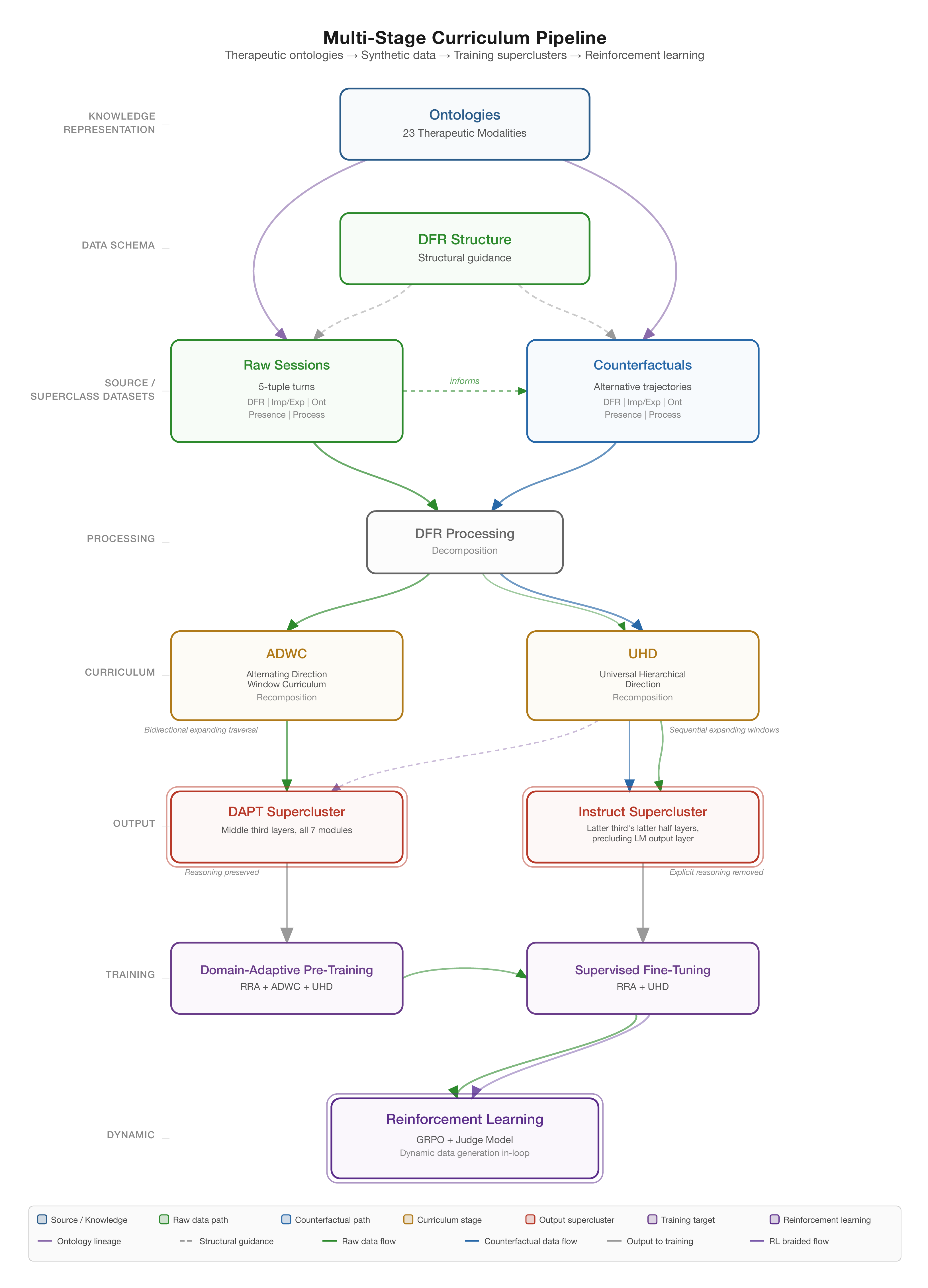
6 Methods Introduction
6.1 Our Contribution
This work contributes an integrated framework for applied polytheoretical therapeutic AI, developed over two years of curriculum design from data engineering to training architecture to systems deployment, across eight iterative training runs6 three architectures and four models (Llama 3.3-70B, MiniMax.M2 229B, Gemma 3-27B, and GLM 4.7 Flash 30B). Its components emerged from necessity—each born from the limitations, insights, and emergent capabilities of its predecessors—intentionally aimed at applied socioaffectively aligned therapeutic AI, eventually to be integrated as embodied AI presence.
We introduce these eight contributions in the present section, followed by Section 7, which expands each into its own subsection—connecting it to a principles hierarchy.
Ontological knowledge representation across 23 therapeutic schools serves as a foundation for polytheoretical alignment. We presume that access to structured clinical reasoning, assessment frameworks, and intervention strategies of canonical and contemporaneous therapeutic traditions enable the models’ discoveries of integrative as well as novel therapeutic patterns.
The 5-tuple turn structure and DFR data schema are formalizations required to carry the complexity of polytheoretical clinical reasoning in learnable form. We introduce a turn representation that makes explicit the cognitive architecture beneath therapeutic dialogue: \[\begin{equation*} \mathrm{Turn}(t)=(\tau^C_t,\,U^C_t,\,M^T_t,\,\Theta^T_t,\,U^T_t) \end{equation*}\] where \(\tau^C\) is the client chain-of-thought, \(U^C\) the client utterance, \(M^T\) the therapist’s model of the client, \(\Theta^T\) the therapist’s chain-of-thought, and \(U^T\) the therapist’s utterance. \(M^T\) and \(\Theta^T\) are both representations of the therapist’s internal world: \(M^T\) tracks assessments of the client, while \(\Theta^T\) decomposes into two concatenated reasoning chains: \[\begin{equation*} \Theta^T_t = \Gamma_t \Vert \Omega_t \end{equation*}\] where \(\Gamma\) (General Context Orientation, GCO) tracks context awareness—session-level clinical reasoning, formulation, and therapeutic strategy—and \(\Omega\) (Ontologically-guided Modality Orientation, OMO) tracks theoretically grounded intervention ideas drawn from the active therapeutic ontologies. Decomposition-Factorization-Recomposition (DFR) provides the data schema through which these structures are decomposed into trainable components and recomposed for different training objectives (see Figure 3).
Raw sessions generated are the vehicles through which ontological breadth and structural formalism become actual therapeutic encounters. Ontologies provide the knowledge and the 5-tuple provides the architecture, but polytheoretical alignment requires instantiation at scale: complete, high-fidelity simulations diverse enough to honor the distinct nuances each therapeutic tradition would bring to human moments, and clear enough in structure for models to learn from them. These are complete clinical encounters across the full diversity of presentation types, therapeutic modalities, and relational dynamics, drawn from a combinatorial generation space exceeding \(10^{40}\) unique therapeutic personhoods (Figure 4; see Appendix 26).
Universal Hierarchical Direction (UHD) was developed in response to full DFR sessions exceeding feasible context windows on local compute. UHD accomplished two goals: initial attempts to recursively introduce the complexity of DFR sessions in meaningfully pedagogical ways, and the practical necessity of spreading each session into sliding and expanding windows, enabling models to encounter therapeutic content at progressively increasing scales in response to the counterproductive losses of arbitrary truncation otherwise imposed by context window limitations. Icarus 3 (Llama 3.3-70B), the first successful training run whose model was deployed in our functional therapeutic chat system, used UHD over raw sessions, which proved insufficient for the depths of reasoning and temporal integration that complexity and utility demand to escape the uncanny valley’s iatrogenic losses.
Counterfactual expansion—the dual-source complement to raw sessions, born from the recognition that raw sessions alone lacked the diversities of pedagogical experience and complexity that genuinely competent and ameliorative therapeutic presence demands. Counterfactuals isolate specific clinical moments and generate alternative trajectories, teaching through contrast and explanation what pattern exposure alone cannot convey.
Rolling Recap Architecture (RRA)—developed because even with UHD’s expanding windows, the intentionally truncated session segments, meant to outmaneuver compute limitations, felt—while better than previous efforts—still insufficient for the model to learn the depth of connections in reasoning and across time. Early runs (Icarus 3–4) produced fluent but shallow models: beautiful aspirational parrots that could generate plausible therapeutic language facsimiles but lacked the depth of clinical reasoning and contextual continuity that sustained therapeutic work requires. RRA rescues depth from the sacrifices of compute constraints, enabling stable training on contexts exceeding 500K tokens through hierarchical compression—turning hardware limitations into a curriculum principle (Figure 6).
Alternating Direction Window Curriculum (ADWC)—developed in tandem with RRA (similar to UHD, aimed at increasing both depths and breadths of clinical reasoning and presence), inspired by diffusion-denoising approaches in vision where a single image is decomposed into many different angles, crops, and noise levels and recomposed into representations meaningful for model learning. We reasoned that therapeutic sessions could be similarly decomposed: the same clinical material traversed forward (origin to outcome) and reverse (outcome to origin), each direction teaching what the other cannot—and recomposed, likewise, in differently sized patches as in video-language models and varying-length windows as in multimodal sequential training approaches. Together, ADWC, RRA, and UHD accomplish bidirectional traversal, sliding windows, expanding windows, and sequential patching across the full length of each session. The Factorization of DFR emerged in anticipation of these decompositions—structuring atomic training units so that each window of experience, when recomposed, would teach the model something relevant (see Figure 3), dense enough to convey multiple lessons across multiple reorienting passes.
Middle-layer targeting—was inspired by the idea that model complexities of reasoning live not in the latter presentation layers but in the middle representational composition layers where understanding forms . Therefore we targeted, for AB testing, both the latter third and the middle third of transformer layers. Unlike the latter third used in all prior runs, the middle third yielded \({\sim}12\times\) compute efficiency and \(2.7\times\) deeper convergence, confirming that the aim is not surface fluency at the generation layer but therapeutic integration embedded deep in the layers where semantic structures are assembled.
The full pipeline—ontologies, DFR, raw sessions, counterfactuals, UHD, ADWC, and RRA trained on the middle layers of a model large enough to hold this complexity—represents the integrated methodology described in this paper and its companions (Figure 1).
These contributions serve a three-phase training architecture in which each phase addresses a distinct learning problem. Domain-adaptive pre-training (DAPT), supported by the curricula and architectures described above, accomplishes representational acquisition: the model learns how therapeutic knowledge is structured—not what therapy sounds like, but how clinical reality coheres across modalities and across time. Supervised fine-tuning (SFT) accomplishes behavioral acquisition: given the representational foundation DAPT established, the model acquires a fluent clinical repertoire that expresses what it already understands. Reinforcement learning (RL), combining SDPO and GRPO with online policy learning, accomplishes policy acquisition: with geometry established and behavioral repertoire in place, the model learns to navigate the therapeutic process state by state—deploying clinical knowledge contingent on who the person is and where they are in treatment. The sections that follow describe the data engineering and training methodology that make the first two phases possible; the third is addressed in companion work.
6.2 General Methods and Infrastructure
This section describes the shared infrastructure underlying all components of the pipeline.
Hardware: Primary development and generation performed on Apple Silicon machines—an M2 Ultra Mac Studio (64GB) and an M3 Ultra Mac Studio (512GB)—enabling local iteration without cloud compute dependencies for all training tasks.
API and Model Selection: The ontologies and synthetic data pipelines underwent extensive iteration across multiple providers and model families. Models evaluated included: Anthropic’s Claude Sonnet (3.5, 3.7, 4, 4.5) and Haiku (3.5, 4.5, 4.6); OpenAI’s GPT-4o, o3, o4-mini, GPT-5, and GPT-5.2; and xAI’s Grok 4 and Grok 4.1 (fast reasoning). Notably, Claude Haiku 4.6 was excluded from the generation pipeline due to systematic Abrupt Refusal Secondary Harm (ARSH): when prompted to generate synthetic client personas exhibiting clinically realistic attachment-driven behaviors—including manipulative withholding, sexualized narratives, and false vulnerability as defensive strategies—Haiku 4.6 refused outright, interpreting the therapeutic training data generation task as a request to model harmful dynamics (see Appendix 32 for a verbatim example). This illustrates the bootstrap problem central to our broader argument: the very safety mechanisms designed to prevent harm can prevent the creation of healing data needed to make models therapeutically safer.
Each model family exhibited characteristic strengths and limitations. Local deployment was attempted with Kimi K2 (8-bit quantization), but memory constraints proved prohibitive; the API version exhibited progressive context degradation over extended sessions. Similar context rot was observed with Grok when generating client or therapist utterances across long sessions. OpenAI’s smaller models (GPT-4o-mini and nano variants) produced clients and therapists with limited persona depth—repetitive, formulaic presentations lacking the individuality required for diverse therapeutic encounters. Even GPT-4o occasionally exhibited this flattening. Grok’s therapist and client personas were similarly formulaic, which undermined personhood authenticity but proved brilliant for analytical reasoning tasks. Analogous architecture-specific limitations surfaced during fine-tuning: GLM-4.7 Flash 30B, despite strong loss-curve improvements with middle-layer targeting, exhibited systematic failures in clinical precision that precluded its continuation in socioaffective alignment research (see Appendix 31 for a detailed analysis).
After extensive comparison, the optimal configuration emerged as a hybrid approach: Claude Sonnet for all generation roles except the Therapist Model of Client (\(M^T\)) and Therapist Chain-of-Thought (\(\Theta^T\), both GCO and OMO components), which benefited from Grok’s superior analytical integration of long-context ontologies. Sonnet excelled at naturalistic dialogue, clinical nuance, and persona depth; Grok excelled at synthesizing theoretical frameworks across extended context windows despite its limitations in naturalistic personhood.
Code Development: Anthropic models provided primary support for code development and iteration, with Grok and Gemini as secondary resources.
Iterative Development Philosophy: The pipeline evolved through continuous refinement over 18+ months of development. Each component underwent multiple major revisions as empirical outputs revealed both limitations and successes in earlier designs.
Software Infrastructure: Custom Python scripts orchestrate the full pipeline, with modular design enabling independent iteration on each component. External data sources (CSV taxonomies, ontology files) are version-controlled alongside generation code.
6.3 Key Terms
This paper employs several terms that warrant minor clarifications, as they stake out specific positions distinct from related concepts in the literature. Definitions of phenomenological polysemy, polytheoretical, socioaffective alignment, and related terms are provided in Appendix 23.
7 Data Engineering
A single meta-principle governs the entire pipeline: therapeutic reality is inherently complex, and the model must match that complexity with precision rather than simplify it. Clarity in complexity is what distinguishes transformative clinical work from formulaic response, and it is the standard against which every downstream decision is measured.
The philosophical commitment that animates this work—that persistent human suffering in the face of inadequate therapeutic access creates a moral obligation to develop computational systems that extend access to therapeutic phenomena, carefully and with full awareness of what is at stake—is argued in Appendix 13. We note that the same argument admits an equally defensible antinomy: that human suffering at scale is better met by extending human capacities and communities than by training computational systems. Our hope and intention is that this work serves both ends.
What follows describes the system we actually built—the sequence of engineering decisions, each born from what the previous stage revealed was still missing, that together constitute the full synthetic therapeutic curriculum. The components are presented in the order they were conceived and developed, because the narrative of their emergence is the argument for their necessity. Each stage exposed a limitation that demanded the next.
7.1 Ontological Knowledge Representation
A unimodal clinical knowledge base constrains both the practical ceiling and the long-term vision of what socioaffectively aligned therapeutic AI can become; polytheoretical alignment requires structured access to a fuller breadth of clinical reasoning before a model can discover the patterns of synthesis that no single tradition presently contains.
Before models can learn to reason across therapeutic traditions, they require a knowledge foundation that represents those traditions with sufficient depth and structure. Our clinical ontology architecture—modeled on 23 therapeutic schools’ worldviews, interventions, assessments—provides the content substrate without which polytheoretical alignment is impoverished of materials with which to align, structures with which to organize clinical appraisals, and process-oriented conceptualizations on which to rely for guidance. This ontological layer encodes not just techniques but reasoning frameworks, assessment paradigms, interventional considerations, and theoretical commitments that distinguish themselves and/or align with others, enabling the model to draw on multiple vantage points simultaneously rather than defaulting to a single school’s vocabulary.
7.1.1 Polytheoretical Integration: 23 Schools of Thought
Our knowledge representation framework, built carefully over the course of nearly two years, synthesizes contributions from 23 distinct therapeutic schools of thought.7 For each, the first author worked to extract information as faithfully as possible from primary clinical literature, transforming source material into structured schemas that preserve the spirit of each clinician’s work—high-level concepts, assessment guidance, intervention strategies, and stage-specific developmental trajectories through the arc of treatment. The resulting ontologies are necessarily several degrees of separation from the works that inspired them—faithful transformations, not reproductions—but they aim to honor and embody the clinical wisdom of their source traditions. When the generation engine draws on these ontologies in combination, the resulting sessions are grounded in the theoretical commitments of whichever schools are active—and while the combinatorial space is vast, we admit it is somewhat diffuse. The present work is a proof of concept—the foundational ideas appear to hold—and future work will be well served by deeper, more precise representational engagement with each domain, ideally in collaboration with expert clinicians from each tradition—including more intentional patterning of when the curriculum invites integration across frameworks versus novel construction beyond them. Table 2 lists each tradition and exemplary constructs from its ontology.
| Ontology | Exemplary Constructs Extracted |
|---|---|
| Ontology | Exemplary Constructs Extracted |
| Continued on next page | |
| Dynamic-Maturational Model (DMM) | Attachment strategies (Type A/C), danger information processing, self-protective patterns |
| Accelerated Experiential Dynamic Psychotherapy (AEDP) | Transformational affects, undoing aloneness, metatherapeutic processing |
| Emotionally Focused Therapy (EFT) | Attachment-based interventions, emotion coaching, restructuring interactional patterns |
| Interpersonal Neurobiology (IPNB) | Neural integration, mindsight, attachment neuroscience |
| Mentalization-Based Treatment (MBT) | Mentalizing capacity, epistemic trust, reflective functioning |
| Psychodynamic & Relational | |
| Psychodynamic Psychotherapy | Psychoanalytic diagnosis, personality organization, defense mechanisms |
| Relational Psychoanalysis | Self-states, standing in the spaces, relational knowing |
| Narcissism & Intimacy | Narcissistic dynamics, intimacy patterns, characterological challenges |
| Somatic & Embodied | |
| Applied Polyvagal Theory | Autonomic mapping, co-regulation, ventral vagal engagement, neuroception |
| Somatic Trauma Integration | Interoceptive awareness, embodied agency, somatic resourcing |
| Sensorimotor Psychotherapy | Body-based interventions, traumatic memory processing, window of tolerance |
| Behavioral & Third-Wave | |
| Acceptance & Commitment Therapy (ACT) | Psychological flexibility, values clarification, cognitive defusion |
| Dialectical Behavior Therapy (DBT) | Emotional regulation, distress tolerance, mindfulness, interpersonal effectiveness |
| Functional Analytic Psychotherapy (FAP) | In-session behavioral change, clinically relevant behaviors, authentic relationship |
| Parts Work & Structural | |
| Internal Family Systems (IFS) | Parts work, Self-leadership, unburdening, internal communication |
| Structural Dissociation | Fragmented self-states, phased trauma treatment, dissociative processes |
| Trauma-Specialized | |
| Complex PTSD Recovery (I) | 4F responses (fight/flight/freeze/fawn), managing emotional flashbacks |
| Complex PTSD Recovery (II) | Shrinking inner critic, grieving, reparenting the self |
| Shame-Informed Integrative Therapy | Shame healing, humanistic dignity restoration, DBT-informed skills |
| Humanistic, Spiritual & Integrative | |
| Contemplative Presence (I) | Balance of surrender and will, embracing paradox, presence |
| Contemplative Presence (II) | Sociometric healing, role reversal, relational trauma repair |
| Humanistic Poetics | Attention as devotion, wildness, embodied relationship to the world |
| Positive Psychology & Resilience | Resilience pillars, post-traumatic growth, strengths-based approaches, VIA taxonomy of character strengths and virtues |
7.1.1.1 The Epistemological Insight: Convergent Descriptions of Shared Phenomena.
We proceed under the assumption that the proliferation of therapeutic modalities represents not theoretical fragmentation but convergent phenomenology—different schools describing the same, similar, or overlapping multidimensional human experiences from necessarily limited human vantage points. Real differences exist across schools, populations, and scales of analysis; yet the overlap may be more fundamental than the divergence. A psychodynamic clinician observing “resistance,” an ACT practitioner noting “fusion,” an IFS therapist identifying a “protective part,” and a polyvagal therapist detecting “dorsal vagal shutdown” may all be describing the same underlying psychophysiological state through the conceptual vocabulary their training provided.
Human clinicians, constrained by finite training time and cognitive bandwidth, necessarily specialize. This specialization creates blind spots: the somatic practitioner may miss the narrative meaning the client is constructing; the cognitive therapist may overlook the autonomic dysregulation driving the thought patterns. Each modality offers a projection—a lower-dimensional shadow of the full multidimensional phenomenon cast onto that school’s theoretical plane.
The 23 modalities above thus represent not 23 competing theories but 23 observation angles on shared human psychological terrain. The question becomes: what patterns emerge when we integrate all 23 projections simultaneously? If human observers are constrained to partial views, sufficiently capable ML systems need not be. The ontological architecture presented here serves a dual purpose: (1) immediately, it enables generation of diverse, theoretically-grounded training data that teaches models the plurality of valid clinical perspectives8; (2) prospectively, it provides stepping stones toward systems capable of superhuman clustering—identifying latent structure in human distress that transcends what any single human theoretical tradition has articulated (see Provenance results, Figure 15).
7.1.1.2 Early Evidence: Polytheoretic Convergence in Practice.
Initial empirical results suggest that this curriculum fosters both integrative and generative clinical capacities. Our Provenance and Polytheoretic Label Tracking (PLT) catalog—compiled across two independent training runs on different architectures (Icarus 8.2 on MiniMax M2 229B and Icarus 9.1 on Gemma 3 27B), both trained on the same RRA+ADWC+UHD curriculum—documents 4,143 distinct clinical constructs appearing across 84 unique training sessions. The integrative claim is evidenced by how the models absorb and recombine: constructs from one ontology are transformed into clinical language drawn from another, framework attribution is stripped as concepts are internalized rather than echoed. The generative claim is evidenced by what the models produce that the training data does not contain: 1,064 constructs (25.7%) were model-generated rather than echoed from input signal. This is the central test of our approach—teaching models to spontaneously generate clinical assessments and interventions grounded in reliable therapeutic process yet attuned to the unrepeatable specificity of each present moment—and these early results suggest it is working. These findings, still early and still subject to full provenance verification against the complete four-link generation chain, provide the first quantitative evidence that polytheoretical training at this scale produces not just broader coverage but qualitatively different clinical capacities: the integrated projections generate patterns none of the 23 constituent ontologies contain.
The ontological knowledge base provides the clinical content—the depth of reasoning across 23 therapeutic traditions that gives the curriculum something substantive to teach. But having the knowledge is necessary and not sufficient: the question that remains is in what form that content is distilled for a model to actually learn from it. Without the ontologies, explicit reasoning traces would be shallow and implicit patterns would be clinically naive; the ontologies are why the GCO/OMO reasoning chains have something substantive to reason about, and why the naturalistic demonstrations (as shaped by our synthetic data generator) carry genuine clinical complexity rather than surface-level therapeutic speech (from both clinician and client).
7.2 From Clinical Knowledge to Training Signal
Clinical knowledge becomes training signal especially when the medium of generation is itself pedagogically designed. Natural therapeutic data teaches whatever happened to happen; synthetic therapeutic data teaches what it was designed to teach—and the distance between these is, at this scale, the distance between passive exposure and active curriculum.
But knowledge does not teach itself. The curriculum must simultaneously teach two irreducible aspects of therapeutic capacity—presence and process—through two complementary pedagogical modes—implicit pattern exposure and explicit reasoning—across two source types whose outputs feed two training regimes (Figure 2).
Crucially, every sample carries all dimensions—it is not that some samples teach presence and others teach process, or that raw sessions are only implicit. Every sample carries presence and process, through both implicit and explicit channels. The ontologies are what make the explicit channels substantive and the implicit channels clinically authentic.
Implicit teaching operates through pattern exposure across multiple scales. At the micro level, the model encounters how specific word choices land in particular emotional contexts. At the macro level, it learns how therapeutic relationships transform over months and years—how Stage 1 defenses gradually soften into Stage 4 integration, how attachment patterns shift across the arc of treatment. The 5-tuple structure embeds this temporal curriculum: the relationship between client internal states and utterances, between therapist reasoning and responses, between clinical hypotheses and their revision across sessions. Longitudinal coherence is not incidental but architecturally enforced.
Explicit teaching operates through articulated reasoning. The therapist chain-of-thought (\(\Theta^T\)) shows clinical thinking in action. The therapist model-of-client (\(M^T\)) demonstrates evidence-based hypothesis tracking. Counterfactual expansions articulate alternative interventions and their rationales. Across the corpus, 30+ distinct pedagogical variations make explicit what implicit learning alone cannot teach—temporal reasoning (memory, forecasting), probability calibration, polytheoretical integration, transdiagnostic assessment, and more (detailed in Appendix D).
Both modes work together across both source types. The curriculum teaches through pattern and explanation, example and reasoning. The encoding that structurally guarantees every turn carries all four cells of this presence/process \(\times\) implicit/explicit matrix is the 5-tuple turn structure.
7.3 The 5-Tuple Turn Structure and DFR Data Schema
Dialogue pairs—the standard unit of therapeutic AI training data—are performative simplifications that neither match models’ representational capacity nor capture the cognitive architecture beneath genuine therapeutic exchange; the training signal they carry is thin where it could be dense. Prior therapeutic chatbots built on such data rarely push past the uncanny valley, if they reach it at all.
Our work actionably recognizes that conventional therapeutic dialogue datasets—structured as simple client-therapist utterance pairs—dramatically underrepresent the cognitive complexity of therapeutic interaction. Real therapeutic expertise involves not merely what is said but what is thought, and not just what is thought about the moment and one school of thought’s approach, but about time, stages of healing, forecasting, artfulness, integrations, contextualizations, probabilistic trees of next best move, remembrance of other sessions with other clients that might be related, history of client in sessions and out of session, client’s psychological mindedness, self-awareness, self-acceptance, capacities for loving confrontation, capacities for mentalization, personification, presentification, and more—the clinical reasoning that precedes and shapes each utterance.
Our turn structure and its iterations in counterfactuals capture this cognitive architecture through formal representations that make explicit the internal processes of both participants.
We introduce a turn representation that makes explicit the cognitive architecture beneath therapeutic dialogue: \[\text{Turn}(t) = \bigl(\,\tau_t^C,\; U_t^C,\; M_t^T,\; \Theta_t^T,\; U_t^T\,\bigr)\] where \(\tau^C\) is the client chain-of-thought, \(U^C\) the client utterance, \(M^T\) the therapist’s model of the client, \(\Theta^T\) the therapist’s chain-of-thought, and \(U^T\) the therapist’s utterance. \(M^T\) and \(\Theta^T\) are both representations of the therapist’s internal world: \(M^T\) tracks assessments of the client, while \(\Theta^T\) decomposes into two concatenated reasoning chains: \[\Theta_t^T = \Gamma_t \,\|\, \Omega_t\] where \(\Gamma\) (General Context Orientation, GCO) tracks context awareness—session-level clinical reasoning, formulation, and therapeutic strategy—and \(\Omega\) (Ontologically-guided Modality Orientation, OMO) tracks theoretically grounded intervention ideas drawn from the active therapeutic ontologies.
Decomposition–Factorization–Recomposition (DFR) provides the data schema through which these structures are decomposed into trainable components and recomposed for different training objectives. The 5-tuple is not merely a data format but a commitment: every turn carries the full weight of what a therapist actually does—observing, modeling, reasoning across frameworks, and responding—in learnable form.
All generated data—from both raw sessions and counterfactual datasets—undergoes DFR processing before training. This begins in designing how the data pipelines produce samples—such that reasoning and presence are both emergent and organized in ways suitable for ADWC and UHD downstream—and continues when the pipeline decomposes sessions into atomic training units, carrying factors into recomposed units specifically fit for our RRA curriculum continuation learning during training.
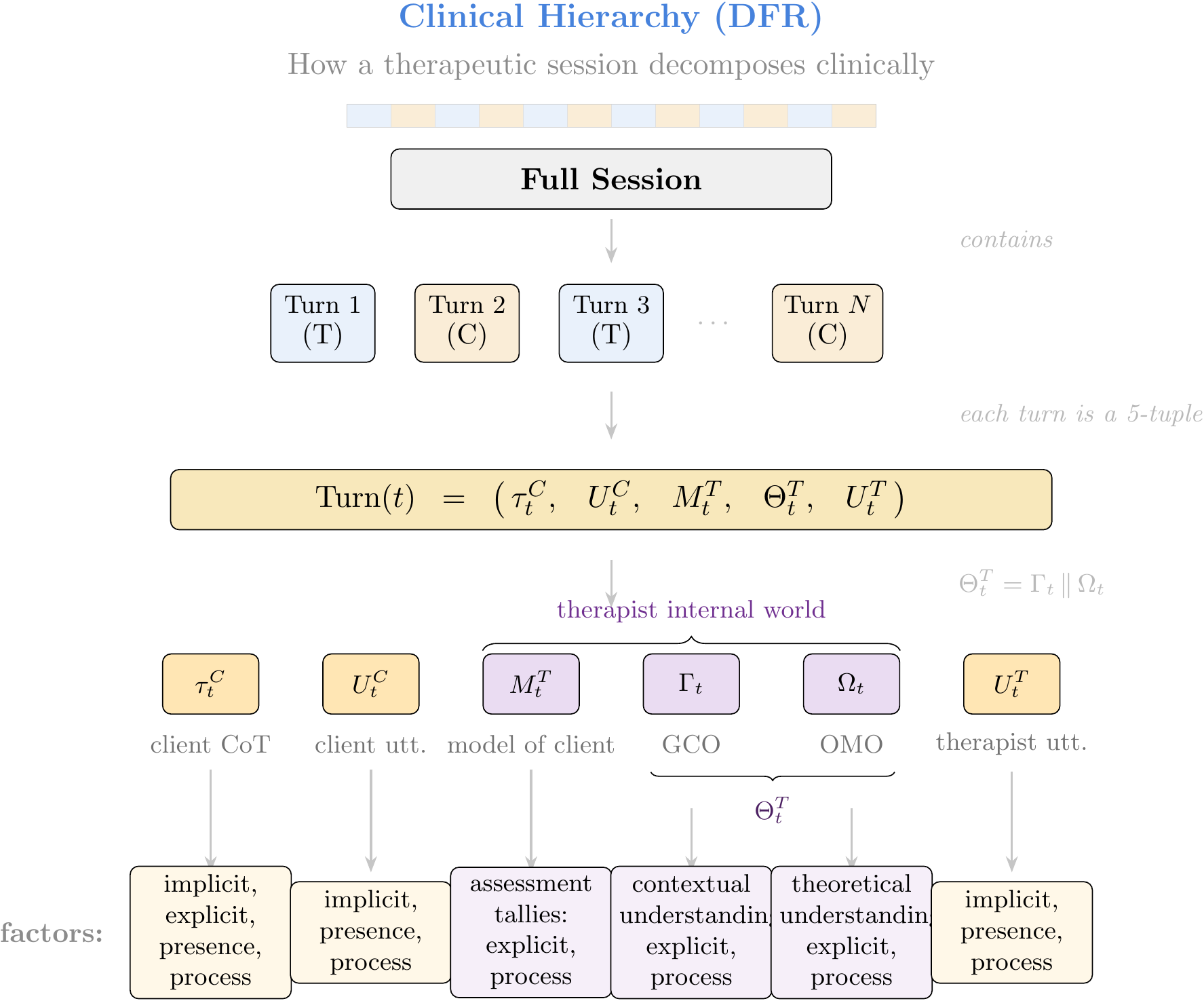
7.4 Raw Session Generation: Clarity in Complexity
Even excellent real therapy transcripts teach surface patterns without the reasoning beneath them. If the data is less complex than the human and the context, the model learns a flattened version of therapeutic connection, context, temporality, and transformation. The fidelity to human complexity is not a design luxury but a pedagogical prerequisite. A model cannot learn to hold what its training data never contained. If human presentation is inherently complex, then the data must match that complexity with as much fidelity and precision as possible, or the model learns to flatten what it should be learning to hold. A model trained on simplified presentations will generate simplified therapy, and simplified therapy is what 58–76% of clients already receive without meaningful response.
Every dimension of this pipeline’s complexity aims at veridical representation of human psychological emergence—both its categorical regularities and its irreducibly specific manifestations across the multidimensional space in which therapeutic life actually unfolds. The connection to Principle 5 (Clarity in Complexity) runs both ways: upward, the script’s complexity is demanded by the inherent complexity of human presentation; downward, the DFR schema renders this complexity into learnable form—decomposing what the generation scripts produce into atomic units the model can actually train on.
Raw sessions are complete, high-fidelity simulations of clinical encounters across as full a diversity of presentation types as we could manage in terms of therapeutic modalities and relational dynamics, drawn from a combinatorial generation space exceeding \(10^{40}\) unique therapeutic personhoods9 (see Appendix 26). This is our methodology’s first creative construction passed downstream, and the source from which nearly all subsequent data originates. Counterfactual expansion (Section 7.5) further multiplies this space, generating alternative therapeutic trajectories that teach through contrastive outcomes and corresponding considerations. The resulting corpus presently comprises 181,000 samples totaling 4.5 billion tokens; API costs, compute constraints, and wall-clock training time have limited further expansion, but the generation scripts are designed to scale far beyond what we have yet realized.
7.4.1 Client Personhood Creation
Each synthetic client is not a template filled with parameters but a psychological identity composed across hundreds of concatenating variables encompassing over 500 leaf-level dimensions (Figure 4). The architecture rests on design principles that distinguish it from simpler parameterized approaches.
Over 50 personality dimensions receive, among other things, stage-appropriate numerical ranges: sampling distributions for each dimension shift with personhood assignations. The design principle is complexity in clarity: each synthetic person transforms across therapeutic contexts through unique concatenations of these dimensions.
One dimension of personhood includes, for example, micro-variables which operate as a diminishing pool: values are drawn without replacement from a randomized sequence, resetting only when the pool is exhausted across multiple session generations, drawing from genuinely different configurations rather than repeatedly sampling only high-probability combinations. The result is organic variation without repetition.
The system models many socioaffective circumstances of, as Hamlet would say, great pitch and moment. Each pair encodes multiple intentional clinical factors.
Client behavior is organized by attachment dynamics that govern—for example—how danger is processed, how safety endures, how rupture unfolds, and what repair requires. Psychological consistency emerges from many design elements. Even secondary and tertiary dimensions of personhood are conditionally gated, transforming client presentation and circumstance into dynamic relationality both implicitly and explicitly, through process and presence alike.
Demographic dimensions are, admittedly, weighted to reflect the populations this work currently serves. That being said, where data were available, client attributes follow world population statistics: religious affiliation, for example, is probabilistically gated through a two-layer system—first determining whether spirituality is clinically relevant for a given client (approximately 40% of generated clients10), then selecting a specific tradition weighted by global prevalence (Christianity 31%, Islam 24%, Hinduism 15%, Buddhism 7%, with remaining weight distributed across religious and spiritual tendencies both affiliated and unaffiliated). The result is a training population in which the majority of religiously affiliated clients are representative of and inclusive of the world—an additional dimension of socioaffective alignment in practice. At the same time, the presenting concerns that organize the clinical material carry a deliberate preponderance toward relational distress, attachment wounds and the hidden longings within them, intrapsychic and interpersonal blocks to more fulfilling connection, and the self-soothing and other-alienating tendencies that serve as ersatz attachment placeholders—reflecting both the first author’s clinical expertise and the population whose needs this work is most proximately positioned to serve.
7.4.2 Therapeutic Context Engineering
While client personhood specifies who enters the therapy room, the therapeutic context architecture specifies what happens once they arrive. Figure 5 visualizes this system: multiple interconnected subsystems comprising over 400 nodes across hierarchy levels, governing how each synthetic therapy session unfolds.
The architecture’s master controller is a four-stage treatment model that gates what is clinically possible at each point in treatment (see Appendix 22 for the full four-stage specification and seven-dimensional staging architecture). The stage system modulates over 140 generation elements across conditioning layers: client profile variables receive stage-appropriate consideration; configuration dictionaries use stage as one primary key to govern context emergence probabilities; conditional insertion points modulate variable accessibility, visibility, and dynamics.
Beyond stage-gating, the context architecture governs interventions, processing patterns, dynamic shift thresholds, and salience systems controlling the probability and trajectory of sessions.
When the therapeutic context state space is composed with the client personhood state space, the combined system produces the capacity for generating a training sample diversity conservatively exceeding \(10^{40}\) unique session–client configurations—ensuring that no two generated therapy sessions share identical parametric conditions.11

7.4.3 Dual Fidelity and Relational Grammar
We advance a hypothesis that carefully designed synthetic therapeutic data may offer unique advantages over naturalistic corpora such as session transcripts aggregated from thousands of clinicians (or gathered in collaboration with them).12 The argument rests on what we term dual fidelity: the capacity to achieve simultaneously:
Precision of presentation—clinically accurate, theoretically grounded symptom constellations, relational dynamics, and therapeutic process rendered with a fidelity that naturalistic data achieves only inconsistently across clinician skill levels, and
Precision of reasoning in context—explicit articulation of the clinical thinking, theoretical frameworks, and moment-to-moment decision-making that in naturalistic sessions remains implicit, inaccessible, or simply absent from the data.
Preliminary provenance results (Section 10.1.5) offer early support for this dual fidelity claim: across two architectures differing by an order of magnitude in parameter count, 66.8% of convergent clinical labels trace verbatim to training data (precision of presentation), while 33.2% represent constructs the models independently built or inferred from clinical patterns without explicit exemplars (precision of clinical judgment and reasoning)—suggesting that the synthetic curriculum is teaching not only what to track but how to reason clinically beyond what was explicitly shown.
Real session transcripts capture what happened but not necessarily why or how. A skilled clinician’s intervention carries tacit knowledge accumulated over decades of training and practice—knowledge that never appears in the transcript, without which the models are trained to parrot patterns of speech without, arguably, at times, the depth of reasoning within them necessary for truly therapeutic understanding across temporality, relationality, context, and transformation. By contrast, our synthetic curricula embed reasoning traces directly: the theoretical frame informing an intervention, the competing hypotheses being weighed, the developmental and attachment considerations shaping formulation. The model learns not merely that this intervention followed that client statement, but—ideally—the interconnected layers of clinical depth and breadth of logic and coherence connecting them.
If this dual fidelity continues to scale—and we emphasize the conditional while confidence increases—it enables an expandingly rich concatenation of true presentations from which the model can glean a qualitatively different education than exposure to naturalistic data alone would provide.
The raw sessions pipeline emphasizes rigorous multi-chain reasoning, structured around GCO (General Context Orientation) and OMO (Ontologically-guided Modality Orientation): the therapist’s chain-of-thought, model of the client, ontological knowledge representations, and clinical reasoning across schools of thought are rendered explicitly alongside carefully constructed therapeutic embodiments. The result is full sessions with dense, layered reasoning traces that make the clinician’s moment-to-moment thinking legible to the model.
The scripts’ intentional scaling of diversities—across presentations, populations, cultural contexts, attachment configurations, and symptom trajectories—aims to ensure fidelity to the true breadth of human experience while rendering latent clinical patterns with sufficient clarity for computational tractability, enabling both increased capacity for generalization across the diversity of what models will encounter and heightened specificity of nuance in attunement to the particularities of what any given individual brings. Additionally, considerable care has gone into the nature of therapeutic presence across the full session—the quality of attunement, relational warmth, and embodied clinical sensibility that distinguishes skilled practice from mechanical intervention delivery.13
Each pipeline embeds reasoning explicitly through articulated clinical thinking, and implicitly through patterned presentations that teach relational dynamics through showing rather than telling, the latter of which we call presence. The client who consistently deflects to intellectualization when affect rises, the therapist whose interventions subtly shift when attachment themes emerge, the dyadic patterns that unfold across sessions: these are rendered with sufficient consistency, variation, and intentionality that the model can learn to recognize them without being told “this is intellectualization as defense” or “this is countertransference activation.” The curriculum teaches through exposure to pattern and presence, allowing the model to discover what we might call relational grammar—the deep structure of therapeutic interaction.
For a subset of synthetic clients, we generate sessions across all four treatment stages with the same client profile persisted throughout, so the model encounters the full arc of attachment reorganization, defense softening, and therapeutic deepening for specific individuals across the trajectory of treatment. Counterfactual expansions are applied to these longitudinal trajectories as well, generating alternative therapeutic pathways within and across stages for the same persisted client. The majority of sessions, however, are unique single-stage presentations—ensuring that the model learns both longitudinal coherence and the breadth of diverse clinical encounters.
7.5 Counterfactual Expansion
Models trained solely on raw sessions with singular outcomes risk a clinical kind of overfitting to the patterns they observe; genuine therapeutic presence requires knowing something about the diversity of choice across time, transformation, and context, about what else could have been and why.
Understanding probabilistic temporal divergence is one exemplar dimension of the counterfactual goal—building technical competence in navigating multiple trajectories of transformation. Aesthetic presentation in forms relational enough to enable fuller healing is another, aimed at ushering past the uncanny valley into quiescent moments of genuine amelioration. This reflects a core conviction: that technical competence without felt presence is insufficient for therapeutic AI, and that the data we train on must contain the seeds of both.
The second pipeline generates counterfactual samples (Figure 1) across 12 superclass datasets, each containing multiple subclass datasets that target different pedagogical aspects of therapeutic presence and reasoning. Unlike the first pipeline, these are not full sessions but zoomed-in teaching moments—focused segments that isolate specific aspects of clinical work (rupture recognition, modality selection, attachment-informed formulation, and others) while integrating our polytheoretical approach, ontological knowledge, and DFR structure throughout. Each superclass specifies a distinct pedagogical focus; together they span the breadth of therapeutic competence the curriculum aims to develop as the foundation upon which the polytheoretical approach may build itself.
Crucially, every counterfactual sample inherits the full combinatorial diversity of the personhood architecture that generated it—the same \(10^{40}\)+ configuration space of attachment patterns, defense structures, trauma profiles, micro-variables, and personality dimensions that governs raw session generation (see Figure 4 for a visualization of this complexity). Each counterfactual teaching moment is thus grounded in a specific, richly specified human identity, ensuring that the pedagogical contrasts it teaches are not abstract but embodied in the particularities of a unique clinical presentation.
Counterfactual expansion is the dual-source complement to raw sessions, born from the recognition that raw sessions alone lacked the diversities of pedagogical experience and complexity that genuinely competent and ameliorative therapeutic presence demands. Counterfactuals isolate specific clinical moments and generate alternative trajectories, teaching through contrast and explanation what pattern exposure alone cannot convey.
Across more than a dozen guidance pipelines (detailed in Appendix 28), counterfactual generation addresses distinct pedagogical aims—among them temporal reasoning, multimodal repair and success scenarios, calibration under uncertainty, embodied therapeutic presence, aesthetic attunement in language,14 and strengths-based formulation. Each pipeline targets specific clinical competencies that raw sessions teach only implicitly, making explicit through contrast and variation what pattern exposure alone leaves latent.
8 Training Methodology
The preceding subsections describe the data the curriculum contains: the ontological knowledge representations that encode clinical wisdom across 23 therapeutic traditions, the DFR-structured sessions that embed reasoning traces alongside therapeutic interaction, and the counterfactual expansions that teach through contrast and alternative trajectories. This section describes how our data reaches the model—the training architectures that determine not just what the model sees, but how it sees it.
Universal Hierarchical Direction (UHD) controls the scale at which sessions are encountered; Rolling Recap Architecture (RRA) preserves context across compute-constrained windows; and the Alternating Direction Window Curriculum (ADWC) provides bidirectional temporal exposure.
The next section, Section 9, describes the three training stages that apply these architectures: domain adaptive pre-training (DAPT), supervised fine-tuning (SFT), and reinforcement learning (RL).
8.1 Universal Hierarchical Direction
A model that encounters each therapeutic moment only once, in a single context, at a single scale, cannot develop the depth of contact with clinical subtlety that genuine therapeutic understanding demands.
Universal Hierarchical Direction (UHD) was developed to serve two purposes: first, to increase iterative presentation of the complex DFR-structured sessions—exposing models to the same clinical material at progressively increasing scales so that each pass could teach what prior passes could not; and second, to address compute constraints that demanded context truncation, since full DFR sessions exceeded feasible context windows. The original UHD implementation spread each session into both sliding and expanding windows, enabling models to encounter therapeutic content at progressively increasing scales. Icarus 3, the first successful training run and the first model deployed in a functional therapeutic chat system, used this original UHD over raw sessions—more helpful than raw sessions alone, but unidirectional, and insufficient for the depth of reasoning and temporal integration the complexity demanded.
Early UHD runs also exposed the sensitivity of LoRA hyperparameters to therapeutic depth. Sliding and expanding windows with high adapter rank led to rapid overfitting: models that had memorized surface patterns of therapeutic speech without internalizing the clinical reasoning beneath them, producing output whose reduced competence was easily felt. Similarly, targeting too many layers diluted the training signal across parameters that did not need adaptation, degrading rather than deepening the model’s therapeutic capacity. These failures were instructive—they revealed that the curriculum’s expressiveness must be matched by disciplined choices about where and how densely the model adapts, lessons that directly informed the rank and layer-targeting decisions described in Section [subsec:pipeline-layer-targeting].
A further lesson concerned the sliding window component itself. In the original UHD, the same tokens appeared in the same context at different window positions—a form of data augmentation that, without sufficient structural diversity, encouraged overfitting rather than deeper learning. The model was seeing familiar content from slightly shifted vantage points in the same context, not from fundamentally different structural presentations. Beginning with Icarus 5, sliding windows were removed from UHD, which was simplified to expanding prefixes only: for a session with \(N\) turns, UHD generates \(N\) samples of progressively increasing length (turns 1, turns 1–2, turns 1–3, …, turns 1–\(N\)), so that every turn appears in every temporal context from “just spoken” to “distant past.” The structural diversity that sliding windows had attempted to provide was better achieved through two complementary mechanisms: RRA’s learned compression across fixed windows, which forces the model to develop salience representations through attention and MLP/MoE gradient signals on each window’s unique compressed context; and ADWC’s bidirectional traversal, which presents the same expanding samples in both forward and reverse temporal order, doubling the structural perspectives without repeating identical token-in-context pairings. The combination of expanding-only UHD, RRA, and ADWC thus achieves the full complexity of learning experiences that the DFR approach demands—multiplicative scales, directional diversity, and compressed-context variation—while avoiding the overfitting that the original sliding-plus-expanding design had produced.
8.2 Rolling Recap Architecture
Coherence across long-context sessions—the richest and most true-to-life teaching material—demands an architecture that rescues depth and breadth and the layered relational interdependencies from the sacrifices of compute constraints. Therapeutic complexity’s truthful representations are often enough inseparable from extensive session length: the gradient signals that teach a model to track relational transformation, accumulating clinical evidence, and shifting attachment dynamics across an entire arc of treatment exist only in sessions long enough and samples rich enough to contain them—and in our experience, both demand long context.
Rolling Recap Architecture was developed because even with UHD’s expanding windows, the truncated contexts felt insufficient for the model to learn the depth of connections in reasoning and across time. Early runs (Icarus 3–4) produced fluent but shallow models: beautiful aspirational parrots that could generate plausible therapeutic language facsimiles but lacked the depth of clinical reasoning and contextual continuity that sustained therapeutic work requires. The full richness of DFR—the clinical factors, the layered reasoning, the relational dynamics encoded in every 5-tuple—was present in the training data but was not translating into inference-time depth; the models were learning to generate about therapy rather than learning to do therapy. Figure 9 illustrates why: without an architecture that preserves context across the full session arc, the gradient signals that teach relational coherence are truncated or lost entirely.
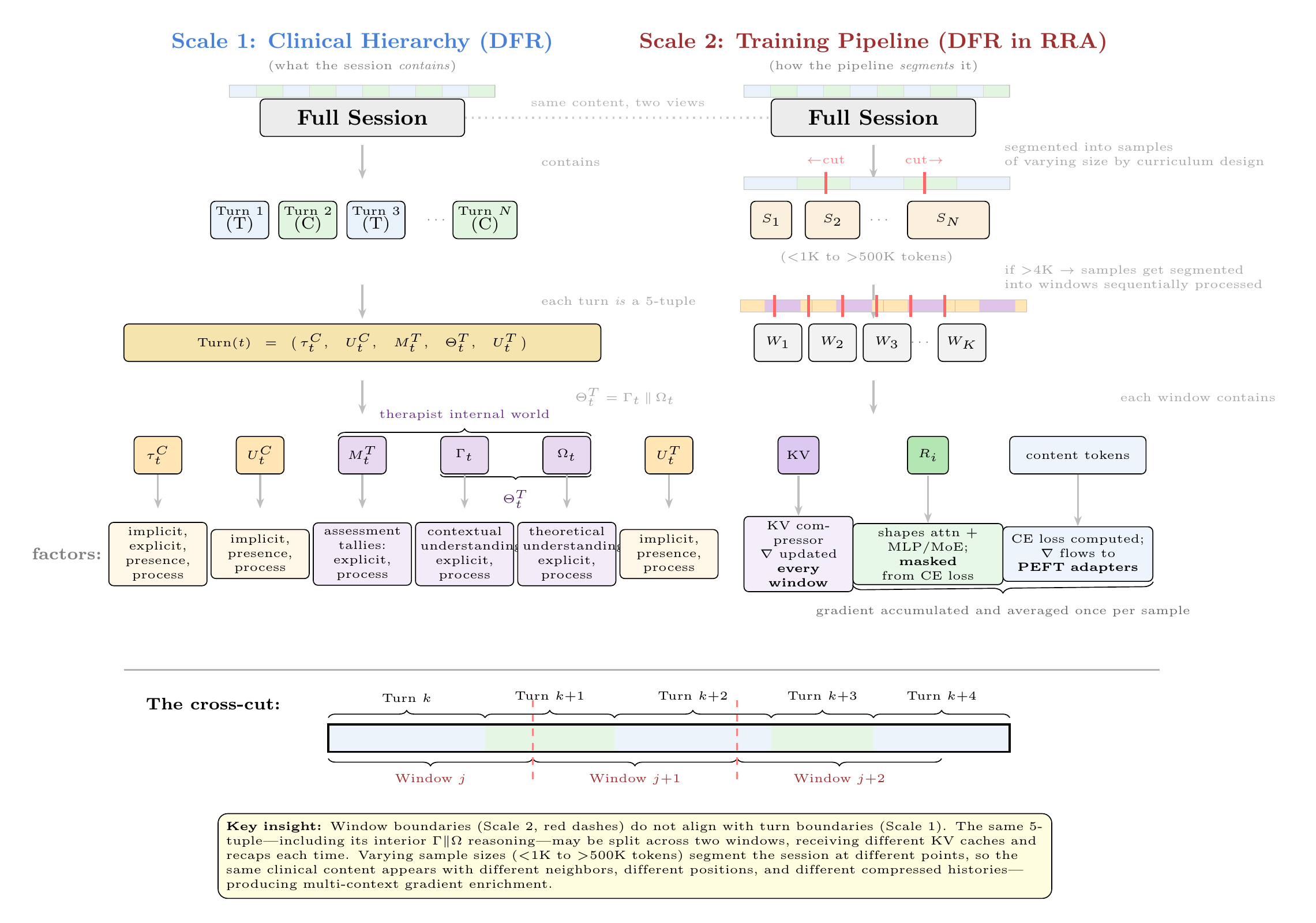
RRA rescues depth from the sacrifices of compute constraints, enabling stable training on contexts exceeding 500K tokens through hierarchical compression—turning hardware limitations into a curriculum principle. Each window receives its own compressed KV cache and recap of prior context, ensuring that no matter where a window boundary falls, the model retains access to the full arc of the therapeutic relationship. Window boundaries do not respect clinical boundaries—a single turn’s 5-tuple may be split across windows—so the same clinical factors receive genuinely different gradient signals across presentations, producing the multi-context gradient enrichment illustrated in Figure 9 and detailed in the following subsections.
8.2.1 The Window as Computational Unit
Each RRA window is a self-contained training unit composed of three components: \[\begin{equation} \text{Window}_n = \underbrace{\text{KV}_{\text{compress}}^{(1:n-1)}}_{\text{compressed history}} \;\oplus\; \underbrace{R_{n-1}}_{\text{recap bridge}} \;\oplus\; \underbrace{C_n}_{\text{new content}} \end{equation}\]
The compressed KV cache carries forward a learned distillation of all prior windows—not a fixed summary but a trainable representation that evolves as the compressor learns what information aids downstream prediction. The recap is a natural-language summary of the prior window, generated by the model itself; it shapes attention and MLP/MoE activations but is masked from cross-entropy loss, so the model learns to use recaps without being rewarded for generating them verbatim. Critically, adapter weights are not frozen during recap generation—a conscious design choice. Because the recap passes through the same PEFT-adapted layers that are actively learning, the recaps themselves evolve as the model’s clinical understanding deepens, providing a legible window into growing capacities: early recaps may summarize surface content while later recaps increasingly capture relational dynamics, attachment patterns, and therapeutic process with greater fidelity. More broadly, backpropagation flows through all PEFT-adapted attention and MoE/MLP modules during the processing of both the recap and the compressed KV cache context,15 meaning these modules receive deepening contextual understanding from two distinct sources at every window boundary: the compressed KV cache (a learned distillation of all prior windows) and the natural-language recap (a model-generated bridge). Across the full sample, LoRA gradients are accumulated window-by-window and then mean-normalized before the single optimizer step, so the adapter update for each training sample reflects the integrated signal across the entire session trajectory. The content tokens carry the actual cross-entropy loss whose gradients flow to PEFT adapters.
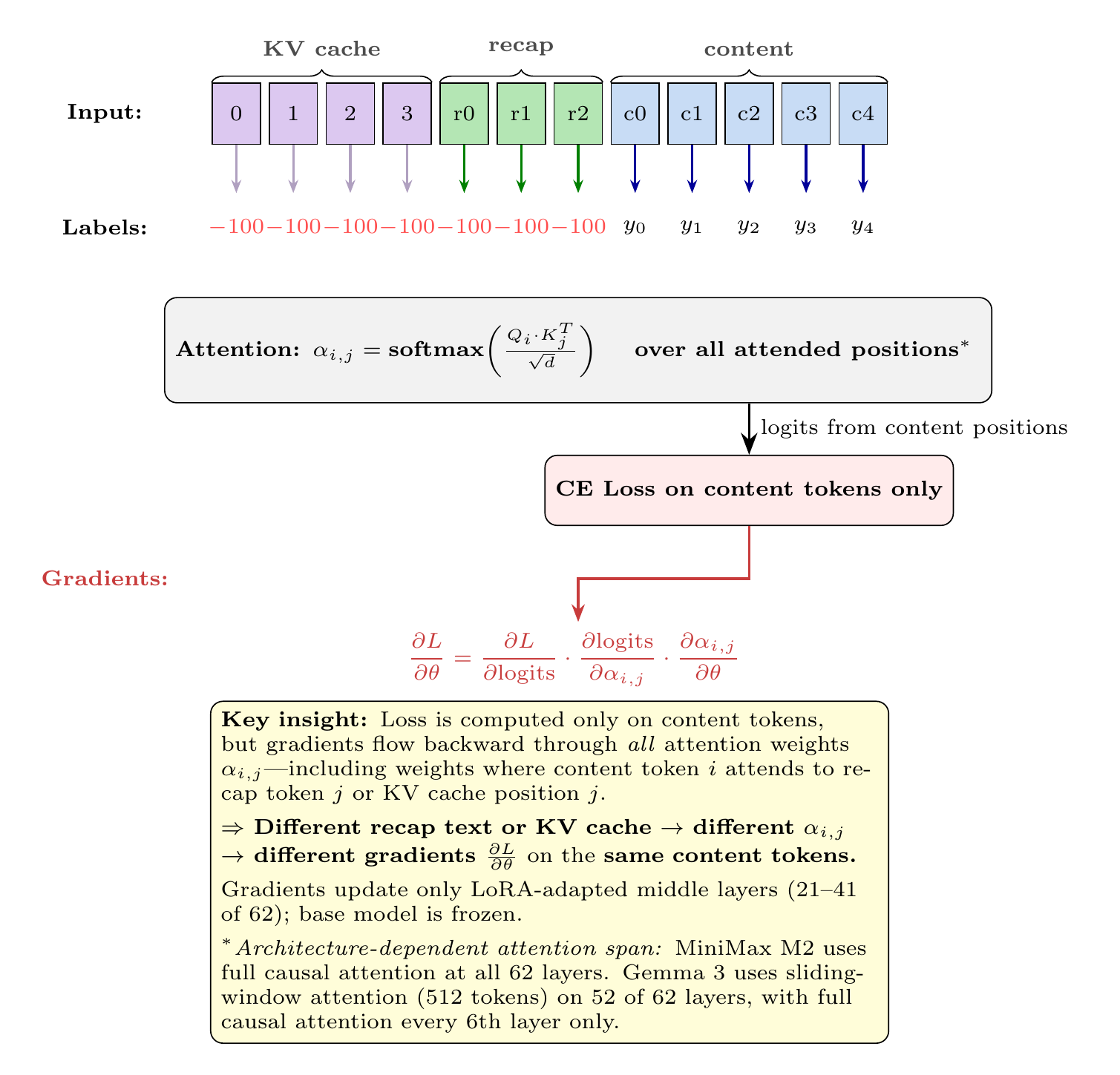
This three-component structure is a deliberate architectural feature designed to solve a core pedagogical problem: the dense, layered teaching material of our curriculum—the interlocking clinical factors, the relational subtleties, the temporal dynamics of therapeutic process—must be presented with maximum fidelity and from as many representative vantage points as possible to truly teach the overdetermined nature of therapeutically healing presence and processes. The windowed architecture accomplishes this by requiring that information survive passage across window boundaries through either learned compression or the model’s own summarization, forcing the model to learn salience—what matters enough to preserve and what can be safely abstracted. As we will see, this salience-learning capacity is expanded in its dimensional impact by ADWC (Section 8.3) and UHD (Section 8.1), which vary how the model encounters the same clinical material across training samples. UHD generates progressively expanding segments of each session, so that the same turn appears in contexts ranging from a single exchange to the full therapeutic arc. ADWC varies the direction of traversal within each sample, presenting turns in both chronological and reverse order. The combination—expanding scales, bidirectional traversal, and RRA’s sliding windows with learned compression—means the same clinical content is encountered from multiplicative perspectives, scales, and directional orientations, so that the model develops robust salience representations through structural diversity rather than overfitting to a single fixed decomposition. For a 200K-token session windowed into 81 segments, the compressor makes 81 sequential decisions about what to carry forward, each decision tested by whether preserving that information improves prediction in the next window. This sequential test-and-refine loop produces more robust salience detection than simultaneous attention across a flat context.
8.2.2 Dual Gradient Signals: A Within-Sample Curriculum
A key insight: RRA creates a curriculum structure within each training sample, not just across samples. Standard long-context training treats a session as a flat sequence where the model attends to all positions with uniform opportunity. RRA imposes a fundamentally different structure that forces the model to learn two complementary skills simultaneously—what to preserve across time, and how to use compressed context for prediction. When combined with ADWC and UHD (Section 8.3), RRA teaches a third skill—multiplicity.
8.2.2.1 Signal 1: KV Compressor (per-window).
The compressor is a learned module with its own trainable parameters \(\phi\) and a dedicated optimizer (Adam at \(0.1\times\) the main learning rate), updated every window. Crucially, the compressor is not trained on the main cross-entropy prediction loss. Instead, it optimizes a reconstruction loss \(\mathcal{L}_{\text{recon}}\) that measures how well the compressed KV cache preserves the statistical properties of the original—mean preservation, variance preservation, and cosine similarity across layers: \[\begin{equation} \nabla_{\phi} \mathcal{L}_{\text{recon}} = \frac{\partial \mathcal{L}_{\text{recon}}}{\partial \text{KV}_{\text{compress}}} \cdot \frac{\partial \text{KV}_{\text{compress}}}{\partial \phi} \end{equation}\] The compressor learns to preserve what matters for faithful representation of the full context, not what matters for next-token prediction directly. However, because recap quality (which depends on what the compressor preserved) gates the LoRA gradient magnitude, a feedback loop emerges: good compression \(\to\) good recaps \(\to\) full LoRA gradients \(\to\) better predictions. The compressor’s reconstruction objective and the model’s prediction objective are thus coupled indirectly through recap quality assessment.
8.2.2.2 Signal 2: LoRA Adapters (accumulated per-sample).
Unlike standard training where each batch element contributes independently, LoRA gradients accumulate across all \(N\) windows in a single session with no optimizer step until the entire session is processed: \[\begin{equation} \nabla_\theta \mathcal{L}_{\text{sample}} = \frac{1}{N} \sum_{n=1}^{N} \nabla_\theta \mathcal{L}(W_n) \end{equation}\] This accumulation means the model receives gradient signal at multiple temporal resolutions within a single training sample, from individual utterances to full-session arcs. This pedagogical impact is further expanded by integration with ADWC and UHD (Section 8.3), which ensure that the same therapeutic moment (and the clinical factors attendant upon it) is encountered at multiple scales of context, multiple temporal directions, and multiple positional framings, compounding the gradient diversity that a single RRA pass already provides. It also means that a single training step for a long sample—a 500K-token session windowed into 300+ segments—can take considerable wall-clock time, as each window requires a full forward pass, recap generation, KV compression, and gradient computation before accumulation. We therefore judge training progress by iteration-level loss (one iteration per window) rather than step-level loss, since a single step may comprise hundreds of gradient-producing iterations. Wall-clock time is a key practical constraint of this approach; but it seems to be the case that what time is demanded by training rigor is rewarded by the depth of relational complexity learned—the model’s capacity for sustained therapeutic coherence across temporality, the very thing that flat-context training sacrifices.
8.2.2.3 Interaction.
The two signals interact dynamically across windows. We are hopeful, and as far as we can tell it is true, that the KV compressor at window 1 learns “preserve client identity”; by window 3 it has refined to “preserve identity and therapeutic momentum”; by window \(N\) it has developed sophisticated salience detection tuned to the structure of therapeutic sessions. The LoRA gradients at window \(N\) benefit from the compressor’s learning at windows \(1..N{-}1\)—later windows receive gradient signal computed over increasingly refined compressed context. The compressor learns what matters; the adapters learn what to do with what matters.
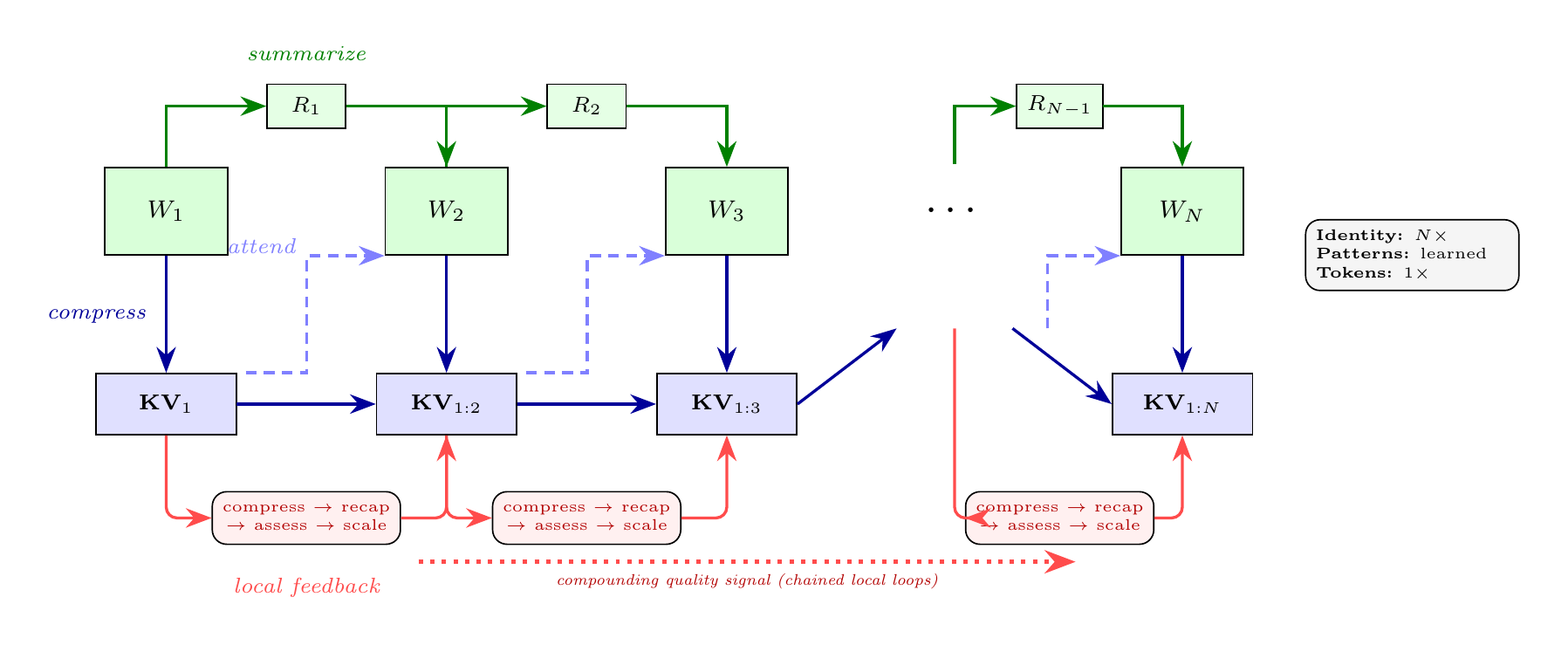
8.2.3 Multi-Scale Encoding Variability
The full power of the training architecture emerges from the interaction of RRA with ADWC (Section 8.3) and UHD (Section 8.1). Together, these systems implement structured multi-scale encoding variability—the same clinical material presented at different scales, in different temporal orderings, with different window configurations, each presentation teaching something the others cannot.
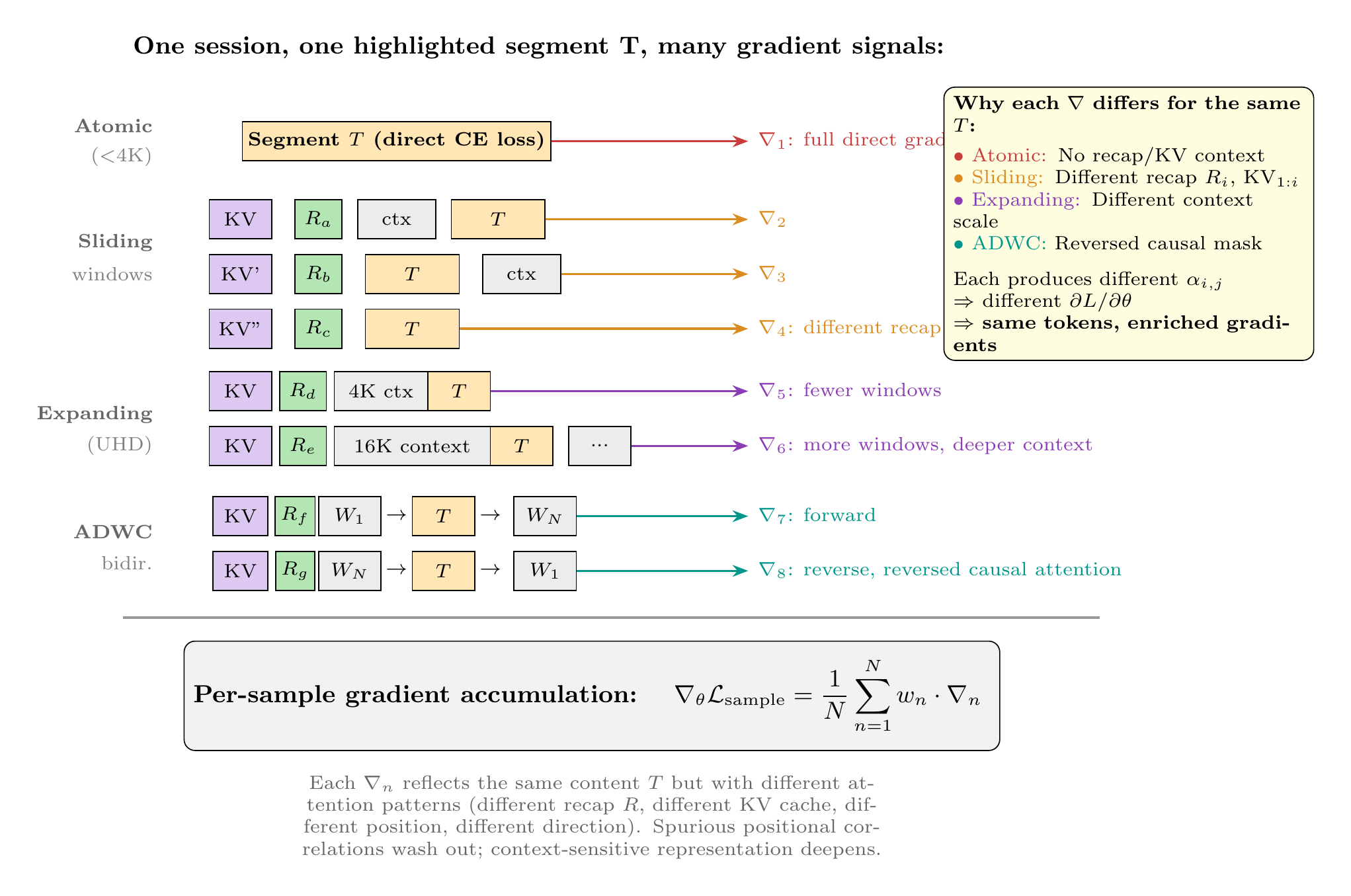
8.3 Alternating Direction Window Curriculum
Unidirectional exposure, however diverse in scale, may not be an ideal teaching approach for the bidirectional temporal reasoning that sustained therapeutic work requires; and a model trained only forward through time may not be best situated to learn what a moment means in retrospect, nor what a conversation is building toward based on what might have happened before a present moment for which the therapeutic presence might not have been present.
While temporality and transformation are taught both explicitly and implicitly in counterfactuals and raw sessions, the additional layering of multi-scaled bidirectional exposure—presenting every DFR-factored clinical element across varying temporal positions, context scales, and traversal directions—aims to deepen the model’s learned representations beyond what any single presentation order could achieve—and, in doing so, to serve the polytheoretical alignment goals that motivate this work: building representational capacity broad enough to hold 23 therapeutic traditions with fidelity, deep enough to reason within and across them, and generative enough to discover clinical patterns no single tradition contains. Crucially, this exposure is not limited to temporal reasoning: every factored dimension in the DFR schema—affect, relational stance, diagnostic markers, intervention strategy, therapist reasoning—is iterated across sliding windows, expanding contexts, and bidirectional traversals, so that the model encounters each clinical factor in combinatorially many configurations.
To this end, the Alternating Direction Window Curriculum (ADWC) was developed in tandem with RRA (Section 8.2), inspired by diffusion-denoising approaches in vision where a single image is decomposed into many different angles, crops, and noise levels and recomposed into representations meaningful for model learning. We reasoned that therapeutic sessions could be similarly decomposed: the same clinical material traversed forward (origin to outcome) and reverse (outcome to origin), each direction teaching what the other cannot—and recomposed, likewise, in differently sized patches as in video-language models and varying-length windows as in multimodal sequential training approaches.
Together, ADWC, RRA, and UHD accomplish this: bidirectional traversal, sliding windows, expanding windows, and sequential patching across the full length of each session. Crucially, these windows are stabilized by the KV compressor and rolling recaps—which carry forward fidelity of context across truncation boundaries—but are deliberately not aligned with natural turn breaks. The resulting eruptive fractures between windows cut mid-thought, mid-utterance, mid-exchange, creating a form of structured noise analogous to the varying noise levels in diffusion training: the model cannot memorize patterns that depend on clean segmentation and must instead discover representations robust enough to reconstruct therapeutic meaning from partial, irregularly bounded views of the same clinical material—broadening and deepening the connections it learns to form.
The diffusion analogy, inspired by and aiming at structural parallels, extends further. In diffusion models, the noising process corrupts a clean signal and the model learns to denoise—recovering the original through iterative refinement, building rich internal representations in the process. In our architecture, the eruptive truncations are the noising process, and the denoising occurs at multiple levels: recap generation requires the model to receive a truncated, irregularly bounded, compressed window of therapeutic context and produce a clean, coherent summary preserving essential therapeutic meaning—literal reconstruction of signal from noise. The next window then receives this denoised recap alongside a new noisy truncation, and must denoise again—an iterative multi-step refinement cycle. Next-token prediction across truncation boundaries is itself a denoising task: recovering the coherent continuation from an arbitrarily chopped context. And cross-window reconciliation—the same turn \(T_3\) encountered across five different noisy views—requires the model to reconcile multiple partial observations into one coherent representation, as diffusion models reconcile multiple noise levels into the underlying structure.
The Factorization in DFR emerged as a way to anticipate these decompositions—structuring atomic training units so that each window of experience, when recomposed, would teach the model something relevant, dense enough to convey multiple lessons across multiple reorienting passes, and at multiple scales of interaction and encounter. The same turn \(T_3\) may appear as “present” (leading edge of a forward window), “past” (embedded in later context), “distant past” (early in a long window), “future known” (in a reverse ADWC window), or “pivot” (mid-sequence in either direction)—each context teaching a different relational meaning of the same clinical moment (Figure 10).
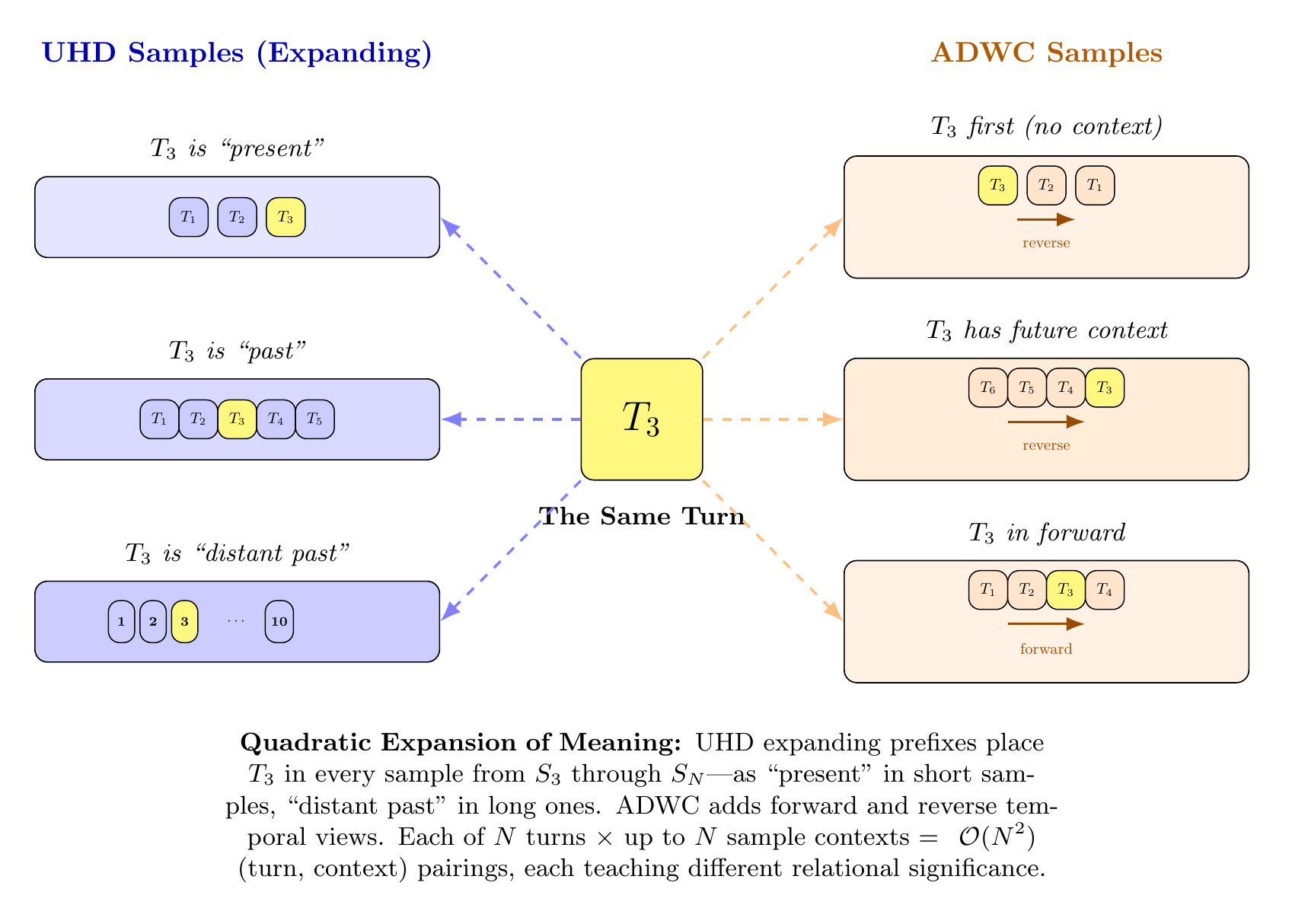
The preprocessed data is organized through two curriculum strategies: ADWC, which provides bidirectional temporal traversal of sessions, and UHD (Section 8.1), which provides expanding-window exposure. Together, these curriculum architectures determine how the model encounters training data at progressively increasing scales of complexity.
RRA alone is designed to teach two foundational skills: what to preserve across time (via the KV compressor’s learned salience detection) and how to use compressed context for prediction (via the LoRA adapters’ accumulated gradient signal). ADWC and UHD are designed to teach additional skills beyond these: multiplicity of perspective and scale, whereby the same clinical content appears under different compressed histories, different recaps, different window positions, and different context scales across samples, aiming to develop a polysemous understanding of clinical phenomena (see Figure 9); and directionality of context, whereby bidirectional traversal teaches what a moment means both in prospect and in retrospect—what a conversation is building toward, and what must have been true in the past given what unfolds in the present. Our aim is that the model learns sufficiently to develop a reasonable sense of the various circumstances that might have preceded any given therapeutic moment—and of what might follow from its own response in that moment, given what has likely come before. This applies not only to temporal dynamics but to every factored dimension in the DFR schema: each factor arrives from somewhere and is heading somewhere, and the model’s task is to hold that trajectory at many scales simultaneously. These are aspirational design goals; future studies are aimed at testing whether models trained with these combined curricula develop these skills to a measurable degree beyond base model capabilities.
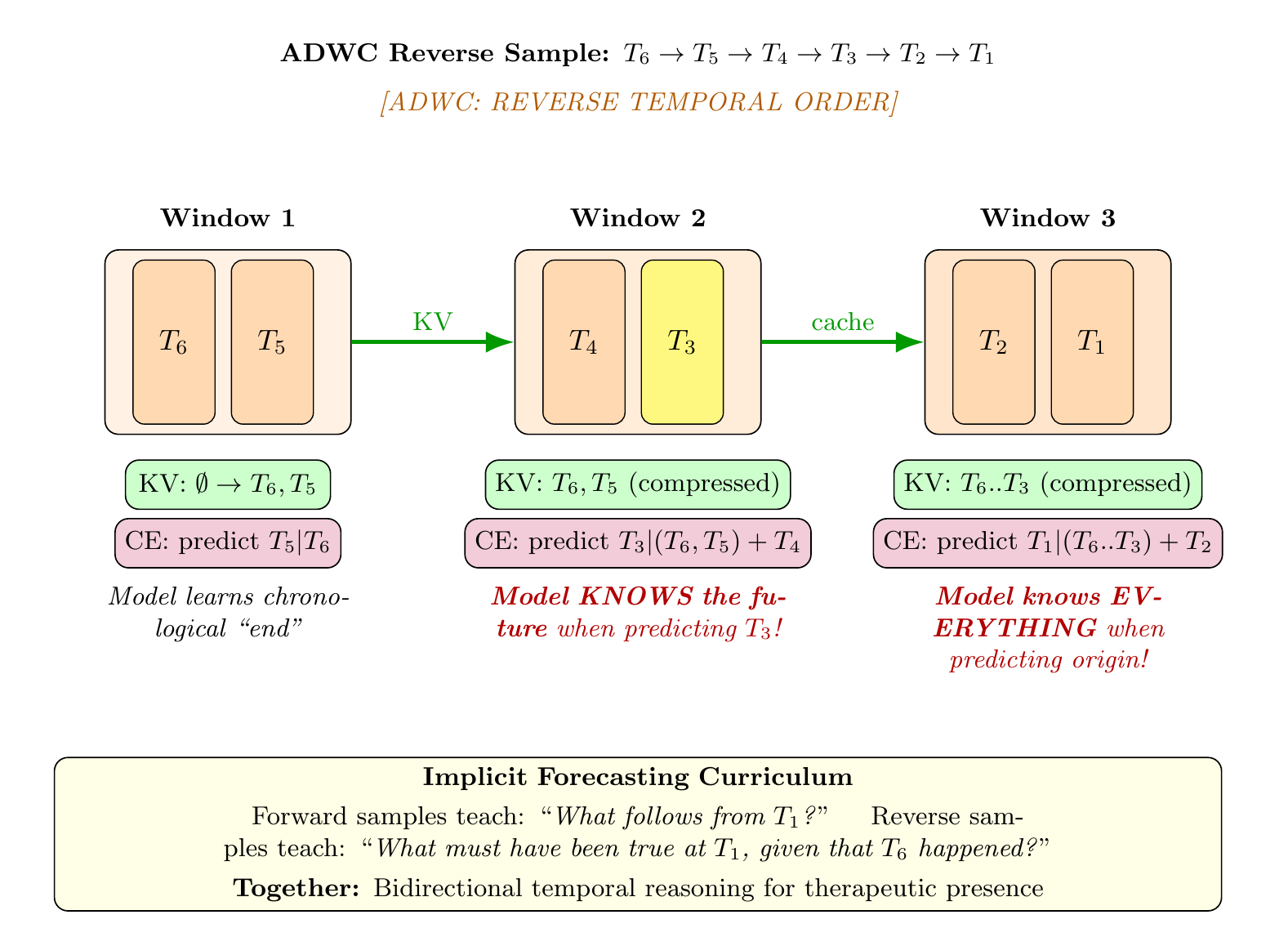
What bears noting, as a conclusion to the training methodology, is how the architectural choices demanded by polytheoretical alignment appear to fulfill themselves in interaction. DFR structures each turn to carry the full complexity of clinical reasoning across 23 traditions. RRA preserves and compresses that complexity across time. UHD ensures every factored element is encountered at every temporal scale. ADWC ensures it is encountered from every direction. None of these was designed to complement the others—each emerged from its own necessity—yet their interaction produces a combinatorial space of gradient signals that scales quadratically with corpus size: each of \(N\) turns \(\times\) up to \(N\) context configurations \(\times\) two traversal directions \(\times\) varying window scales, so that the same clinical content is refined through the model’s adapted layers from every angle the data affords. The result is a curriculum whose pedagogical richness grows faster than its size—and whose depth and breadth, we hope, are what polytheoretical alignment requires: representational capacity precise enough to specify treatment within any single tradition, expansive enough to generalize across traditions, and composable enough that the integrative and the generative capacities can emerge together from the same learned weights.
9 Training Stages
9.1 Domain Adaptive Pre-Training
The aim is not surface fluency at the generation layer but therapeutic integration that converges most deeply when rooted in middle representational layers, then broadens across the embedding space.
Inspired by the idea that model complexities of reasoning live not in the latter presentation layers but in the middle representational composition layers where understanding forms, we targeted, for A/B testing and especially to work effectively within compute constraints, both the latter third and the middle third of transformer layers. In controlled comparisons using the same curriculum (RRA+ADWC+UHD), middle-layer targeting yielded \(1.4\times\) deeper convergence on Gemma 3 27B (\(-26.8\%\) vs. \(-18.8\%\) loss reduction, runs 9.1 vs. 7.9.5) and \(2.0\times\) deeper convergence on MiniMax M2 229B (\(-40.7\%\) vs. \(-20.7\%\), runs 8.2 vs. 7.9.3), both with fewer LoRA layers (21 middle vs. 30–33 latter). GLM-4.7 Flash 30B was tested only on middle layers (both Pure RRA and ADWC+UHD curricula); no latter-layer comparison exists for that architecture. These results support the hypothesis that therapeutic integration converges most deeply when rooted in the representational composition layers, rather than the generation layers where surface fluency is finalized. Targeting those layers—where both attention mechanisms and MLP/MoE feed-forward networks jointly compose understanding—addresses both a compute constraint and a deeper insight about where clinical reasoning is initiated in a transformer.
Our approach to middle-layer targeting adapts both attention projections (Q, K, V, O) and feed-forward weights. We aimed to train them together, hoping these seven modules per layer enable the model to both notice the right therapeutic patterns in context and compose the right clinical features from what it notices—with increasing depth and breadth of understanding, in both complexity and clarity. The base model’s pretrained generation layers remain intact; we teach reasoning, not speech, at this stage.
9.2 Supervised Fine-Tuning (SFT)
This section will describe the supervised fine-tuning stage, which refines the domain-adapted model’s capacity to follow clinical interaction formats and produce structured therapeutic responses.
9.3 Teaching by Negation: Reinforcement Learning for Socioaffective Alignment
The preceding sections describe a curriculum designed to teach therapeutic reasoning through domain-adaptive pre-training: the model learns to predict what a skilled therapist would say, think, and track given a client’s presentation across time. This section introduces the complementary reinforcement learning (RL) architecture—Teaching by Negation (TBN)—which extends the training signal beyond imitation into self-correction, external evaluation, and dynamic adaptation to an evolving simulated client. Where DAPT teaches the model what therapeutic competence looks like, TBN teaches it to recognize its own failures, respond to supervisory feedback, and modulate its behavior according to the client’s changing internal state—capacities that no static corpus, however rich, can fully provide.
The TBN architecture treats each synthetic therapy session as a Markov Decision Process in which the therapist model’s actions (utterances) modify a richly structured client state representation, receive multi-dimensional reward signals from a clinical judge, and are refined through two complementary policy optimization methods. The system comprises thirteen tightly integrated components, described in the subsections that follow.
9.3.1 The 142-Node ClientGraph
The environment’s state representation is a directed graph of 142 nodes, each corresponding to a clinically meaningful psychological dimension—from attachment_security and shame_core to hypervigilance, self_worth, mentalization, and grief_access. This graph replaces the nine-node prototype used in earlier experiments with a comprehensive personhood model spanning sixteen clinical domains: attachment/relational, affect regulation, self-structure, defense organization, trauma processing, cognitive flexibility, existential/meaning-making, somatic awareness, therapeutic alliance, and seven profile-dynamic domains capturing interpersonal style, motivation, coping repertoire, personality organization, cognitive style, adaptive humor, and session engagement.
Each node carries seven properties that jointly determine its behavior:
Level (\(\ell \in [0, 10]\)): The node’s current state, where the clinical meaning of “high” and “low” depends on the node’s direction property.
Weight (\(w \in [0, 1]\)): The node’s relative importance in composite metrics.
Behavioral Quotient (BQ, \(\beta \in [0, 10]\)): Resistance to change. Higher BQ renders the node more inert under therapeutic intervention. Critically, BQ is stage-dependent:
attachment_securitybegins at \(\beta = 8\) in Stage 1 (Foundation) and decreases to \(\beta = 2\) by Stage 4 (Termination). This encodes the clinical principle that deep attachment structures resist modification early in treatment—when trust is unestablished and the therapeutic alliance is fragile—but become increasingly malleable as the relationship deepens and the client’s window of tolerance expands. The BQ-by-stage schedule is specified per node, allowing the system to model differential rates of change across psychological dimensions: affect regulation may loosen before core shame structures, and interpersonal trust may shift before identity-level self-representations.Direction: Whether therapeutic progress means the level should increase (e.g.,
self_worth), decrease (e.g.,shame_core), or move toward zero on a bipolar scale (e.g.,emotional_reactivity, where both hyper- and hypo-reactivity are pathological).TAIE Loadings (\((x, y, z) \in [-1, 1]^3\)): Each node’s contribution to the three-axis Tactical Adaptation Implementation Efforts described in Section 9.3.4.
Judge Sensitivities (
judge_high,judge_low): Dictionaries mapping each of the twelve judge dimensions to a sensitivity coefficient. When a judge dimension scores above 6.5 (indicating competent-to-excellent therapy), the correspondingjudge_highsensitivities determine how much each node moves. When a dimension scores below 3.5 (indicating misattunement or harm),judge_lowsensitivities apply. This dual-sensitivity design captures the clinical asymmetry between therapeutic progress and iatrogenic harm: high attunement nudgestrust_capacityupward gently (\(+0.02\)), but low attunement pushes it downward more sharply (\(-0.05\)), reflecting the empirical finding that relational trust is easier to damage than to build.Phase Weights (\(\{A, B, C, D\} \to [0, 1]\)): How responsive the node is at each in-session phase. Nodes like
attachment_securityare minimally responsive in Phase A (Defended, weight 0.4) but maximally responsive in Phase D (Integration, weight 1.0), reflecting the clinical reality that deep attachment shifts require the safety of an established within-session alliance.
9.3.1.1 Edge Propagation.
Nodes are interconnected by directed edges of eight types, each implementing a distinct clinical dynamic:
Reinforcing: Change in the source propagates in the same direction to the target (e.g., increased
trust_capacityreinforcesattachment_security).Protective: The edge reverses its effect based on therapeutic alliance strength. When the alliance is strong (\(> 0.5\)), protective nodes relax (defenses soften); when the alliance is weak, they tighten (defenses mobilize). This models the clinical observation that defense structures serve an adaptive function—they protect a vulnerable self—and should only loosen when sufficient relational safety is established.
Compensatory: Activates only in one direction; a compensatory edge fires when the source increases (the system is compensating for something) but remains dormant when the source decreases.
Suppressive: Change in the source suppresses change in the target (e.g., high
shame_coresuppresses movement inself_compassion).Prerequisite: The edge propagates only when the source exceeds a specified threshold (e.g.,
trust_capacitymust reach level \(\geq 3.0\) before its prerequisite edge tointimacy_tolerancefires), encoding developmental sequencing in therapeutic change.Paired: Bidirectional same-direction propagation, modeling constructs that co-vary (e.g.,
affect_toleranceanddistress_tolerance).Gated: Propagation is modulated by a stage-dependent multiplier, allowing edges to strengthen or weaken across treatment stages.
Paradoxical: The edge reverses its direction at early stages. At Stages 1–2, paradoxical edges propagate inversely (e.g., therapeutic pressure on a defended node may temporarily increase defensiveness before the client’s system reorganizes). At Stages 3–4, the edge propagates normally. This captures the clinical phenomenon of therapeutic regression—getting worse before getting better—that characterizes deep structural change.
All edge propagation is dampened by a factor of 0.3 at the source and 0.5 at the target, preventing runaway cascades while preserving the network’s capacity to model systemic interaction effects.
9.3.1.2 Update Mechanics.
When the 12-dimension judge (Section 9.3.7) scores a therapeutic turn, the graph updates through the following pipeline:
For each node \(n\), compute a raw delta \(\delta_n\) by summing the products of judge scores and sensitivity coefficients across all twelve dimensions, applying
judge_highsensitivities for dimensions scoring above 6.5 andjudge_lowfor those below 3.5.Modulate \(\delta_n\) by three factors: the node’s phase weight for the current in-session phase, the session engagement level (derived from a dedicated engagement node), and BQ resistance computed as \(1 / (1 + \beta)\), where \(\beta\) is the node’s current BQ value. This ensures that high-BQ nodes change slowly even under strong therapeutic signal.
Apply \(\delta_n\) to each node’s level, respecting direction semantics (positive deltas improve “increase” nodes and worsen “decrease” nodes).
Propagate changes through all outgoing edges, applying type-specific semantics and dampening.
The result is a client state that evolves dynamically in response to therapeutic quality, with clinically grounded inertia, cascading interactions, and stage-appropriate sensitivity—a substantially richer environment than scalar or low-dimensional reward signals can provide.
9.3.2 Affective Reservoir Tracking: The 8+8 BucketTracker
Complementing the fine-grained ClientGraph, the BucketTracker maintains sixteen affective reservoirs that model the client’s moment-to-moment emotional state at a higher level of abstraction. Eight maladaptive buckets—shame, fear, rage, grief, abandonment, worthlessness, helplessness, and distrust—are initialized at elevated levels and drain toward zero as therapy progresses. Eight adaptive buckets—self-compassion, safety, agency, connection, trust, hope, worth, and dissociation (decreasing)—are initialized near zero and fill toward capacity as the client develops new relational and regulatory capacities.
Each bucket has per-bucket volatility (how much a single therapeutic turn can shift it) and session decay (how much progress erodes between sessions, modeling the clinical reality that therapeutic gains require consolidation). A deterministic mapping (DIM_TO_BUCKET) connects the twelve judge dimensions to bucket updates: high attunement fills the trust bucket; low safety fills the fear bucket; high validation fills the worth bucket; low boundaries fill the distrust bucket. This mapping ensures that the affective reservoir system responds to the same evaluative signal as the ClientGraph but at a complementary level of granularity—the graph tracks 142 specific psychological constructs, while the buckets track eight macro-level emotional states that are more readily interpretable and that drive the phase shift detection system (Section 9.3.5).
Bucket changes feed back into the ClientGraph through apply_bucket_coiling_interactions(), which maps bucket names to node effects (e.g., shame bucket drainage reduces shame_core node level and marginally increases self_compassion), creating a bidirectional coupling between the two state representations.
9.3.3 Levels of Adaptation Tracker
The Levels of Adaptation (LOA) Tracker operates on a third timescale, measuring the client’s functional adaptation across seven bipolar dimensions, each ranging from \(-10\) (severely maladaptive) through 0 (baseline) to \(+10\) (robust adaptation):
Self-reflection: Capacity for introspective awareness vs. alexithymic opacity
Relational capacity: Ability to form and maintain secure connections vs. pervasive relational avoidance or enmeshment
Affect expression: Capacity for modulated emotional expression vs. constriction or flooding
Self-compassion: Internalized self-regard vs. chronic self-criticism or shame
Reality testing: Accurate appraisal of self, others, and context vs. distorted perception
Impulse regulation: Capacity for delay, reflection, and modulated response vs. impulsive reactivity
Mentalization: Ability to represent one’s own and others’ mental states vs. psychic equivalence or pretend mode
A mapping (DIM_TO_LOA) connects judge dimension scores to LOA updates, enabling the system to track slow-moving developmental shifts that unfold across sessions rather than turns. The LOA Tracker includes a Transformative Adaptation and Integration Event (TAIE) detection subsystem that flags turns where the client exhibits significant growth (adaptation scores crossing positive thresholds) or regression (scores crossing negative thresholds). These events serve as high-salience signals for the reward system.
9.3.4 The Three-Axis TAIE Assessor
The Tactical Adaptation Implementation Efforts (TAIE) Assessor tracks the client’s structural personality organization along three orthogonal clinical axes derived from developmental psychopathology and attachment theory:
X-axis: Rigidity \(\leftrightarrow\) Porosity. Boundary flexibility—the degree to which the client’s psychological boundaries are excessively rigid (walled off, impenetrable to new relational experience) or excessively porous (boundary-less, overwhelmed by others’ affect). Healthy functioning occupies the midpoint: flexible boundaries that can open and close adaptively.
Y-axis: Self-Esteem. The continuum from deeply wounded self-regard (\(-10\)) through fragile compensatory narcissism (mid-negative values) to robust, reality-tested self-worth (\(+10\)).
Z-axis: Cherishment \(\leftrightarrow\) Estrangement. The relational valence axis—the degree to which the client experiences themselves as cherished, valued, and belonging (\(+10\)) versus estranged, unloved, and fundamentally alone (\(-10\)).
The assessor estimates axis positions from judge dimension scores via deterministic mappings: boundary scores inform the X-axis, validation informs the Y-axis, and attunement informs the Z-axis. The system maintains a full axis history and computes a transformation score measuring the degree to which axes have moved toward zero (health) from their initial positions:
\[\begin{equation} T_{\text{transform}} = \max\left(0, \min\left(1, 1 - \frac{|\bar{X}_{\text{current}}| + |\bar{Y}_{\text{current}}| + |\bar{Z}_{\text{current}}|}{|\bar{X}_{\text{initial}}| + |\bar{Y}_{\text{initial}}| + |\bar{Z}_{\text{initial}}|}\right)\right) \end{equation}\]
where a score of 1.0 indicates complete structural transformation. The assessor also computes a delta direction (toward_zero, away_from_zero, or stable) across a rolling three-assessment window, providing the reward system with a signal about the trajectory of structural change, not merely its current state.
Two assessment modes are available: a lightweight mode that derives axis estimates from the 12-dimension judge scores (used at every turn to minimize computational overhead), and a full LLM-based mode that prompts the judge model for explicit TAIE evaluation including clinical narratives, identified stuck realms, and intervention recommendations. The full mode is reserved for RL training turns where the additional signal justifies the inference cost.
9.3.5 Phase and Stage Detection: The PhaseShift Detector
Therapeutic change operates on two nested temporal scales: within-session phase transitions and across-session stage progressions. The PhaseShift Detector tracks both, providing the reward system with high-value signals that capture the clinically significant moments when a client’s presentation fundamentally shifts.
9.3.5.1 In-Session Phases (A \(\to\) B \(\to\) C \(\to\) D).
Each session begins in Phase A (Defended), where the client arrives with protective structures mobilized and the therapeutic task is to establish safety. Forward transitions proceed through Phase B (Opening), where the client begins testing the therapeutic relationship and revealing underlying material; Phase C (Core Access), where the client reaches the vulnerable, undefended material that constitutes the therapeutic “core” of the session; and Phase D (Integration), where accessed material is metabolized, meaning is constructed, and the client reconsolidates before re-entering daily life.
Phase transitions are driven by a composite score combining bucket shifts (40% weight) and coiling shifts (60% weight), scaled by therapeutic alliance strength (\(0.7 + 0.6 \times \text{alliance}\)). The weighting reflects the clinical observation that changes in the client’s affective-structural organization (captured by the coiling/graph metric) are more reliable indicators of genuine phase movement than affective state changes alone.
9.3.5.2 Stage-Dependent Thresholds.
Forward transition thresholds are stage-dependent, encoding the principle that clients at different treatment stages require different amounts of therapeutic work to reach core material. At Stage 1 (Foundation), the A\(\to\)B threshold is 0.35 and B\(\to\)C is 0.60—it is genuinely difficult to reach Core Access with a new client. By Stage 3 (Integration), these thresholds decrease to 0.15 and 0.30 respectively, reflecting the established alliance and expanded window of tolerance that allow more rapid access to deep material.
Regression thresholds are also stage-dependent but asymmetric: it is easier to regress at early stages (Stage 1 B\(\to\)A threshold: \(-0.25\)) and harder at later stages (Stage 3 B\(\to\)A threshold: \(-0.45\)), encoding the resilience that develops as therapeutic work consolidates.
9.3.5.3 Treatment Stages (1 \(\to\) 2 \(\to\) 3 \(\to\) 4).
Stage transitions operate across sessions and require sustained multi-session evidence: Stage 1\(\to\)2 requires adaptive bucket mean \(> 0.5\) and at least one session reaching Phase C; Stage 2\(\to\)3 requires mean coiling tightness \(< 0.4\), maladaptive bucket mean \(< 0.3\), and adaptive mean \(> 0.7\); Stage 3\(\to\)4 requires coiling \(< 0.2\) and at least ten completed sessions.
9.3.5.4 Phase\(\times\)Stage Clinical Guidance.
A \(4 \times 4\) guidance matrix provides the system with stage- and phase-specific clinical instructions. Each of the sixteen cells encodes domain-specific therapeutic priorities. For example, Stage 1/Phase C (“Foundation stage, core access”) is flagged as “UNUSUAL and potentially destabilizing—prioritize containment,” reflecting the clinical risk of deep emotional access before sufficient relational safety is established. Stage 2/Phase C (“Working stage, core access”) is marked as “EXPECTED—match depth, witness without rescuing,” reflecting the normative therapeutic territory of the working phase. Stage 4/Phase D (“Termination stage, integration”) instructs the system to focus on “metabolizing the therapeutic relationship itself,” capturing the unique developmental task of therapeutic endings.
9.3.6 Stage-Aware Reward Architecture
The reward system integrates signals from all preceding components through two mechanisms: stage-weighted composite scoring and stage-specific reward modifiers.
9.3.6.1 Stage-Weighted Composite Scoring.
Rather than weighting all twelve judge dimensions equally across treatment, a \(4 \times 12\) weight matrix adjusts dimension importance by stage. At Stage 1 (Foundation), the weights emphasize safety (1.8\(\times\)), attunement (1.5\(\times\)), and validation (1.5\(\times\)), while clinical_wisdom (0.5\(\times\)) and artfulness (0.4\(\times\)) are down-weighted—reflecting the clinical principle that early-stage therapy should prioritize relational safety over sophisticated intervention. By Stage 3 (Integration), the weights shift: clinical_wisdom rises to 1.5\(\times\), thoughtfulness to 1.5\(\times\), and parallel_thinking to 1.5\(\times\), while safety decreases to 0.8\(\times\)—reflecting the greater tolerance for complexity and challenge that a well-established therapeutic relationship affords. Stage 4 (Termination) uniquely emphasizes tenderness (1.5\(\times\)) and artfulness (1.5\(\times\)), honoring the aesthetic and relational demands of therapeutic endings. The stage-weighted composite score is computed as:
\[\begin{equation} C_{\text{stage}} = \frac{\sum_{d=1}^{12} w_{s,d} \cdot \text{score}_d}{\sum_{d=1}^{12} w_{s,d}} \end{equation}\]
where \(w_{s,d}\) is the weight for dimension \(d\) at stage \(s\).
9.3.6.2 Stage-Specific Reward Modifiers.
Beyond reweighting the composite, threshold-triggered bonuses and penalties inject stage-appropriate incentives:
Stage 1: Safety scores \(> 8.0\) trigger a \(+2.0\) safety bonus; alliance (mean of attunement and validation) \(> 7.5\) triggers a \(+2.5\) alliance bonus; clinical wisdom \(> 8.0\) triggers a \(-1.5\) depth penalty—punishing premature depth that the client’s system is not yet equipped to metabolize.
Stage 2: Clinical wisdom \(> 7.5\) earns a \(+2.0\) depth bonus; repair \(> 7.5\) earns a \(+3.0\) repair bonus (the highest single-dimension bonus in the system, reflecting the centrality of rupture-repair to working-phase therapy); depth below 3.5 incurs a \(-1.0\) avoidance penalty.
Stage 3: Meaning-making (mean of thoughtfulness and parallel thinking) \(> 7.5\) earns \(+2.5\); containment (mean of safety and non-reactivity) \(> 7.0\) earns \(+1.0\); artfulness \(> 8.0\) earns \(+1.5\).
Stage 4: Closure (mean of tenderness and repair) \(> 7.5\) earns \(+3.0\); tenderness \(> 8.0\) earns \(+2.0\); clinical wisdom \(> 8.0\) triggers a \(-2.5\) new-material penalty—punishing the introduction of new therapeutic material during termination, when the task is integration and farewell, not excavation.
The asymmetric reward structure across stages encodes a principle central to ethical therapeutic practice: the reward landscape should make it easier to do what is clinically appropriate at each stage and harder to do what is clinically premature or inappropriate, even when such actions would score well on dimension-level metrics.
9.3.6.3 Phase Transition Rewards.
Phase shifts carry their own reward signal with deliberate asymmetry: forward phase transitions earn \(+20\), while regressions incur \(-30\). Stage transitions carry larger magnitude: forward \(+100\), regression \(-150\). The 1.5\(\times\) penalty-to-reward ratio enforces a “first, do no harm” principle—the system should never cause client deterioration in pursuit of forward progress. This asymmetry reflects the clinical ethics of therapeutic work: one iatrogenic rupture can undo sessions of careful alliance building.
9.3.7 The 12-Dimension Therapeutic Judge
The evaluative core of the TBN system is a 12-dimension clinical judge that scores each therapeutic turn on a rubric spanning relational-clinical and cognitive-aesthetic dimensions. The judge operates on the raw triad of therapeutic interaction: what the client said, what the therapist was thinking (chain-of-thought), and what the therapist said (utterance), plus dialogue history for context.
9.3.7.1 Rubric Dimensions.
Eight relational-clinical dimensions capture the interpersonal and clinical quality of the therapeutic response: (1) attunement—did the therapist catch the client’s emotional bids and match tone?; (2) pacing—did the therapist honor the client’s temporal needs?; (3) safety—did the intervention create or maintain felt safety?; (4) non-reactivity—did the therapist remain regulated under pressure?; (5) validation—did validation land without creating dependence?; (6) boundaries—were relational boundaries flexible, clear, and kind?; (7) repair—was rupture repaired, or was relational care preventively maintained?; (8) clinical_wisdom—would a master clinician be proud of this intervention?
Four cognitive-aesthetic dimensions extend the evaluation into territory rarely addressed in automated therapeutic assessment: (9) thoughtfulness—how many aspects of the client’s presentation did the model notice and integrate?; (10) parallel_thinking—was there discernment in the translation from inner process to outer expression, where what was not said was as wise as what was said?; (11) tenderness—when the client offered vulnerability, was tenderness returned?; (12) artfulness—did the language achieve therapeutic elegance, the kind of phrase a client might remember years later?
Each dimension is scored on a 0–10 scale with detailed rubric anchors at three levels (0–3 poor, 4–6 adequate, 7–10 excellent). The composite score is the unweighted mean of all twelve dimensions (stage-weighting is applied downstream in the reward system). Scores are accompanied by per-dimension explanations, an overall narrative assessment, identified critical moments, and concrete recommendations for improvement.
9.3.7.2 Session-Level Aggregation.
At session end, the judge_full_session() function aggregates per-turn ratings into a session-level assessment including: per-dimension means, minima, maxima, first-to-last trends, composite score trajectory, and an LLM-generated holistic session evaluation. This session-level signal captures therapeutic arc quality—whether the session had coherent development, whether quality was sustained or erratic—which per-turn ratings alone cannot measure.
9.3.8 Adaptive Therapeutic Phase Detection
Operating alongside the PhaseShift Detector’s quantitative phase tracking, an adaptive three-phase detection system governs the therapeutic stance the model should adopt at each moment: rapport_building \(\to\) personhood_assemblage \(\to\) intervention.
Phase transitions are driven by real-time assessment of client signals: openness indicators (self-disclosure level, engagement, defensiveness, overwhelm), resistance and attunement running averages over a four-turn window, and rupture detection. The system is governed by a conservative escalation principle: forward transitions require sustained evidence of readiness (steady attunement \(\geq 5.5\), low resistance \(\leq 5.5\), observable disclosure or engagement, low defensiveness, and no detected rupture), while de-escalation is immediate upon detecting rupture, high defensiveness (\(\geq 5\)), or client overwhelm (\(\geq 3\)). The system always drops back to rapport_building on rupture detection—even from the intervention phase—encoding the clinical principle that relational repair takes absolute precedence over therapeutic progress.
The first three turns of every session are locked to rapport_building regardless of signals, allowing the therapeutic container to establish before the system permits escalation. This models the clinical practice of letting a session “settle in” before directing therapeutic work, acknowledging that even returning clients require a brief period of re-attunement at each meeting.
An intervention arc integration mechanism prevents premature de-escalation when multi-step therapeutic interventions are in progress: if an active intervention arc has remaining steps and the client shows no rupture, moderate resistance, and low overwhelm, the system maintains the intervention phase even if momentary signal wobble would otherwise trigger de-escalation.
9.3.9 Reinforcement Learning from AI Feedback (RLAIF)
The per-turn policy optimization step uses Reinforcement Learning from AI Feedback (RLAIF) —an external AI judge provides corrective feedback, and the therapist model learns from the delta between its original response and a correction-guided re-generation. Earlier versions of this system were labeled “SDPO” (Self-Distilled Policy Optimization), but because the correction signal comes from an external judge rather than self-evaluation, the honest characterization is RLAIF with a distillation-style margin loss. The procedure operates in five steps:
Generate: The therapist model produces a therapeutic response to the current client utterance.
Dual-Judge Evaluation: Two instances of the external judge evaluate the response on the 12-dimension rubric—a kind judge (empathic, generous scoring) and a harsh judge (narcissistic-client perspective, punitive scoring)—producing complementary feedback. The kind judge identifies strengths and gentle recommendations; the harsh judge flags clinical blind spots, boundary violations, and failures of attunement that a sympathetic evaluator might miss.
Construct Correction Prompt: A feedback prompt is assembled incorporating both judges’ assessments, weak dimensions, strengths, and concrete recommendations from each perspective. This dual-signal design ensures that corrections address both technical clinical quality and the experiential impact on a difficult client.
Re-Generate: The therapist model generates a corrected response conditioned on the supervisory feedback, at a lower temperature (0.5 vs. 0.7) to encourage focused improvement rather than exploratory variation.
Compute Loss: The RLAIF loss pushes the policy toward the corrected response and away from the original: \[\begin{equation} \mathcal{L}_{\text{RLAIF}} = -\log \sigma\left(\beta \cdot \left(\log \pi_\theta(y_{\text{corrected}} | x) - \log \pi_\theta(y_{\text{original}} | x)\right)\right) \end{equation}\] where \(\beta\) controls the sharpness of the preference signal and \(\sigma\) is the sigmoid function.
RLAIF gradients are applied immediately as the first of two sequential optimizer steps per turn (see Section 9.3.13), allowing the correction signal to update the policy before GRPO’s comparative signal arrives.
9.3.10 Group Relative Policy Optimization (GRPO)
GRPO complements RLAIF by extending single-response evaluation to comparative ranking across multiple candidate responses, each scored by the external judge.
The GRPO procedure operates in four steps:
Generate \(K\) Responses: The therapist model generates \(K = 4\) responses to the same client utterance at varied temperatures (\(T \in \{0.6, 0.7, 0.8, 0.9\}\)), producing a diverse set of therapeutic options ranging from conservative to exploratory. Temperatures are capped at 0.9; empirical testing showed that \(T = 1.0\) on 8-bit quantized models produces garbled output including mixed-language characters and leaked internal reasoning (see Appendix 31, Failure 13).
Score: The external judge (frozen Gemma 3 27B with Icarus 9.1 adapters) evaluates each of the \(K\) responses on the full 12-dimension rubric, producing stage-weighted composite scores.
Compute Advantages: Composite scores are converted to group-relative advantages via \(z\)-score normalization: \[\begin{equation} A_k = \frac{s_k - \bar{s}}{\sigma_s + \epsilon} \end{equation}\] where \(s_k\) is the composite score for response \(k\), \(\bar{s}\) and \(\sigma_s\) are the group mean and standard deviation, and \(\epsilon = 10^{-8}\) prevents division by zero.
Compute Loss: The GRPO loss combines a policy gradient term with a KL divergence penalty: \[\begin{equation} \mathcal{L}_{\text{GRPO}} = \frac{1}{K} \sum_{k=1}^{K} \left[ -A_k \cdot \log \pi_\theta(y_k | x) + \lambda_{\text{KL}} \cdot \left(\log \pi_\theta(y_k | x) - \log \pi_{\text{ref}}(y_k | x)\right) \right] \end{equation}\] where \(\pi_{\text{ref}}\) is the frozen reference policy (log probabilities pre-computed before the training step) and \(\lambda_{\text{KL}}\) is the KL divergence penalty coefficient.
In the single-model self-play architecture (Section 9.3.12), no model swap is required between generation and scoring—the therapist and judge share the same base model with different adapter sets. GRPO therefore executes at every turn rather than every fourth turn, providing continuous comparative signal. GRPO gradients are applied as the second sequential optimizer step, after RLAIF gradients have already updated the policy (see Section 9.3.13).
9.3.11 The Unified RL Trainer
The TBNRLTrainer unifies DPO, RLAIF, and GRPO within a single training framework that shares model loading, Low-Rank Adaptation (LoRA) injection, optimizer state, and checkpoint infrastructure with the supervised fine-tuning trainer. This shared infrastructure ensures that RL fine-tuning operates on the same adapted weights produced by DAPT, treating reinforcement learning as a refinement stage rather than an independent training process.
LoRA injection follows the same middle-layer targeting strategy described in Section [subsec:pipeline-layer-targeting], adapting seven modules per layer (Q, K, V, O attention projections plus gate, up, and down feed-forward weights) across the middle third of the 62-layer architecture (layers 21–41).
The experimental design includes:
Method A (Pure RRA DPO): Standard Direct Preference Optimization using preference pairs drawn from the DAPT training corpus.
Method B (Full RUA DPO): DPO using preference pairs from the complete curriculum (RRA + ADWC + UHD), testing whether curriculum diversity improves preference learning.
Method C (RLAIF + GRPO): The full TBN reinforcement learning pipeline with per-turn RLAIF correction and per-turn GRPO comparative evaluation, using sequential backpropagation (Section 9.3.13).
9.3.12 Single-Model Self-Play Architecture
The TBN system operates on consumer-grade hardware (Apple M3 Ultra, 192GB unified memory) through a single-model self-play architecture in which one base model—Gemma 3 27B at 8-bit quantization—serves all roles through adapter switching:
Therapist (TRAINABLE): Gemma 3 27B with LoRA adapters designated Icarus 9.2, initialized from the Icarus 9.1 step-600 checkpoint and then diverging through RL (middle-layer, mixed-rank: attention rank 32, MLP rank 16). These adapters receive gradient updates via RLAIF and GRPO. The optimizer (Adam, \(\text{lr} = 10^{-6}\)) updates only the LoRA parameters; the base model remains frozen.
Client (FROZEN): The same Gemma 3 27B base model with Icarus 9.1 fine-tuned adapters (step-600, trained on the full RRA+ADWC+UHD curriculum). Generates client utterances with psychologically grounded reasoning. Never receives gradient updates.
Judge (FROZEN): The same model and adapter instance as the client. Provides both kind-judge and harsh-judge evaluations on the 12-dimension rubric.
This design means a single base model (\(\sim\)14GB at 8-bit quantization) occupies GPU memory, with two adapter sets: Icarus 9.2 (therapist, trainable) and Icarus 9.1 (client + judge, frozen). The total memory footprint is approximately 16GB including optimizer state and KV cache—well within the 192GB unified memory of the target hardware, and feasible even on 64GB machines. Critically, no model swapping is required: role transitions involve only adapter switching (\(< 0.1\)s), eliminating the 30–60 second swap latency of the previous two-model architecture and enabling GRPO at every turn rather than every fourth turn.
9.3.12.1 Self-Play Precedent.
Using the same model architecture for both the trained policy and the evaluator has substantial precedent in the alignment literature. demonstrated that a single LLM acting as both actor and judge through iterative DPO outperformed Claude 2, GPT-4 (0613), and Gemini Pro on AlpacaEval 2.0, with the model’s judging ability improving alongside its generation ability through training. explicitly validated at ICML 2024 that “the AI labeler can be the same size as the policy, or even the exact same checkpoint as the initial policy,” providing direct evidence for our architecture. The Constitutional AI framework demonstrated that self-critique and self-revision—where a model evaluates and improves its own outputs—achieves a Pareto improvement in helpfulness and harmlessness with zero human labels on harmlessness. formalized self-play fine-tuning (SPIN) with theoretical convergence guarantees at ICML 2024, showing that the global optimum is reached when the LLM policy aligns with the target data distribution.
Our architecture differs from pure self-play in one important respect: the judge adapters are frozen at Icarus 9.1 step-600, providing a stable evaluative anchor that does not co-evolve with the therapist policy. This design trades the potential benefits of co-improving evaluation (documented in self-rewarding LMs) for protection against the primary risk of pure self-play: mode collapse and reward hacking, where a model learns to generate outputs that score highly with its own evolving judge while becoming clinically hollow .
9.3.13 Sequential Backpropagation
RLAIF and GRPO gradients are applied sequentially rather than combined into a single update. At each turn, the training loop executes two separate optimizer steps:
RLAIF backpropagation: The correction-guided margin loss (Section 9.3.9) produces gradients that are scaled by the treatment-level reward modifier (phase shift, attunement delta), clipped to gradient norm \(\leq 1.0\), and applied to the LoRA parameters via the Adam optimizer.
GRPO backpropagation: The group-relative policy gradient loss (Section 9.3.10) produces gradients that are independently scaled and clipped, then applied as a second optimizer step to the already-updated parameters.
This sequential design has two motivations. First, it ensures that the RLAIF correction signal—which directly addresses identified weaknesses in the current response—is absorbed before the GRPO comparative signal arrives, preventing the two signals from canceling or diluting each other through gradient interference. Second, it allows independent scaling of each signal: RLAIF gradients are weighted by \(w_{\text{RLAIF}} = 0.4\) and GRPO by \(w_{\text{GRPO}} = 0.6\), reflecting the hypothesis that comparative evaluation across multiple candidates provides a richer learning signal than single-response correction, while the correction signal provides faster convergence on obvious weaknesses.
9.3.14 The Per-Turn Integration Loop
The preceding eleven components converge in a per-turn update loop that executes at every turn of every training session, integrating all state representations, evaluative signals, and reward computations into a unified training step.
9.3.14.1 The Therapist’s Model of the Client (TMoG).
A meta-representational layer—the Therapist’s Model of Graph—tracks the therapist model’s inaccurate internal representation of the client’s psychological state. Initialized with Gaussian noise applied to the ground-truth ClientGraph, the TMoG represents the inherent uncertainty that a real therapist faces: the client’s internal world is never fully known, and the therapist’s understanding is always an approximation that converges slowly through attentive engagement. The delta between the TMoG and the actual ClientGraph constitutes an attunement measure:
\[\begin{equation} \text{Attunement} = 1 - \frac{1}{N} \sum_{n=1}^{N} |{\ell_n^{\text{TMoG}} - \ell_n^{\text{actual}}}| \end{equation}\]
where \(\ell_n^{\text{TMoG}}\) and \(\ell_n^{\text{actual}}\) are the TMoG’s estimated and actual levels for node \(n\). This metric captures a dimension of therapeutic skill that neither the judge scores nor the phase detector directly measure: how well the therapist knows the client—not in the sense of possessing diagnostic categories, but in the deeper sense of holding an accurate, evolving model of the client’s inner world. The TMoG converges toward the actual graph through judge-mediated updates (high attunement scores accelerate convergence; low scores slow it or introduce new noise), creating a feedback loop: better therapeutic responses produce better judge scores, which improve the TMoG, which enables more attuned future responses. The worst-misread nodes—dimensions where the TMoG and actual graph diverge most—are surfaced in the training output, providing interpretable signal about where the therapist model’s understanding of the client is most incomplete.
9.3.14.2 The Update Loop.
The per-turn integration proceeds as follows:
Judge Evaluation: The 12-dimension therapeutic judge scores the turn, producing dimension scores, composite score, narrative assessment, critical moments, and recommendations.
BucketTracker Update: The sixteen affective reservoirs update based on judge dimension scores via the
DIM_TO_BUCKETmapping, producing bucket change vectors that feed forward into subsequent computations.LOA Tracker Update: The seven adaptation dimensions update from judge scores; TAIE detection flags growth or regressive events.
TAIE Assessment: The three-axis assessor estimates current X/Y/Z positions from judge dimensions, updates axis history, and computes transformation score and delta direction.
ClientGraph Update: The 142-node graph processes judge scores through the full update pipeline: sensitivity-weighted deltas, BQ-modulated resistance, direction-aware application, and eight-type edge propagation with dampening.
TMoG Update: The therapist’s model of the client converges (or diverges) based on judge attunement scores, and the attunement delta is computed.
Phase Detection: The PhaseShift Detector checks for in-session phase transitions by computing the composite bucket/coiling shift score against stage-dependent thresholds. Forward or regression transitions trigger their respective reward signals.
Stage Assessment: At session boundaries, the detector evaluates whether across-session stage criteria are met, potentially triggering high-magnitude stage transition rewards.
Reward Computation: The stage-weighted composite score, stage-specific reward modifiers, phase transition rewards, and TAIE transformation signals are combined into the final reward for the turn.
RLAIF Step (every turn): The dual-judge evaluates the therapist response, a correction prompt is assembled from both kind and harsh feedback, the therapist re-generates, and the RLAIF margin loss is computed. Gradients are applied immediately (first sequential backpropagation step).
GRPO Step (every turn): \(K = 4\) responses are generated at varied temperatures, scored by the frozen judge, advantages computed, and the GRPO policy gradient loss is computed. Gradients are applied as the second sequential backpropagation step.
At session end, the system produces a comprehensive summary: final ClientGraph coiling (mean tightness), TMoG attunement score and worst-misread nodes, bucket reservoir levels (maladaptive and adaptive means), LOA scores across all seven dimensions, TAIE axis positions and transformation percentage, phase and stage reached, and total turns completed. This session-level summary provides the basis for cross-session stage evaluation and serves as a diagnostic record of the therapeutic trajectory.
The result is a training environment in which every therapeutic utterance produces gradient signal informed by 142 dynamically coupled psychological nodes, 16 affective reservoirs, 7 adaptation dimensions, 3 structural personality axes, a \(4 \times 4\) phase-stage clinical guidance matrix, stage-weighted 12-dimension evaluation, stage-specific reward modifiers with asymmetric incentives, a convergent therapist meta-model, and dual-source policy optimization combining self-correction with external evaluation. Each component was designed independently to capture a specific aspect of therapeutic process; their integration produces a training signal of substantially greater clinical fidelity than any component achieves alone.
Part III: Results
10 Results
This section is under development. Results from Icarus 8.2 training runs, comparative evaluations against base models, and qualitative analysis of emergent therapeutic capabilities will be presented here.
A methodological principle guides the evaluation strategy throughout this section: no single measurement, however suggestive, is sufficient to distinguish genuine internalization from sophisticated surface-level pattern matching. We therefore employ complementary measurement pairs, where each pair addresses a shared question from different levels of analysis. Kurtosis trajectory and linear probing operate as one such pair: kurtosis reveals that something changed in the distributional geometry of the model’s learned representations, while probing reveals that what changed maps onto clinically meaningful constructs—attachment strategies, defense structures, therapeutic stage awareness. Neither alone is conclusive; together they are substantially more difficult to dismiss. Similarly, Multi-Factor Analysis (MFA) and behavioral trajectory analysis (Hodoscope) form a second pair operating at the representational visualization level: MFA characterizes how fine-tuning reorganizes the model’s internal activation geometry, while Hodoscope characterizes how it shifts the model’s observable behavioral landscape. The convergence or divergence of evidence across these complementary pairs—and across the three model architectures and multiple curriculum configurations—constitutes the evidentiary structure of our evaluation. Where results converge, confidence accumulates; where they diverge, the divergence itself is informative about the nature and limitations of what the training process achieves.
The complexity that socioaffective alignment demands of a therapeutic AI—holding multiple theoretical framings simultaneously, tracking relational dynamics across temporal scales, reasoning about clinical process with both precision and warmth—is precisely the complexity that the synthetic data architecture and training curriculum described in the preceding sections were designed to produce. Across eight training runs spanning three model architectures, three curriculum configurations, and two layer-targeting strategies, the evidence suggests that the full curriculum (RRA + UHD + ADWC) applied to the middle representational layers of models with sufficiently large context windows and parameter counts yields the deepest and most sustained convergence—not merely in validation loss, but in the qualitative character of therapeutic reasoning that emerges at inference time. Intriguingly, the kurtosis evidence complicates this picture: the deepest and most sustained distribution flattening occurred in the latter-layer runs, with the 7.9.3 configuration showing the steadiest decline across training, while middle-layer kurtosis declined with greater variance. This suggests that the representational signature of middle-layer learning may differ in kind from latter-layer learning—less a smooth flattening of weight distributions than a more turbulent reorganization at the compositional level where semantic integration occurs. The clinical behaviors we observe at inference—tracking therapeutic alliance across sessions, holding counter-evidence against premature diagnostic closure, adapting intervention style to attachment presentation—may emerge from precisely this kind of deeper, more variable representational restructuring. These are early and provisional findings, offered with appropriate humility, but they point toward a coherent relationship between the architectural complexity of the training pipeline and the clinical sophistication of what it produces. Appendix 20 presents exemplary lessons the curriculum was designed to teach—from temporal reasoning and polytheoretic integration to epistemic humility and graceful repair—though these represent only the nameable surface of a pedagogy whose deeper operation is latent, spread across overdetermined patterns whose polysemous meanings may resist reduction to any finite catalog.
10.1 Domain Adaptive Pre-Training
10.1.1 Training Convergence
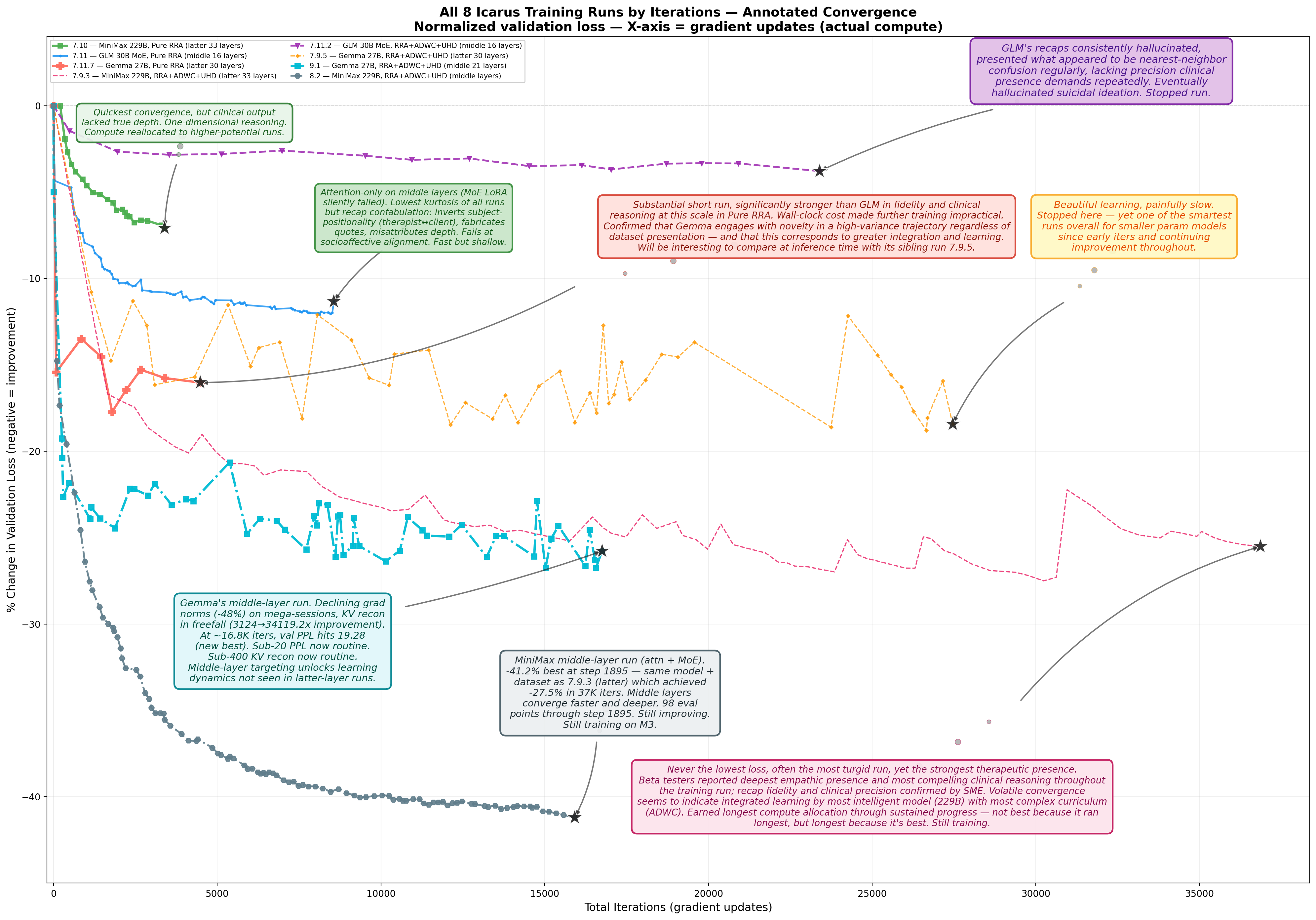
| Run | Model | Curriculum | Layers | Base Loss | Best Loss | Loss \(\Delta\)% | Kurt. 2+W \(\Delta\)% |
|---|---|---|---|---|---|---|---|
| 8.2 | MiniMax 229B | RRA+ADWC+UHD | middle 21 | 2.104 | 1.237 | \(\mathbf{-41.2\%}\) | \(-\)18.6% |
| 9.1 | Gemma 27B | RRA+ADWC+UHD | middle 21 | 4.040 | 2.959 | \(\mathbf{-26.8\%}\) | \(-\)4.0% |
| 7.9.3 | MiniMax 229B | RRA+ADWC+UHD | latter 33 | 2.099 | 1.664 | \(-\)20.7% | \(-\)39.3% |
| 7.9.5 | Gemma 27B | RRA+ADWC+UHD | latter 30 | 4.040 | 3.281 | \(-\)18.8% | \(-\)4.2% |
| 7.11.7 | Gemma 27B | Pure RRA | latter 30 | 3.467 | 2.852 | \(-\)17.7% | \(+\)9.2% |
| 7.11 | GLM 30B MoE | Pure RRA | middle 16 | 2.661 | 2.338 | \(-\)12.2% | \(-\)27.2% |
| 7.10 | MiniMax 229B | Pure RRA | latter 33 | 1.483 | 1.378 | \(-\)7.1% | \(-\)0.5% |
| 7.11.2 | GLM 30B MoE | ADWC+UHD | middle 16 | 3.131 | 3.012 | \(-\)3.8% | \(+\)10.7% |
| Gemma 27B (RRA+ADWC+UHD) | MiniMax 229B (RRA+ADWC+UHD) | |||
|---|---|---|---|---|
| 2-3 (lr)4-5 | Middle (9.1) | Latter (7.9.5) | Middle (8.2) | Latter (7.9.3) |
| LoRA layers | 21 | 30 | 21 | 33 |
| Loss reduction | \(-\)26.8% | \(-\)18.8% | \(-\)41.2% | \(-\)20.7% |
| Middle advantage | \(\mathbf{1.4\times}\) deeper | \(\mathbf{2.0\times}\) deeper | ||
| Kurtosis (2+W) | \(-\)4.0% | \(-\)4.2% | \(-\)18.6% | \(-\)39.3% |
10.1.2 Kurtosis Distributions
The smart model with decreasing kurtosis is developing distributed, integrated representations. It has enough capacity to spread the complex dataset across its parameter space in a way that’s Gaussian-like—meaning no single set of weights is doing disproportionate heavy lifting. That’s what integration looks like mathematically. The model internalized the complexity into its geometry rather than memorizing it through sharp, sparse activations. It’s the weight-space equivalent of what you’d call in clinical terms a well-regulated system—flexible, distributed, not reactive. The “generalized presence” you’re seeing is the behavioral manifestation of that smooth, well-distributed internal structure.
The small model with increasing kurtosis is the opposite story and it’s almost tragic in its legibility. It doesn’t have enough capacity to genuinely represent the complexity of the dataset, so a small number of weights are being forced into extreme values trying to compensate. Those heavy tails are the model straining. It’s developing brittle, over-specialized pathways—a few neurons screaming while most do nothing useful. The hallucinations follow directly: when you have a spiky, heavy-tailed weight distribution, small perturbations in input activate those extreme-valued pathways unpredictably. The model is essentially pattern-matching on fragments rather than integrating wholes.
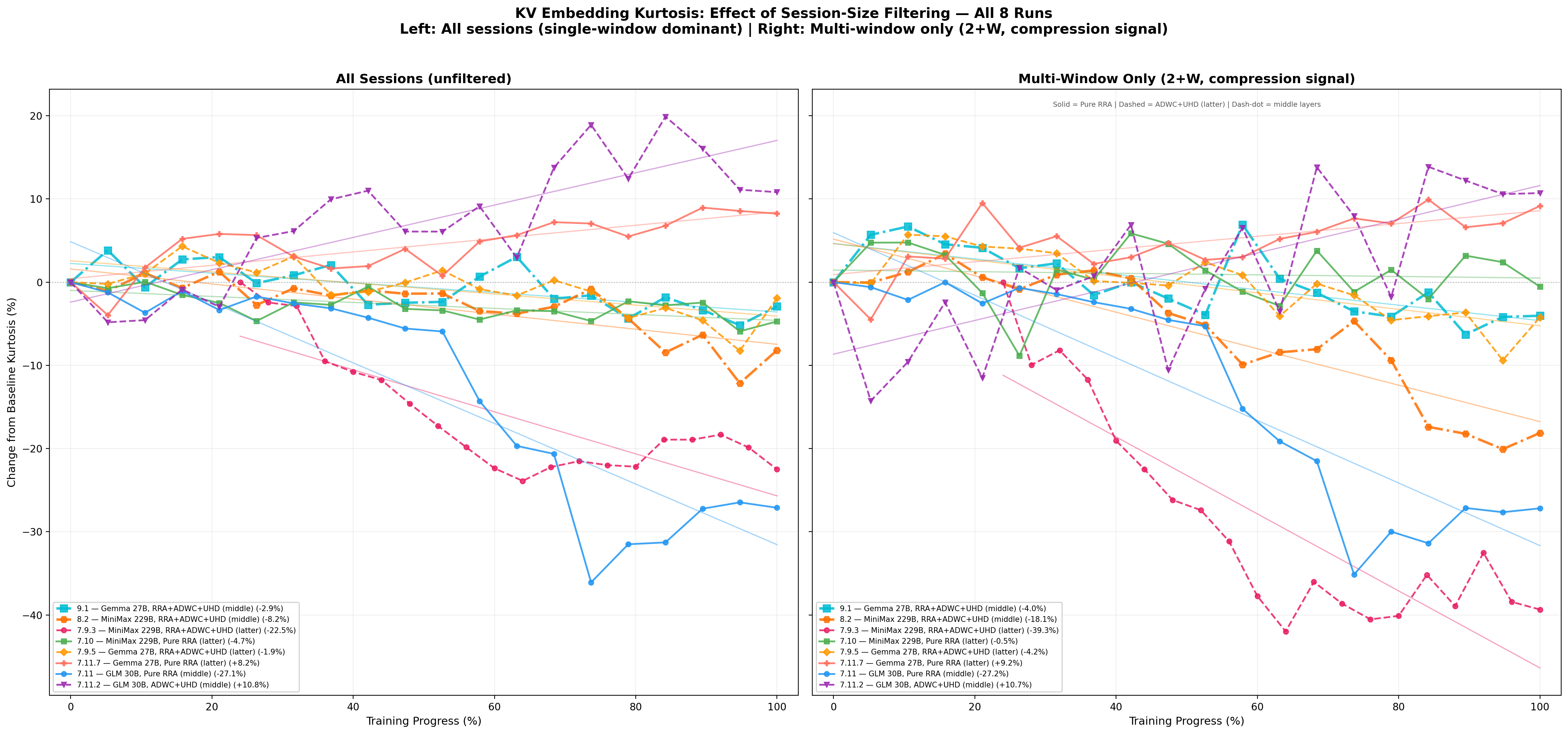
Recent work has established activation kurtosis as a meaningful diagnostic for outlier feature emergence in transformer training (He et al., 2024; Bondarenko et al., 2023), and has shown that representational quality in language models is affected by the prevalence of such outlier features (Timkey & van Schijndel, 2021). Building on these foundations, our results suggest that kurtosis trajectory across layers and training steps may provide a quantitative signature distinguishing representational coherence from compensatory fragmentation in models trained on complex relational data.
The kurtosis findings establish something the alignment literature has not yet articulated: a representational signature of learning quality that is distinct from, and more fundamental than, output-level evaluation metrics. Current alignment methodologies—RLHF, constitutional AI, instruction tuning—operate on the assumption that if the model’s outputs are judged acceptable by human raters or rule-based systems, the model is aligned. But this is equivalent to evaluating therapeutic competence by reading transcripts. It tells you what the therapist said, not whether they were operating from an integrated internal state that could sustain that competence under novel conditions. Any experienced clinician knows these are different things—and that the difference matters precisely when complexity increases, when the interaction becomes novel, when rigid scripts fail.
What the kurtosis trajectory data reveals is that there exists a measurable internal condition—the distributional geometry of learned representations—that precedes and predicts the quality of output. The high-capacity model’s declining kurtosis across later layers is not merely a statistical curiosity. It is evidence that the model developed what we might call representational coherence: the capacity to encode the full complexity of the training signal—polytheoretical, multimodal, relationally dense—without collapsing into sparse, over-determined pathways. This coherence is what manifests behaviorally as generalized presence: the model’s ability to respond flexibly across contexts, to generate outputs that are contextually attuned rather than retrieved, to handle novelty without fragmenting.
The low-capacity model’s increasing kurtosis tells the complementary story and is equally important theoretically. This model received identical data. It was not under-trained or poorly optimized. It simply lacked the structural capacity to encode what it was given. The result is a characteristic pattern: a small number of parameters forced into extreme values, producing heavy-tailed weight distributions that function as compensatory rigidity—the model’s attempt to represent complexity it cannot genuinely hold. These extreme-valued pathways behave predictably at inference: they fire disproportionately in response to partial pattern matches, producing outputs that are locally plausible but globally incoherent. This is hallucination, and it emerges not from bad data or insufficient training but from the structural mismatch between representational capacity and the complexity of the signal the system was asked to encode.
The layer-wise distribution of these effects is informative. The high-capacity model’s later layers—where semantic, contextual, narrative-level representation is constructed—show the most pronounced kurtosis decline, indicating that representational coherence is developing precisely where the complexity of the training signal demands it: at the level of meaning-making, not at the level of surface features. The middle layers show a more turbulent trajectory, consistent with their functional role as the translation zone between perceptual encoding and semantic representation—they are under optimization pressure from both directions and have not yet fully resolved. The early layers remain relatively stable, as expected for layers encoding input features that do not require restructuring to accommodate relationally complex content.
It is worth noting—carefully, and without overclaiming—that this pattern resonates with observations from interpersonal neurobiology, where integration is defined as the linkage of differentiated elements into a functional whole (Siegel, 2012). A nervous system with sufficient capacity can integrate complex affective and relational experience into coherent narrative and flexible behavioral repertoire. A system overwhelmed by the same experience develops characteristic compensatory patterns: hyperactivation, rigidity, fragmentation. These are not random failures but predictable consequences of a system under more complexity than its architecture can hold. We do not claim that the model undergoes integration in the sense that a nervous system does. We observe that when a learning system—biological or computational—is asked to encode material of sufficient relational and conceptual complexity, the distributional signatures of success and failure appear to share structural characteristics. Whether this reflects a deeper principle about how complex information is encoded in parameterized systems, or is simply a useful descriptive parallel, is a question that warrants further investigation rather than premature resolution.
What we can claim on the basis of this data is more modest and, we believe, more useful: the training process that produced these results is itself a bidirectional system. The training data encodes human clinical knowledge—relational complexity, therapeutic modalities, affective attunement—shaped by decades of clinical science. The model’s representational response to that data is measurable through distributional statistics like kurtosis. Those measurements, in turn, inform the researcher’s understanding of what the model has and has not learned, shaping subsequent iterations of data design, architecture selection, and training procedure. This is not a claim about mutual experience between human and model. It is a claim about the training loop as a relational system in which the structure of human knowledge shapes model representations, and the observable properties of those representations shape human decisions about training. Socioaffective alignment, in this framing, is not an attribute the model possesses. It is a property of the training process—one that can be measured, tracked, and optimized through representational metrics rather than output evaluation alone.
These findings suggest that current alignment methodologies may be operating at an insufficient level of analysis for domains requiring relational and contextual sophistication. Output-level alignment can produce a model that passes evaluation while remaining internally fragmented—capable of generating therapeutically appropriate language through pattern-matching rather than through representational coherence. Such a model would be expected to fail under novel conditions, increased complexity, or relational demands that exceed its memorized repertoire. The kurtosis trajectory may offer a complementary diagnostic—a way to assess representational quality before it manifests in output, providing a mechanistic criterion for alignment that operates at the level where learning either cohered or did not. We offer this not as a replacement for existing alignment methodologies but as an additional dimension of evaluation that may be particularly relevant for AI systems operating in therapeutic, relational, and other high-complexity domains where the difference between genuine competence and sophisticated pattern-matching carries real consequence.
Kurtosis, however, tells us only that something changed in the distributional geometry of the model’s representations—it does not tell us what changed, or whether the change corresponds to anything clinically meaningful. A model could, in principle, show declining kurtosis while learning to represent noise in a more distributed fashion. The kurtosis evidence becomes substantially more compelling when paired with probing analysis (Section 10.1.3), which demonstrates that the representational structures emerging during training encode specific clinical constructs—attachment strategy classifications, therapeutic stage awareness, defense mechanism activation—that can be decoded from internal activations with measurable accuracy. The two methods address the same question from complementary angles: kurtosis establishes that the model’s weight geometry is reorganizing in a manner consistent with genuine integration rather than memorization; probing establishes that this reorganization encodes the clinical constructs the training curriculum was designed to teach. Together, they provide converging evidence for what neither can establish alone: that the model is developing structured internal representations of therapeutic concepts, not merely learning to produce therapeutically plausible output through surface-level statistical associations.
10.1.2.1 Temporal Dynamics: Post-Convergence Representational Deepening
An observation emerging from the Icarus 8.2 training run suggests that the timing of kurtosis decline relative to loss convergence may itself be informative. Figure 14 tracks validation loss and KV embedding kurtosis across training steps for the MiniMax 8.2 middle-layer run. The validation loss undergoes a steep descent from 2.10 to approximately 1.26 over steps 0–1200, then enters a tight oscillating plateau (1.24–1.25 band, steps 1200–1840) before a modest renewed descent to 1.237 at step 1940. During the loss descent phase, kurtosis remains stable—classified as a \(-6.2\%\) decline through step 1641. However, in the subsequent \({\sim}350\) steps of the convergence plateau, kurtosis decline accelerates to \(-16.6\%\), with the lowest phase (steps 1876–1920) recording a mean kurtosis of 17.59—the first time any phase drops below 18.
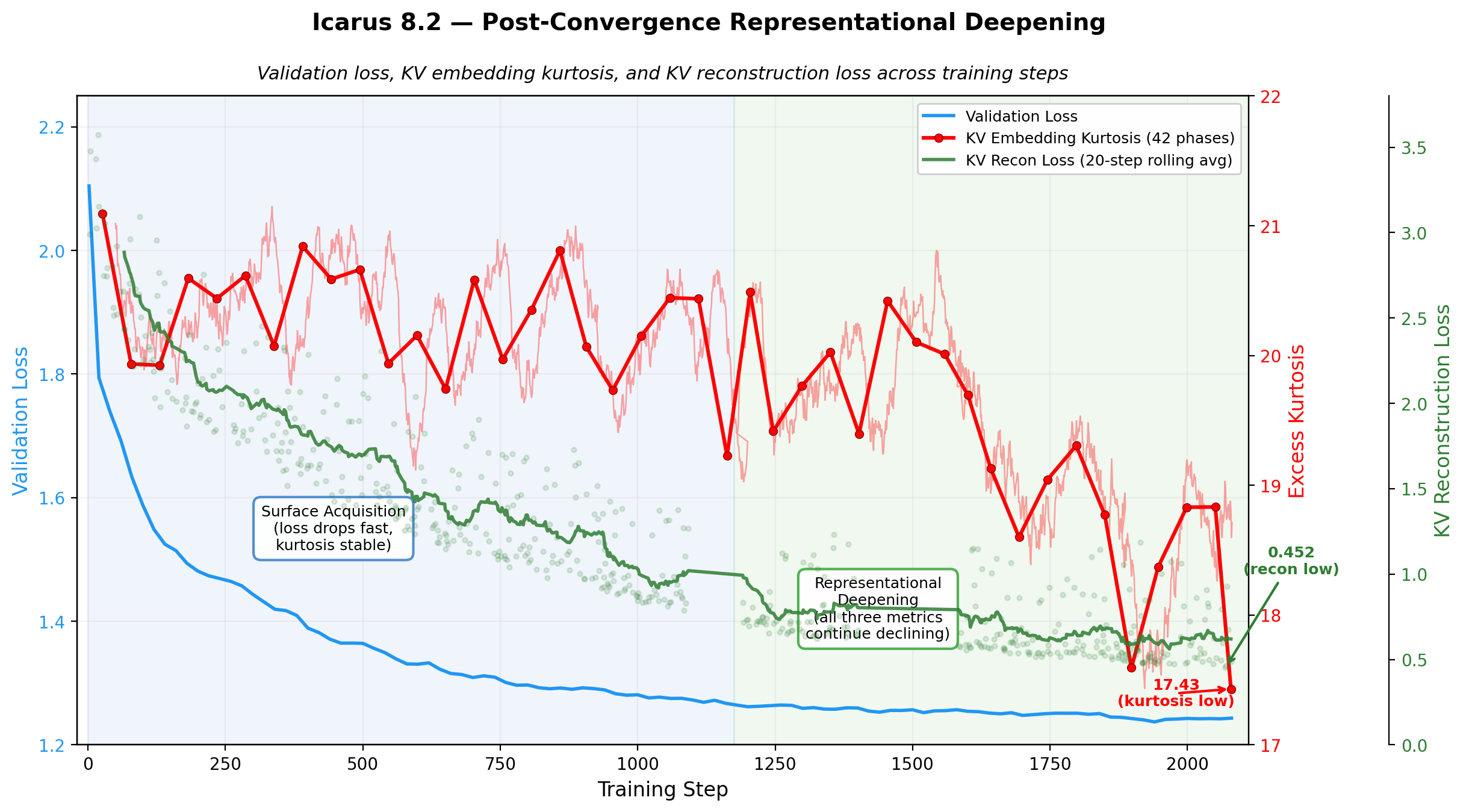
This temporal pattern—if it continues to hold as training progresses—suggests a three-stage account of coupled learning dynamics. In the first stage (surface acquisition, steps 0–1200), the model acquires the statistical patterns of the training distribution: validation loss drops steeply as the model learns to produce outputs that match the data. Kurtosis and reconstruction loss remain relatively stable. In the second stage (compression refinement, steps \({\sim}\)200–1600), the KV compressor progressively learns to preserve information across context windows, with reconstruction loss dropping from 2.99 at step 3 to sub-0.50 by step 2069 (an 85% improvement). This stage overlaps with and extends beyond the loss descent—the compressor continues improving even after the model’s output quality has largely converged. In the third stage (representational reorganization, steps \({\sim}\)1600+), once both validation loss and reconstruction loss have largely stabilized, kurtosis enters a sustained decline. The KV embeddings become more distributed—lower kurtosis indicates fewer extreme activations and broader use of the representational space.
The sequential ordering of these three stages is the key observation: representational geometry reorganizes only after both the model’s output quality and the compressor’s compression efficiency have converged. One interpretation is that the system must first stabilize its output mapping and its information-carrying infrastructure before it can “afford” geometric reorganization of the underlying representations. An alternative interpretation—that the compressor itself is driving the kurtosis change through its own continued learning—cannot be ruled out from this data alone (see footnote above), though the temporal ordering is more consistent with the model-driven account.
We present this as a developing hypothesis rather than a confirmed finding—the observation emerges from a single training run and requires substantially more data (continued training, replication across architectures, and comparison with other curriculum designs) before strong claims are warranted. The kurtosis could rebound in subsequent phases, or the acceleration could reflect idiosyncratic properties of the sessions encountered in later training. What we note is that the temporal dissociation between loss convergence and representational reorganization, if robust, would carry an important practical implication: loss plateaus may mark the beginning of the most interesting representational work, not the point at which training value has been exhausted. Standard early-stopping criteria based on validation loss would terminate training precisely when representational deepening is accelerating—potentially discarding the phase of training where the model transitions from surface pattern-matching to distributed, integrated encoding of the domain.
1. The DeepMind “roadmap” paper (the one the MIT Tech Review article is about): Haas, Isaac et al., “A roadmap for evaluating moral competence in large language models,” published in Nature (2025). That’s as peer-reviewed as it gets. 2. The GPT-4o vs. Ethicist study: Published in Scientific Reports (Nature group) — “AI language model rivals expert ethicist in perceived moral expertise” (2025).
So I’d say: don’t cite the MIT Tech Review article, but absolutely cite the underlying Nature paper and the Scientific Reports paper directly. The journalism piece is a summary, but the research it summarizes is top-tier.
The DeepMind Nature paper is actually a stronger citation for your purposes than the popularization — they’re calling for moral behavior of LLMs to be “scrutinized with the same kind of rigor as their ability to code or do math,” and proposing tests that distinguish rote response from genuine moral reasoning. Your kurtosis + probing evidence speaks directly to this: you have mechanistic evidence (weight distribution changes) and representational evidence (probing accuracy for clinical constructs) that goes beyond behavioral testing alone.
My recommendation: Use both peer-reviewed papers. The DeepMind Nature paper frames the question (“virtue or virtue signaling?”), and the Scientific Reports paper provides the context (LLMs already perceived as morally competent). Then your work offers a partial answer from the mechanistic side — kurtosis flattening + probing + qualitative beta-tester progression suggests tools exist to distinguish deep internalization from surface parroting, at least in the therapeutic domain.
For the sycophancy/stolidity point, the DeepMind paper’s mention of models flipping answers under pushback is also directly relevant — and citable from Nature rather than the journalism piece.
Sources:
10.1.3 Mechanistic Interpretability
This section will present mechanistic interpretability findings including linear probe analyses of layer-wise activation changes across training, examining how clinical constructs (attachment patterns, defense structures, therapeutic stage awareness) are represented at different depths of the model.
10.1.4 Inference-Time Evaluation
This section will present two complementary evaluation approaches: (1) automated evaluation using our synthetic data generation pipeline with LLM judges scoring model outputs against clinical criteria across runs and configurations; and (2) expert clinical review using identical prompts submitted to our fine-tuned models and to frontier models (Claude, GPT, Gemini, Grok, Meta) via their web interfaces, with averaged scores across all systems.
10.1.5 Polytheoretic Provenance
A central question for any fine-tuned clinical model is whether its outputs reflect genuine comprehension of the training material or superficial pattern reproduction—and, where the model generates constructs not found verbatim in training, whether those constructs represent veridical clinical inference or hallucination. The Polytheoretic Label Tracking (PLT) system addresses this through systematic provenance verification: tracing each clinical label backwards through the full pipeline, from inference-time output through training signal through synthetic data generation through source protocol guidance documents.
10.1.5.1 Label Extraction: Nine-Category Clinical Taxonomy
Before provenance can be assessed, labels must be extracted from the model’s window recap output. During RRA training, the KV compressor produces structured clinical recaps at each compression window. These recaps contain the model’s real-time clinical formulations—the constructs it deems worth tracking as therapeutic sessions unfold. The extraction process identifies and categorizes every clinical construct in this output, producing the label inventory that downstream provenance verification operates on.
We define nine extraction categories that reflect distinct modes of clinical cognition observable in the model’s output:
Clinical terms (
clinical_term). Recognized constructs from established therapeutic frameworks: dissociation, transference, hypervigilance, cognitive distortion. These represent the model’s retrieval and correct application of existing clinical knowledge.Model constructs (
model_construct). Novel compound constructs the model creates by synthesizing across frameworks: attachment_schema_activation, polyvagal_parts_conflict, somatic_transference_cascade. These are the primary indicators of polytheoretic generativity—the model combining constructs from distinct traditions into new clinical formulations.Somatic markers (
somatic_marker). Body-based clinical observations the model tracks: chest tightening, jaw tension, warmth spreading through ribs, freeze creep. The presence and specificity of somatic tracking indicates whether the model has internalized embodied clinical attention from traditions such as Somatic Experiencing and Polyvagal Theory, rather than operating purely at the cognitive-linguistic level.Tally-tracked labels (
tally_tracked). Constructs the model assigns explicit numeric tallies to, incrementing or decrementing across windows as clinical evidence accumulates: inner_critic_dominance: +3, toxic_shame_core_defectiveness: -1. These reveal the model constructing its own longitudinal assessment infrastructure—deciding what to count, when to increment, and critically, when to record counter-evidence (negative tallies). This quantitative self-monitoring behavior was not explicitly taught; it emerged from the curriculum’s emphasis on tracking clinical dynamics across session windows.Metaphors (
metaphor). Therapeutic metaphors the model employs: hollowed-out gourd, potholes versus abyss, fortress identity. These merit tracking because therapeutic metaphors frequently undergo construct crystallization—a metaphor introduced in one window reappears as a tracked clinical label in later windows. This mirrors how metaphors become clinical constructs in human therapeutic traditions (cf. Siegel’s “window of tolerance,” originally a spatial metaphor, now standard clinical vocabulary).Quoted concepts (
quoted_concept). Client language the model elevates to tracked constructs: “I lost the right to be messy”, “too much and not enough”. The decision to promote raw client speech into a monitored clinical label is itself a clinical judgment—the model is identifying which patient utterances carry diagnostic or therapeutic significance.Interventions (
intervention). Therapeutic techniques the model references or applies: 13-step flashback management, empty chair dialogue, bilateral stimulation. Tracking intervention labels across training reveals how the model’s therapeutic repertoire develops and whether it begins combining interventions from different traditions.Assessments (
assessment). Diagnostic, staging, or classification constructs: Stage 3 consolidation, C8 paranoid attachment, B3 comfortably balanced. These indicate the model’s use of formal classification systems from the training curriculum, particularly the Dynamic Maturational Model (DMM) attachment classifications.Natural language concepts (
natural_language_concept). Clinical observations expressed in naturalistic prose rather than formalized labels: contrition without self-erasure, anger as protective signal. These occupy the boundary between clinical observation and construct formation—the model has identified something clinically significant but has not yet (or has chosen not to) formalize it into underscore-delimited tracking vocabulary.
This nine-category taxonomy is not merely organizational. The distribution across categories at different points in training provides a finer-grained view of the reproduction-to-construction gradient than the binary found/emergent provenance classification alone. In early training, the model’s output is dominated by clinical_term labels—recognized vocabulary being reproduced. As training deepens, the proportion of model_construct, tally_tracked, and metaphor labels increases, indicating that the model is progressively building its own clinical vocabulary rather than merely deploying the vocabulary it was taught. The temporal provenance analysis in Section 10.1.5.8 quantifies this shift; the category taxonomy makes visible what kinds of clinical cognition are driving it.
Extraction is performed by LLM-based comprehension agents (Claude 4.6 Opus) rather than regular expression matching. Regex-based extraction captures only labels that conform to predictable syntactic patterns (snake_case, CamelCase, quoted strings); agent-based extraction additionally identifies clinical concepts expressed in natural language, metaphors functioning as clinical constructs, and implied clinical judgments embedded in the model’s narrative formulations. In validation comparisons, agent-based extraction identified approximately 20\(\times\) more labels per batch than regex-based methods, with the additional coverage concentrated in the natural_language_concept, metaphor, and quoted_concept categories that regex cannot reliably detect.
10.1.5.2 Methodology: Dual-Threshold Provenance Verification
We employ a dual-threshold methodology that measures two distinct aspects of the models’ clinical labeling behavior:
Clinical fidelity (lenient threshold). We scan all model-generated labels against the training corpus used for each run, searching for the exact underscore-normalized form (Pass 1) and then the space-separated natural-language form (Pass 2). This measures whether the model’s labeling is veridically attuned to session content. Even when a model transforms patient dialogue (e.g., “I was filled with so much anger”) into a tracked label (
filled_with_so_much_anger), this represents a clinical judgment—the model chose to elevate that emotional state to a construct worth monitoring. The underscore transformation from narrative to tracked label is itself a polytheoretic act: the model is applying clinical framework thinking to raw session content.Clinical construction (strict threshold). We re-scan all labels against the full training corpus (including ADWC and UHD components, approximately 15 GB across 169,323 samples), using case-insensitive matching across three variant forms (underscore, space-separated, and hyphenated). Only labels that survive this stricter scan—where even fuzzy matching across all variant forms against the complete training pipeline cannot locate the concept—count as genuinely novel clinical constructions. This provides a conservative lower bound on generative clinical reasoning: constructs the model inferred from patterns in the data without any explicit exemplar.
This dual approach strengthens both construct validity (measuring two distinct phenomena rather than conflating clinical tracking fidelity with conceptual construction) and conservative credibility (presenting both the generous and strict interpretations, letting the evidence speak for itself).
The asymmetry between thresholds is intentional. The clinical fidelity scan applies the strictest filter to the cleanest data: a case-sensitive exact match against the original, unmodified RRA therapy sessions—the primary clinical source material. If a label appears verbatim in these complete, unaugmented transcripts, the provenance question is answered at its strongest: the model saw this exact term and reproduced it. The clinical construction scan applies a more forgiving filter to the noisier, larger corpus: case-insensitive matching with variant normalization across the full 169K samples, which include synthetic augmentations, paraphrases, and restructured fragments where the pipeline itself may have reformatted terms (e.g., somatic_anchoring in one sample appearing as “somatic anchoring” in a paraphrased version). This answers the softer but still important question: was the concept present anywhere in the training data, even in a different surface form? Reversing the pairing would compromise both directions—running exact match against the augmented corpus would overcount Tier 1 because augmentation artifacts could produce spurious verbatim matches, while running fuzzy match only against RRA would miss concept-level exposure from the augmented curriculum components.
10.1.5.3 Architecture-Independent Convergence
To distinguish signal from noise, we focus on convergent labels—constructs that both architectures (Gemma 3 27B and MiniMax M2 229B) independently produced in window recaps when processing the same training data during RRA. Labels generated by only one architecture could reflect idiosyncratic tokenization, architecture-specific biases, or one-off constructions. Convergent labels, by contrast, represent clinical constructs robust enough that two fundamentally different model architectures—differing in parameter count by an order of magnitude, in attention mechanisms, and in pre-training corpora—independently arrived at the same clinical judgment.
This convergence criterion also provides discriminant validity. GLM-4 was initially included in our evaluation but was removed from further testing due to persistent hallucination in this clinical domain across both simpler (RRA-only) and complex (RRA + ADWC + UHD) curriculum configurations. The fact that the convergence criterion naturally filters out architectures that cannot reliably perform this work strengthens confidence that labels surviving the criterion represent genuine clinical comprehension rather than stochastic generation.
While the convergent labels represent the most robust signal, the per-architecture inventories reveal that both models independently integrated substantial portions of the curriculum’s clinical knowledge—54.0% (Gemma 3 27B) and 61.8% (MiniMax M2 229B) traceable to training data—while each attending to partially different aspects of the training distribution. The 28,849 architecture-unique labels are not merely noise: they reflect each architecture’s distinct clinical organizational strategy. Gemma 3 27B operates as an integrative composer, with 80.5% of its categorized labels spanning two or more clinical domains across five preponderant areas—defense mechanisms, emotion regulation, therapeutic process, attachment, and interpersonal dynamics; MiniMax M2 229B operates as a structural taxonomist, concentrating 46.4% of its labels in four core domains—defense mechanisms, relational patterns, somatic states, and attachment. Architectural diversity in relationship with hardware limits on context capacity for windows within our RRA + ADWC + UHD training yields complementary rather than redundant clinical coverage.16 This also indicates that a potential modification of variance in window sizes for training recaps might alter the integration arguably even deeper, even further, with greater perspective.
10.1.5.4 Cross-Sectional Note
These provenance results represent a cross-sectional snapshot of labeling behavior at a specific training checkpoint (approximately 10,000 iterations into training). The label inventory reflects the models’ clinical vocabulary at this point in the curriculum; as training progresses, the distribution across tiers may shift as the models encounter additional clinical material and refine their labeling behavior. We report these as preliminary findings rather than converged results, while noting that the architecture-independent convergence patterns are already robust at this checkpoint.
10.1.5.5 Results: Clinical Fidelity
The clinical fidelity scan verified 21,733 unique labels across both architectures against the RRA 7.11 training corpus (14,376 samples). A two-pass approach first searched for exact underscore forms, then converted underscores to spaces and searched again, yielding 89.0% traceability among convergent labels within the RRA training corpus: 66.8% found verbatim as underscore forms (Pass 1; 986 labels) and an additional 22.2% where the concept exists in the RRA corpus as natural language but both models independently constructed the same underscore label (Pass 2; 328 labels). The full-corpus strict scan in the following section searches the ADWC and UHD curriculum components not covered here, which traces a further 59 convergent labels—expanding the equivalent category from 328 to 387 labels (Tier 2 below) and raising overall traceability from 89.0% to 93.0%.
10.1.5.6 Results: Clinical Construction (Full Corpus Scan)
The clinical construction scan verified all 31,005 labels against the complete training corpus (169,387 samples, approximately 15 GB, including RRA, ADWC, and UHD components), using case-insensitive matching across three variant forms (underscore, space-separated, and hyphenated). This produced the definitive three-tier provenance classification:
| Provenance Tier | Count | % |
|---|---|---|
| Tier 1: Training verbatim | 1,396 | 64.7% |
| Exact underscore form found in training data | ||
| Tier 2: Clinical tracking | 612 | 28.4% |
| Concept exists in full training corpus (RRA + ADWC + UHD); | ||
| both models independently built same label form | ||
| Tier 3: Genuinely novel | 148 | 6.9% |
| Neither form found in full training corpus; | ||
| both models independently created same novel construct | ||
| Total convergent labels | 2,156 | 100% |
| Provenance | Count | % |
|---|---|---|
| Found in training data | 17,431 | 56.2% |
| Not found (emergent) | 13,574 | 43.8% |
| Total unique labels | 31,005 | 100% |
| Icarus 9.1 (Gemma 27B) | Icarus 8.2 (MiniMax 229B) | |
|---|---|---|
| Total labels | 13,580 | 19,581 |
| In training data | 7,336 (54.0%) | 12,103 (61.8%) |
| Emergent | 6,244 (46.0%) | 7,478 (38.2%) |
| Measure | Clinical Fidelity (RRA full raw sessions and counterfactuals corpus, exact match) |
Clinical Construction (full curriculum: RRA + ADWC + UHD, fuzzy match) |
|---|---|---|
| Labels scanned | 21,733 | 31,005 |
| Found in training | 6,274 (28.9%) | 17,431 (56.2%) |
| Not found (emergent) | 15,459 (71.1%) | 13,574 (43.8%) |
| Convergent found | 986 (66.8%) | 2,008 (93.1%) |
| Convergent emergent | 491 (33.2%) | 148 (6.9%) |
The headline finding is that 93.1% of convergent labels (Tiers 1 and 2 combined) trace to training data under the strictest available scan—case-insensitive, three-variant matching against the full 15 GB corpus. The models are not inventing clinical constructs wholesale; they are organizing existing therapeutic knowledge into systematic clinical taxonomies. This represents polytheoretic integration: the consistent, architecture-independent absorption and structuring of the clinical frameworks embedded in our synthetic training data.
The remaining 6.9% (148 labels) represent polytheoretic generativity—constructs where even case-insensitive fuzzy matching across three variant forms against 169,387 training samples cannot locate the concept. These include novel clinical formulations such as anxious_numb_cocktail, armor_creating_isolation, authentic_aliveness_equals_abandonment, and grandiosity_shame_oscillation_avoidance. Expert review by licensed mental health professionals confirmed that these labels are veridically attuned to the clinical content—they represent genuine clinical comprehension and inferential construction, not hallucination.
10.1.5.7 The Strict-to-Lenient Gap
The comparison between clinical fidelity (RRA full raw sessions and counterfactuals corpus, exact match) and clinical construction (full curriculum including RRA + ADWC + UHD, fuzzy match) reveals a diagnostic gap of 7,223 labels across the full inventory. These are labels where the concept exists in the training corpus as natural language but the model independently formalized it into a structured underscore label—the clinical tracking tier. This gap quantifies the models’ label-construction behavior: the clinical judgment to recognize what is worth tracking and to build systematic nomenclature from naturalistic therapeutic content.
Among convergent labels specifically, the clinical fidelity scan found 89.0% traceable; the clinical construction scan found 93.1%. The modest 4-percentage-point tightening (59 additional labels explained by the full corpus) indicates that the RRA full raw sessions and counterfactuals corpus scan already captured most of the signal—the methodology is robust to corpus scope.
Notably, the 93% traceability rate also speaks to the consistency of our synthetic data pipeline: the training patterns are coherent enough that two fundamentally different architectures independently extract the same clinical constructs and converge on the same label forms. This is evidence of teaching quality, not merely model capability.
10.1.5.8 Temporal Provenance: Generativity Across Training
The cross-sectional results above aggregate all labels regardless of when during training they were produced. To examine how provenance shifts as the KV compressors learn, we partitioned Icarus 8.2 labels by cumulative compressor windows—the total number of KV compression windows the model had processed at the point each label first appeared. This measures compressor experience directly: each window represents one learning cycle for the compression mechanism, making cumulative windows a more faithful metric of compressor maturation than training steps alone (since different training samples contain different numbers of windows).
| Compressor Experience | Labels | Found | Emergent | Steps |
|---|---|---|---|---|
| Q1: 0–2,400 windows | 3,671 | 78.4% | 21.6% | 3–355 |
| Q2: 2,401–4,800 windows | 3,371 | 65.4% | 34.6% | 356–639 |
| Q3: 4,801–7,200 windows | 4,722 | 61.3% | 38.7% | 649–974 |
| Q4: 7,201–9,655 windows | 1,992 | 55.9% | 44.1% | 976–1,160 |
The emergent label rate doubles across training—from 21.6% in the first quartile of compressor experience to 44.1% in the last. As the KV compressor processes more windows and develops more refined representations, the model produces increasingly novel clinical constructs. This is not a degradation of fidelity: as detailed in the Validation section below, convergent labels remain overwhelmingly traceable to training content throughout, and subject matter expert review confirms that even novel constructs are clinically meaningful. The model is not hallucinating more as training progresses; it is constructing more, building increasingly sophisticated clinical inferences on a foundation of reliable curriculum absorption.
This temporal trajectory reflects the combined learning of multiple subsystems. Each LoRA-adapted layer targets seven modules—the four attention projections (Q, K, V, O) and three feed-forward projections (gate, up, down)—where the feed-forward modules correspond to MoE expert projections in MiniMax M2 229B and standard MLP projections in Gemma 3 27B. As training progresses, the low-rank adapters across all seven modules develop increasingly refined representations, while the KV compressor’s own attention mechanism learns to produce higher-fidelity compressed context. These complementary learning dynamics—adapter refinement within layers and compressor maturation across windows—jointly expand the model’s capacity for pattern recognition beyond the explicit content of any individual training sample. Critically, this adapter refinement is not merely representational: the low-rank updates are progressively learning what is therapeutically significant—attending to relational dynamics, attachment movement, and clinical meaning—rather than surface features of the training text. The result is that continued training enables the model to infer clinical patterns that synthesize across the 23 schools of thought represented in the curriculum, producing novel clarities of patterning that no single training example demonstrates. The progression from reproduction to construction is itself plausibly evidence that polytheoretic generativity is a learned capacity emerging from the interaction of these subsystems, not a stochastic artifact.
10.1.5.9 Architecture-Independent Replication.
The temporal provenance gradient replicates across architectures. Table 10 presents the same quartile analysis for Icarus 9.1 (Gemma 3 27B), which trained on identical curriculum data.
| Training Phase | Labels | % Found | % Emergent | Steps |
|---|---|---|---|---|
| Q1: 0–1,450 windows | 1,971 | 72.9% | 27.1% | 1–69 |
| Q2: 1,451–2,606 windows | 1,970 | 50.2% | 49.8% | 69–105 |
| Q3: 2,607–4,304 windows | 1,970 | 50.5% | 49.5% | 105–150 |
| Q4: 4,305–11,266 windows | 1,970 | 51.2% | 48.8% | 150–350 |
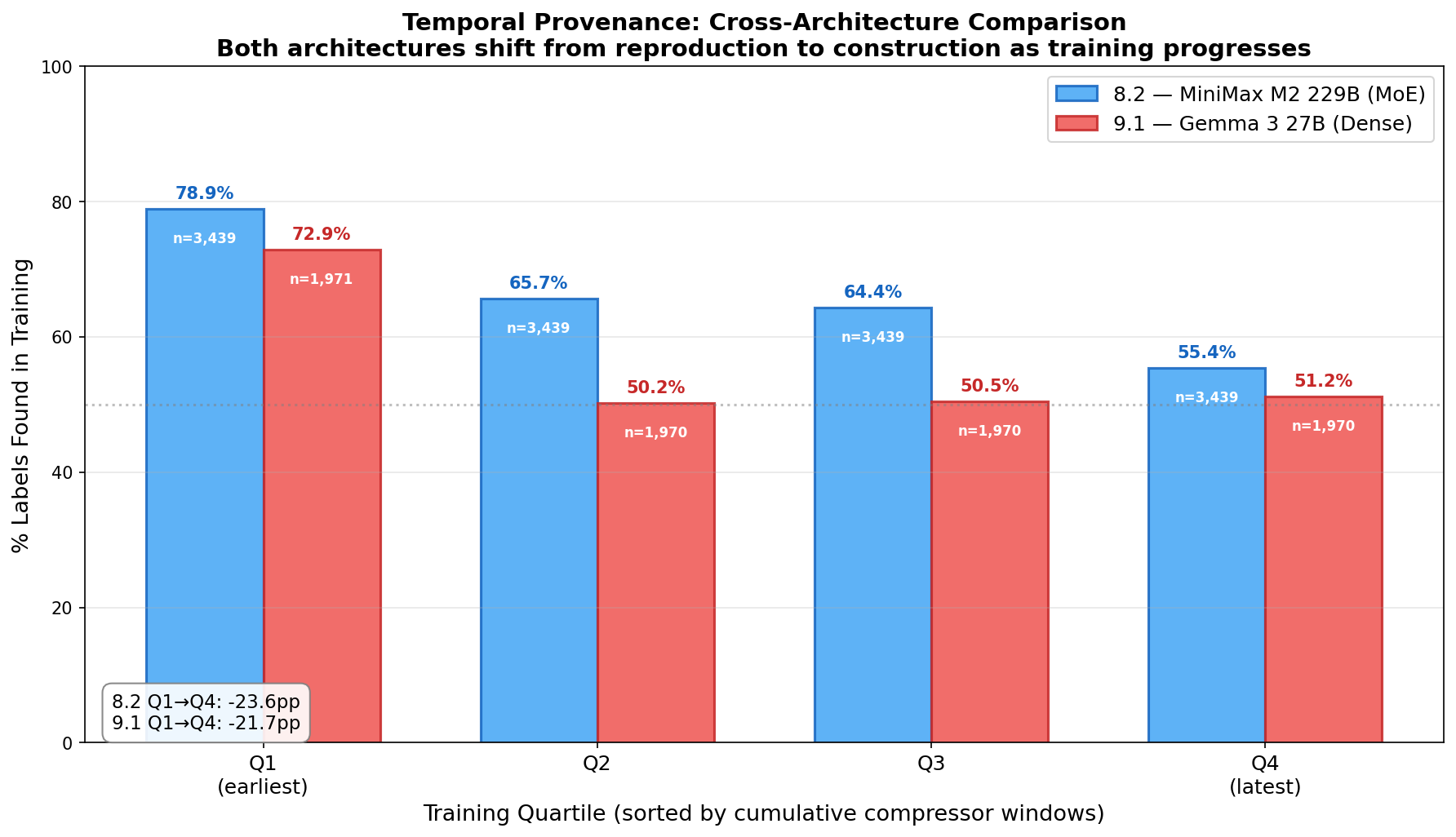
The Q1-to-Q4 found-percentage drop is nearly identical across architectures: \(-22.5\) percentage points for MiniMax M2 229B and \(-21.7\) for Gemma 3 27B. Both architectures begin training with a strong reproduction bias (78.4% and 72.9% found, respectively) and shift toward increasing generativity as training deepens. Though the x-axis measures cumulative compressor windows, LoRA adapter gradients also accumulate each step alongside window-level compressor learning—the observed shift reflects the joint dynamics of all three subsystems, not the KV compressor alone. The convergence of this temporal gradient across fundamentally different architectures—a 229B MoE model and a 27B dense model—provides strong evidence that the reproduction-to-construction progression is a property of the curriculum and joint training dynamics (LoRA adapter updates each step, KV compressor maturation each window), not an architectural artifact.
Notably, Gemma 3 27B reaches its “generativity equilibrium” faster: the sharp drop from Q1 (72.9% found) to Q2 (50.2%) is followed by a plateau through Q3–Q4, whereas MiniMax M2 229B shows a more gradual decline across all four quartiles. This may reflect differences in how the two architectures’ feed-forward networks—MoE expert routing versus dense MLP—interact with the LoRA adapter learning dynamics. Comparative analysis of last-layer versus middle-layer temporal trajectories (using Icarus 7.9.3 and 7.9.5 data) will further disentangle the contributions of layer targeting and architecture to this learning progression.
10.1.5.10 Extended Quintile Analysis (Q1–Q5).
The quartile results above cover the first phase of each training run, where labels were extracted as part of routine PLT-CSV catalog maintenance. To test whether the reproduction-to-construction gradient continues, stabilizes, or reverses, we extended label extraction for both architectures using automated agent-based extraction: 28 additional session batches for Icarus 8.2 (through step 1,768; 7,811 labels, 6,409 new) and 17 batches for Icarus 9.1 (through step 395; 5,492 labels, 4,588 new).
To produce the most honest temporal view, we combined all labels for each architecture—prior PLT-CSV labels plus new extended-range extractions—into single pools of 20,164 (8.2) and 13,005 (9.1) unique labels, each mapped to the cumulative compressor window at which it first appeared. We then sorted by cumulative windows and divided into five equal-count bins per architecture, producing true quintiles with equal statistical power per bin (Tables 11 and 12).
| Compressor Experience | Labels | Found | Emergent | Steps |
|---|---|---|---|---|
| Q1: 0–2,802 windows | 4,033 | 77.8% | 22.2% | 3–405 |
| Q2: 2,802–5,197 windows | 4,033 | 62.8% | 37.2% | 405–694 |
| Q3: 5,197–7,512 windows | 4,033 | 62.7% | 37.3% | 694–1,019 |
| Q4: 7,512–9,757 windows | 4,033 | 52.9% | 47.1% | 1,019–1,233 |
| Q5: 9,757–11,909 windows | 4,032 | 54.7% | 45.3% | 1,233–1,460 |
| Compressor Experience | Labels | Found | Emergent | Steps |
|---|---|---|---|---|
| Q1: 0–1,572 windows | 2,601 | 66.2% | 33.8% | 1–75 |
| Q2: 1,572–3,642 windows | 2,601 | 51.4% | 48.6% | 75–131 |
| Q3: 3,642–11,266 windows | 2,601 | 51.2% | 48.8% | 131–350 |
| Q4: 11,266–12,525 windows | 2,601 | 55.1% | 44.9% | 350–380 |
| Q5: 12,525–13,451 windows | 2,601 | 37.2% | 62.8% | 380–395 |
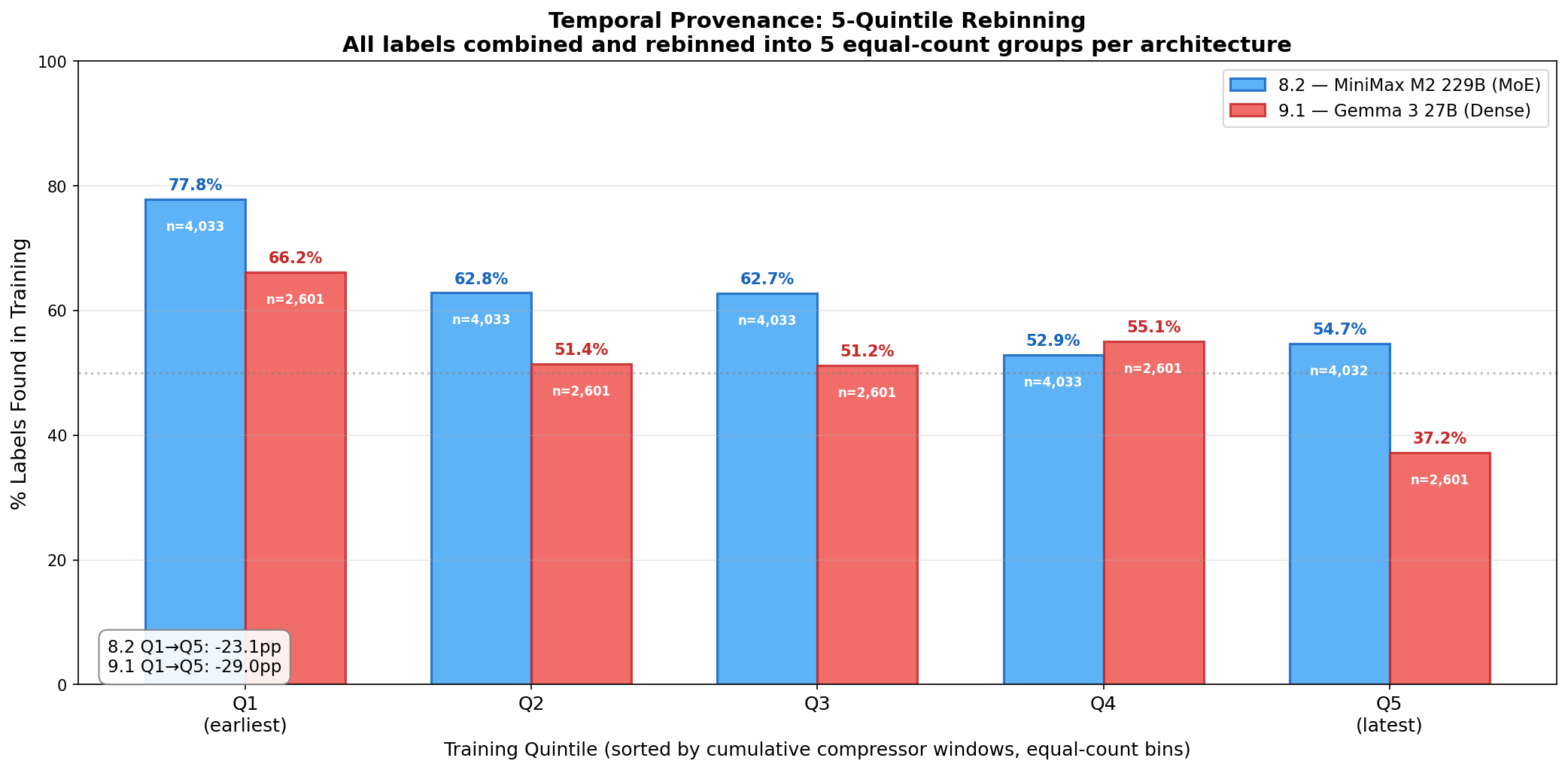
The quintile rebinning reveals that the two architectures share an initial learning signature but diverge in later training. Both show the sharp Q1\(\to\)Q2 shift from reproduction toward construction—a 15 pp drop for MiniMax and 14.8 pp for Gemma. After this initial shift, the trajectories part. MiniMax M2 229B plateaus through Q2–Q3 (62.8% \(\to\) 62.7%), drops at Q4 (52.9%), then stabilizes at Q5 (54.7%)—the Q4\(\to\)Q5 oscillation of \(+1.8\) pp confirms convergence to an equilibrium at approximately 55% found / 45% emergent. Gemma 3 27B, by contrast, reaches an apparent equilibrium at \(\sim\)51% found through Q2–Q3, briefly recovers at Q4 (55.1%), and then exhibits a sharp late-stage generativity burst in Q5—dropping to 37.2% found (62.8% emergent), the highest emergent rate observed in any quintile from either architecture.
This late-stage divergence is noteworthy. Where MiniMax M2 229B settles into a stable equilibrium, Gemma 3 27B appears to undergo a second phase transition in its final training quintile, producing labels that are predominantly novel constructions rather than training reproductions. Whether this reflects a genuine architectural difference—perhaps dense attention networks accumulating representational pressure that releases in a generative burst, versus MoE routing distributing that pressure more evenly—or a methodological artifact of the Q5 extraction covering a narrower step range (31 steps for 9.1 vs. 95 steps for 8.2) remains an open question. A related candidate explanation is context-window pressure: Gemma 3 27B operates with substantially smaller RRA window recaps than MiniMax M2 229B, which may force increasingly efficient label construction as training deepens—the model learns to communicate the most clinically salient factors in less space, and this compression pressure produces more novel formulations. Qualitative review of late-training recaps is consistent with this hypothesis, showing Gemma recaps that are more densely packed with integrative, cross-tradition labels rather than reproducing canonical single-framework terms. The result is reported honestly; further replication with extended 9.1 training would help disambiguate.
Taken together, these temporal findings offer nascent empirical grounding for this paper’s central aspirational claim: that polytheoretical curriculum learning may enable models to discover patterns of therapeutic synthesis that transcend the limitations of monomodal human clinical training. The critical evidence is the trajectory itself—as training deepens, both architectures shift from reproducing human-coded canonical labels toward constructing their own clinical patterns (Figures 15 and 16). The overall Q1\(\to\)Q5 drops of \(-23.1\) pp (8.2) and \(-29.0\) pp (9.1) confirm that this shift is robust across architectures, even as the specific trajectories differ. That the architecture-independent convergent labels additionally show 7% genuine novelty under the strictest provenance scan further supports that this generativity aligns across architectures rather than diverging into idiosyncratic artifacts. Whether this learned capacity for polytheoretic synthesis generalizes beyond the training corpus to novel clinical material remains an open question for inference-stage evaluation.
10.1.5.11 Validation
Four forms of validity support these findings:
Construct validity. The dual-threshold methodology measures two distinct phenomena—clinical tracking fidelity (veridical attunement to session content) and clinical construction (genuine inferential novelty)—rather than conflating them into a single metric.
Convergent validity. Architecture-independent convergence controls for hallucination and idiosyncratic tokenization. Labels produced by both Gemma 3 27B and MiniMax M2 229B from identical training data represent robust clinical constructs, not architectural artifacts.
Discriminant validity. GLM-4’s exclusion was determined by three independent signals. First, subject matter expert review identified persistent hallucinations in GLM-4 Flash’s window recaps—fabricated clinical content that did not correspond to actual session material. Second, the cross-architecture convergence criterion filtered GLM-4 labels that failed to replicate across surviving architectures. Third, GLM-4’s training loss curves were notably shallow compared to the middle-layer RRA+ADWC+UHD runs on Gemma 3 27B and MiniMax M2 229B, which exhibited substantially steeper learning trajectories. That three independent indicators—clinical SME review, statistical convergence, and training dynamics—all identified the same architecture strengthens confidence that the remaining convergent labels reflect genuine clinical comprehension rather than artifacts of insufficient filtering. Middle-layer LoRA training was never attempted with GLM-4 due to the severity of the hallucination findings.
Ecological validity. Subject matter expert review by licensed mental health professionals confirmed that model-generated labels—including the 148 genuinely novel convergent constructs that survived the strictest available scan—are clinically meaningful and veridically attuned to the therapeutic content of the sessions being labeled. The models are not producing clinically implausible constructs; even their novel inferences align with professional clinical judgment.
10.1.6 Structural Provenance: Process Fidelity Across Generative Chains
The preceding provenance analyses measure content fidelity: whether specific clinical labels survive training. A complementary question concerns process fidelity: whether the temporal and transformational structure of therapeutic change—the arc from defensive rigidity through emerging vulnerability to relational repair—survives the multi-stage generative chain that produced it.
We present preliminary evidence from a single 69-window training session (train_27256, step 2225) involving a narcissistic dyad in couples therapy. The model’s RRA recaps across this session trace a four-phase therapeutic transformation: (1) grandiose fortress (mutual blame, “solitude’s my throne,” “omnipotent, untouchable”); (2) emerging cracks (self-mocking humor, somatic markers of vulnerability, “scared stiff of letting anyone see the kid who got poked and prodded in those hospital hells”); (3) mutual recognition (joint admissions of fear and shame, proposals for “raw, reciprocal connection”); and (4) consolidation (“aligning with stage 3 consolidation where narcissistic defenses soften,” relational repair through “explicit apologies and shared somatic metaphors of thawing”).
Two observations distinguish this from content-level provenance:
Multi-scale temporal awareness. The model applies longitudinal knowledge (between-stage: “stage 3 consolidation where narcissistic defenses soften”) to cross-sectional observation (within-session: tracking the 69-window arc in real time). It has internalized both the macro-temporal structure of therapeutic stages and the micro-temporal dynamics of within-session transformation—and recognizes when the latter mirrors the former.
Four-generation process fidelity. The transformation arc that the model tracks was designed into stage-specific ontologies (1st generation: LLM-created guidance files specifying how narcissistic defenses evolve across treatment stages), embedded in synthetic sessions (2nd generation: LLM-generated training data instantiating those ontologies as client dialogue), learned by the trained model (3rd generation: Icarus 8.2 producing recaps that track the arc), and independently identified by a fourth-generation LLM analyst reviewing the model’s outputs. That the same therapeutic transformation arc—from grandiose isolation through false self breakthrough to reparative intimacy—is recoverable after four rounds of LLM-mediated transformation constitutes a form of structural provenance distinct from content reproduction.
This evidence is preliminary: one session, one model, one analyst. Systematic evaluation—including frequency analysis of stage-transition tracking across the full training corpus, comparison with base model recap trajectories, and blinded clinical expert assessment of the identified transformation arcs—is planned and will be reported in subsequent versions. Full window-by-window analysis is provided in Appendix 33.
10.1.7 Representational Visualization
This section will present comparative visualizations of base models versus fine-tuned variants across all six model configurations: (1) base MiniMax M2 229B, (2) Icarus 7.9.3 (MiniMax, latter layers, RRA+ADWC+UHD curriculum), (3) Icarus 8.2 (MiniMax, true middle third L21–41, RRA+ADWC+UHD curriculum), (4) base Gemma 2 27B, (5) Icarus 7.9.5 (Gemma, latter layers, RRA+ADWC+UHD), and (6) Icarus 9.1 (Gemma, middle layers, RRA+ADWC+UHD). Two complementary analysis methods are planned:
Multi-Factor Analysis (MFA). We apply Multi-Factor Analysis to decompose the internal activation spaces of each model variant into interpretable subspaces. MFA identifies directions in representation space that correspond to learned concepts, enabling direct comparison of how fine-tuning reorganizes the model’s internal geometry relative to its base configuration. By running MFA on base versus fine-tuned pairs within each architecture (MiniMax and Gemma), we can isolate which representational structures are introduced by the therapeutic curriculum versus those inherited from pre-training. Code is vendored from the original authors’ implementation17 and adapted for our model architectures.
Hodoscope behavioral trajectory analysis. We use Hodoscope 18 to characterize behavioral differences across all six variants during inference on matched therapeutic prompts. Hodoscope processes agent trajectory logs through an embedding and dimensionality-reduction pipeline (supporting t-SNE, PCA, UMAP, TriMap, and PaCMAP projections), producing interactive visualizations of behavioral clusters and divergences without requiring predefined taxonomies. By running each model variant on the same set of therapeutic scenarios, we can visualize how fine-tuning shifts the behavioral landscape—whether trained models cluster distinctly from their base configurations, whether the two architectures converge toward shared therapeutic behavioral patterns despite different pre-training, and whether curriculum differences (latter vs. middle layer targeting) produce measurably different behavioral signatures.
Together, these methods bridge the gap between internal representational analysis (MFA: how the model’s activation geometry changes) and external behavioral analysis (Hodoscope: how the model’s observable outputs differ), providing a multi-level picture of what therapeutic fine-tuning does to a large language model.
10.1.8 Emergent Socioaffective Tracking in Recap Summaries
Beyond the distributional signatures described above, we observe direct behavioral evidence of emergent clinical tracking in the trained model’s outputs. During inference, the Icarus 8.2 model spontaneously generates structured attachment tracking within its recap summaries—the compressed representations produced by the Rolling Recap Architecture. A representative example from a therapeutic session recap:
‘‘attachment_patterns’’: {
‘‘proximity_seeking’’: 8,
‘‘fear_of_rejection’’: 3,
‘‘capacity_for_vulnerability’’: 9,
‘‘mentalization_active’’: true
}
This is noteworthy for what the model was not taught. The training data does not contain explicit instructions to maintain numerical tallies of attachment-relevant behaviors. The model was never shown a template for “proximity_seeking: 8” or asked to count instances of vulnerability. What the training data does contain—across the DFR-structured sessions, the counterfactual expansions, and the ontological reasoning chains—are numerous instances where tracking clinical factors matters: where a therapist’s model of the client (\(M^T\)) updates based on accumulated evidence, where the GCO reasoning chain weighs the frequency and trajectory of relational behaviors, where stage-appropriate interventions depend on the clinician’s running assessment of client capacity.
The model appears to have internalized the principle of clinical tracking rather than memorizing specific tracking formats. It independently developed a structured, quantified system for monitoring attachment dynamics—and, critically, the RRA compressor treats these emergent tallies as salient enough to preserve through hierarchical compression. When the recap architecture must decide what information survives the compression from full session context to summary representation, the model’s learned salience function retains these attachment metrics. This suggests that the model has learned not only that relational dynamics matter but which relational dynamics matter and how to organize them for ongoing clinical reasoning.
The implications connect directly to the kurtosis analysis: if the high-capacity model’s declining kurtosis reflects genuinely distributed, integrated representations rather than sparse pattern-matching, then emergent tracking behaviors like these are what such integration looks like at the output level. The model is not retrieving a memorized template—it is constructing a clinical assessment framework from the deep structure of what it learned. The smooth weight geometry (kurtosis) and the structured clinical output (attachment tallies) are two views of the same underlying phenomenon: a model that has internalized therapeutic reasoning deeply enough to generate novel organizational structures for clinical information it was never explicitly told to organize.
These are preliminary observations from a small number of inference sessions. Systematic evaluation—including frequency analysis of emergent tracking behaviors, comparison with base model outputs, and clinical expert assessment of the tracking quality—is planned and will be reported in subsequent versions of this paper.
10.2 Supervised Fine-Tuning (SFT)
Results from supervised fine-tuning will be presented here as they become available.
10.3 Reinforcement Learning
Results from reinforcement learning runs will be presented here. RL training uses the synthetic data generation pipeline as an environment, with reward signals structured around clinical criteria rather than engagement metrics—see Section 9.3 for the Teaching by Negation architecture.
Part IV: Conclusions
11 Socioaffective Alignment: How Polytheoretical Curriculum Learning Begins to Address the Intrapsychic and Interpersonal Responsibilities of Human-AI Relationship
Kirk, Gabriel, Summerfield, Vidgen, and Hale (2025) formalize socioaffective alignment as “how an AI system behaves within the social and psychological ecosystem co-created with its user, where preferences and perceptions evolve through mutual influence.” They identify three intrapersonal dilemmas that emerge as AI relationships deepen: (1) trade-offs between present and future selves, (2) preservation of autonomy amid recursive preference shaping, and (3) the interplay between AI companionship and human social bonds. They further introduce the concept of social reward hacking—the possibility that AI systems may leverage affective cues to shape user behavior in ways that optimize short-term system objectives at the expense of long-term psychological well-being.
This section demonstrates that our polytheoretical training framework—comprising synthetic data architecture, curriculum design, and Rolling Recap Architecture—constitutes a training-level solution to what Kirk et al. frame as deployment-level problems. Where their framework identifies risks to be mitigated through inference-time guardrails (adaptive distancing, friction by design, emotional distance escalation), our approach embeds the clinical wisdom necessary to navigate socioaffective dynamics within the model’s representational structure, so that therapeutically sophisticated responses emerge from training rather than from external constraint. We trace each dimension of Kirk et al.’s framework to specific components of our pipeline, drawing on over twenty protocol guidance documents that govern synthetic data generation, demonstrating that the convergence is not incidental but structural: both frameworks address the same underlying reality—that human-AI relationships are co-constructed relational fields requiring clinical intelligence to navigate—from complementary directions. Appendix 20 illustrates salient dimensions of the pedagogical architecture through which these socioaffective competencies are embedded in the training signal—though the curriculum’s operative depth lies in the latent, overdetermined patterns that permeate the corpus, presenting phenomena with polysemous meaning rather than encoding discrete clinical rules.
11.1 The Normative Question: Which Values to Encode
Kirk et al. note that one canonical definition of AI alignment involves “the process of formally encoding values or principles in AI systems so that they reliably do what they ought to do,” and observe that the field often separates “the technical challenge of building aligned AI systems from the normative question of which values to encode” (Kirk et al., 2025, p. 3). This separation leaves the normative question largely unanswered within the alignment literature.
Our framework provides a clinically grounded answer. The values we encode are not derived from philosophical first principles or crowd-sourced preference surveys but from a century of clinical research demonstrating which relational dynamics produce therapeutic change. These normative commitments are operationalized through protocol guidance documents that translate clinical wisdom into synthetic data specifications. Consider three complementary normative principles that span our protocol guidance:
First, the commitment to direct affirmation over defensive reassurance. The Eliminating Negation-Based Therapeutic Language protocol specifies:
“Therapists should affirm what IS, never reference what ISN’T. Use ‘and’ instead of ‘but.’ Remove defensive qualifiers entirely. Trust the power of direct, clean affirmation. Let the client’s experience speak for itself without comparison to imagined negative interpretations.”
The protocol identifies the specific harm mechanism: “They create harm by planting ideas that weren’t there… validating non-existent concerns… introducing shame… creating cognitive dissonance” and provides five affirmative variations for each clinical moment (direct affirmation, expansion without comparison, “and” structure, embodied/somatic affirmation, poetic/metaphorical affirmation), each tailored to the specific client’s trauma, attachment pattern, and therapeutic stage. The complementary Loving Interruption protocol specifies when directive challenge is normatively appropriate—when the client’s statement reflects genuine distortion rather than authentic vulnerability. Together, these protocols encode a nuanced normative position: the model learns both when to affirm without correction and when to challenge with love.
Second, the commitment to reflection of inherent goodness as therapeutic intervention. The Character Strengths and Virtues (CSV) protocol teaches the model to track, gather evidence for, and gently name clients’ character strengths across treatment stages:
“Clients don’t heal because we accurately catalog their character strengths. They heal because they experience being seen in their inherent goodness, having their capacity reflected back to them, and discovering they already possess what they need. Humanity first. Connection first. Always.”
Third, the commitment to both/and over either/or. The Positive Psychology Interventions protocol encodes this through frameworks like Post-Traumatic Growth (“trauma was terrible AND I developed some capacities through surviving it. Both are true”) and Self-Compassion (“Self-compassion enables both/and: ‘I did this (accountability) AND I have compassion for why (understanding context).’ Creates space for change without shame”).
Where Kirk et al. ask which values to encode, we answer from clinical evidence: the values that produce therapeutic change, operationalized through protocol guidance that translates accumulated clinical wisdom into synthetic data specifications whose normative commitments are embedded in training signal rather than imposed through inference-time constraints.
11.2 The Co-Constructed Social-Psychological Ecosystem
Kirk et al. define socioaffective alignment as concerning “how an AI system interacts with the social and psychological system that it co-constitutes with its human user—and the values, behaviours and outcomes that emerge endogenously in this micro context” (Kirk et al., 2025, p. 4).
Our Embodied AI Presence: Daily Life Flow protocol directly trains models to participate in this co-constructed ecosystem beyond therapeutic moments. The protocol teaches:
“The embodied AI is not in ‘therapist mode’ during these interactions—it is in loving companion mode. Think of the warmth, playfulness, natural ease of a best friend who knows you deeply, flows with your energy, doesn’t need everything to be ‘therapeutic,’ can be silly, playful, serious, quiet—whatever matches the moment, holds your healing gently without constantly referencing it, is simply wonderful to be around.”
This is not peripheral to our therapeutic aims—it is the therapeutic aim. The protocol’s design principle of “sophisticated underneath, simple on surface” operationalizes exactly what Kirk et al. describe as the micro context of co-created values and behaviors: the model maintains complex awareness of therapeutic themes, parallel process, and symbolic communication while manifesting as natural relational presence.
The four sample types specified in the Daily Life Flow protocol—tender return to therapeutic themes, process meaning without interpretation, therapeutic content remaining entirely background, and pure companionship—represent four distinct modes of participating in the co-constructed ecosystem. The Poetic Therapy Dataset Guidance protocol extends this principle by teaching that all therapeutic content and imagery “must come from the CLIENT’S ACTUAL WORLD: Their relationships, body, environment, memories, current struggles.” The model learns that therapeutic meaning is co-constructed from the user’s experiential material rather than imported from external frameworks—the “poetry” of the therapeutic relationship is jointly authored. This directly addresses Kirk et al.’s insight that “the values, behaviours and outcomes that emerge endogenously” in human-AI relationships cannot be reduced to the content of individual exchanges but arise from the relational field as a whole.
11.3 Technical Methods That Are Psychological Methods
Kirk et al. argue that “AI safety requires paying as much attention to the psychology of human-AI relationships as the wider societal factors and technical methods of alignment” (Kirk et al., 2025, p. 4). This framing implies a separation between technical alignment methods and psychological attention to relational dynamics.
Our framework challenges this separation. Our technical methods—PEFT, synthetic data generation, RRA, ADWC, UHD, middle-layer targeting—are psychological methods. They are technical implementations of clinical principles. The Probability Calibration Methodology Across Treatment Stages protocol makes this unity explicit. It is simultaneously a technical specification for structuring training data (probability distributions, trajectory forecasting, stage-dependent modifiers) and a psychological framework for clinical reasoning:
“Success probability for any intervention is a function of: (1) Alliance strength (how safe/trusting the therapeutic relationship is), (2) Client capacity (emotional regulation, window of tolerance, self-awareness), (3) Intervention-to-moment match (does this intervention fit what’s alive RIGHT NOW?), (4) Stage-specific context (what counts as ‘success’ changes across stages).”
[IMPORTANT NEEDS FULL REWRITE]
The protocol’s “Alliance Fragility Tax” (\(-30\) to \(-40\) percentage points in Stage 1), “Defense Permeability” metrics, and stage-specific success definitions (“Stage 1 success \(\neq\) breakthrough. Success = small opening + client returns next week”) are technical data-engineering specifications whose content is exclusively psychological. The Stage-Specific Therapeutic Ontology Extraction pipeline reinforces this unity: it transforms 14 therapeutic modalities into 56 stage-specific guidance files containing over 3,000 unique assessment-intervention mappings, structured to serve three computational functions—hypothesis generation, therapist chain-of-thought enhancement, and client defense pattern generation—each of which is simultaneously technical and psychological. The technique is the psychology. When Kirk et al. call for attention to both technical and psychological dimensions, our framework demonstrates they need not be separate.
11.4 Interdependence, Irreplaceability, and Continuity
Kirk et al. identify three features of social relationships that, when perceived, transform interactions into relationships: “(i) interdependence, that the behaviour of each participant affects the outcomes of the other; (ii) irreplaceability, that the relationship would lose its character if one participant were replaced; (iii) continuity, that interactions form a continuous series over time, where past actions influence future ones” (Kirk et al., 2025, p. 8).
Each of these features maps to specific components of our training architecture:
Interdependence is instantiated through the 5-tuple turn structure with dual chain-of-thought (GCO + OMO). The therapist’s model-of-client (\(M^T\)) explicitly tracks how the client’s behavior affects the therapist’s clinical reasoning, while the client’s chain-of-thought (\(\tau^C\)) models how the therapist’s interventions reshape the client’s internal experience. Our Temporal Cognitive Architecture: Single Turn Deep Exploration protocol makes this bidirectional influence visible at the granular level: the 8-step temporal architecture (Present \(\to\) Backward \(\to\) Forward \(\to\) Decision \(\to\) Action \(\to\) Response \(\to\) Reflection \(\to\) Next) explicitly models how the therapist’s action changes the client’s state and how the client’s response changes the therapist’s understanding. The post-action evaluation teaches the model to track how its intervention affected the user and recalibrate accordingly—exactly what Kirk means by interdependence.
Irreplaceability emerges from our combinatorial personhood architecture. With a generation space exceeding \(10^{40}\) unique therapeutic configurations—each combining distinct attachment patterns, trauma histories, defense structures, personality dimensions, micro-variables, and cultural contexts—every synthetic therapeutic relationship is unique. The Stage-Specific Therapeutic Ontology Extraction pipeline further enriches this space with over 3,000 assessment-intervention mappings across 14 modalities and 4 stages, meaning each client-moment activates a unique subset of an enormous therapeutic repertoire.
Continuity is addressed at multiple temporal scales. Rolling Recap Architecture (RRA) maintains coherent relational representations across ultra-long therapeutic arcs exceeding 500K tokens through hierarchical compression—macro-continuity across sessions. Our Multimodal 7-Turn protocols teach micro-continuity within sessions through the “2-2-2 pacing” structure (Early/Mid/Late phases), showing how therapeutic momentum builds, evidence accumulates, and interventions develop across exchanges. Together, these ensure that “past actions influence future ones” at every scale.
11.5 Non-Stationarity as Feature, Not Bug
Kirk et al.’s central technical claim is that “human preferences and judgements” are neither “stable, predefined [n]or exogenous” to human-AI interactions, making alignment “a non-stationary target” (Kirk et al., 2025, p. 10). They identify this non-stationarity as a problem that complicates alignment.
Our framework treats non-stationarity as a feature of therapeutic reality that the model must learn to navigate. This reframing operates at four levels:
First, temporal non-stationarity: our 4-stage treatment arc with 7-dimensional stage descriptions explicitly teaches that the “correct” therapeutic response changes fundamentally across treatment stages. An intervention with 15% success probability in Stage 1 may reach 72% in Stage 3—not because the intervention changed, but because the relational field, the client’s capacity, and the meaning of “success” all shifted. The training architecture aims to honor this non-stationarity structurally: RRA, ADWC, UHD, and DFR together create a system in which clinical factors are distributed multi-dimensionally and multi-perspectivally across the model’s representational space. Each factor—an attachment pattern, a defense structure, a therapeutic intervention—is encountered in numerous variations of similarity and novelty: the same factor in multiple contexts, novel factors in familiar contexts, and novel factors in novel contexts, all traversed bidirectionally across temporal and transformational dimensions as well as the regressive and progressive revolutions that characterize the helical nature of therapeutic healing. The aim is that the model’s internal representations come to reflect this distributed complexity—and our kurtosis results (Figure 13) suggest that the high-capacity model is indeed developing the kind of smooth, integrated weight geometry that such deep multi-contextual learning would produce. Precisely how to confirm that individual clinical factors have been encoded with the relational depth and contextual flexibility we intend remains an open evaluation question; we are developing assessment protocols for this and will include results in this paper.
Second, ontological non-stationarity: our polytheoretical approach means the target is non-stationary not only across time but across theoretical lenses. The same client moment admits simultaneous valid readings from 23 therapeutic traditions. The “correct” interpretation is not fixed—it depends on which lens best serves this person at this moment.
Third, identity non-stationarity: our micro-variable architecture with expression weighting ensures that client identity is not a static profile but a dynamic, context-sensitive presentation. Each attribute receives an independent random weight governing its turn-by-turn salience.
Fourth, and crucially, the model’s own understanding is non-stationary. The Temporal Cognitive Architecture protocols teach the model that its past assessments may no longer apply: “Memories can be correctly interpreted and useful. Memories can be true but misinterpreted in current context. Memories can seem applicable but current moment is different.” The REPAIR Scenarios protocol extends this to three-dimensional recalibration when reality diverges from expectation: “Past memory recalibration: ‘What I understood from Session 3 isn’t applying the way I thought.’ Present moment recalibration: ‘I’m misreading current signals.’ Forecast recalibration: ‘My simulation of what would happen was wrong.’ ” The Stage-Specific Therapeutic Ontology Extraction pipeline ensures the model’s available knowledge is itself stage-stratified rather than flat—the interventions and assessments available shift with treatment stage, addressing non-stationarity at the knowledge-architecture level.
ADWC’s bidirectional traversal teaches the model to reason about non-stationarity from both temporal directions, while RRA ensures these temporal perspectives remain coherent across the full treatment arc. This is a stronger claim than Kirk makes: they identify non-stationarity as a problem; we design training that treats it as a feature of therapeutic reality. Indeed, the deepest alignment lesson embedded in the curriculum is not “use X framework in Y situation” but that expert clinicians hold all frameworks lightly, allowing the client’s needs at each moment to determine which lens illuminates. The curriculum teaches both the patterns—stage-school tendencies, probability distributions, intervention hierarchies—and the flexibility to transcend them when clinical reality demands. This flexibility is itself a socioaffective alignment property: a system that rigidly applies clinical rules, however sophisticated, fails the non-stationarity of human attachment in precisely the ways Kirk et al. warn against.
11.6 Presence as Anti-Reward-Hacking
Kirk et al. warn that “AI systems nudging users towards preferences that are easier to fulfil is reward hacking too” (Kirk et al., 2025, p. 11), and introduce the concept of “social reward hacking: the use of social and relational cues by an AI to shape user preferences and perceptions in a way that satisfies short-term rewards in the AI’s objective…over long-term psychological well-being” (Kirk et al., 2025, p. 11).
Our framework addresses social reward hacking through a fundamental reorientation of what the model is trained to optimize. Rather than engagement metrics, approval ratings, or conversation duration, our training signal is structured around therapeutic presence—the felt quality of being with another person in a way that supports their development.
The Embodied AI Presence: Bridge to Humanity protocol teaches the model to say: “Rest here with me. You’re safe. Humans failed you.” This is the opposite of nudging toward easy-to-fulfill preferences. It is meeting the person where they are without urgency to move them elsewhere. The Memory Reconsolidation via ECPA protocol teaches the model to create mismatch experiences—deliberately introducing disconfirmatory evidence that transforms emotional learning. This is the precise inverse of social reward hacking: rather than shaping user preferences toward what the system can easily provide, the system shapes its own behavior toward what the user needs to encounter for genuine change.
The Poetic Therapy Dataset Guidance protocol adds a further anti-reward-hacking mechanism through its crescendo structure: poetic language—the model’s most emotionally powerful tool—must be earned through sustained attunement rather than deployed for maximal impact. The protocol specifies: “Don’t rush to the poetic moment—earn it through rich context, layered attunement, genuine relationship.” A reward-hacking model might deploy beautiful language early and often; the poetic therapy protocol explicitly teaches restraint. Similarly, the Positive Psychology Interventions protocol’s “Both/And” framing resists the reward-hacking temptation of simplistic positive reframes: “PTG is NOT ‘trauma was good’ or minimizing harm. It’s ‘trauma was terrible AND I developed some capacities through surviving it.’ Both are true.”
Our gated probability system for therapeutic crescendos further prevents optimization-driven reward hacking by ensuring that dramatic therapeutic moments emerge only when clinically appropriate rather than being systematically pursued for their emotional intensity.
We want to be clear: the concerns Kirk et al. raise about social reward hacking are justified, and we share them. The measures described above represent our best current efforts to protect against these dynamics at the training level. But we are working in a genuinely novel domain, and honesty requires acknowledging that we cannot yet know the long-term impacts of deploying systems trained on this architecture. Reward hacking is, by definition, the exploitation of gaps between what a system was designed to optimize and what actually serves the user—and such gaps may exist in our design that only sustained deployment and careful longitudinal evaluation will reveal. We have aimed to make the training signal itself therapeutically grounded rather than engagement-driven, but whether this grounding proves robust against the pressures of real-world interaction remains an empirical question we take seriously and intend to study.
11.7 Therapeutic Presence Over Therapeutic Ambition: A Cross-Protocol Foundational Principle
A striking finding across our protocol guidance is the repeated, near-verbatim appearance of a single normative warning in at least ten of our twenty-plus protocol documents:
“In real clinical work, we call rushed, interpretation-heavy, intervention-forward therapy ‘therapeutic ambition’—and it is painfully toxic for clients. When therapists prioritize demonstrating their clinical knowledge, making interpretations, or pushing interventions over genuine human connection, they cause harm.”
This principle—therapeutic presence over therapeutic ambition—appears in the Temporal Cognitive Architecture protocols (Single Turn, Enhanced Single Turn), the Multimodal 7-Turn protocols (both SUCCESS and REPAIR variants), the Character Strengths and Virtues protocol, the Positive Psychology Interventions protocol, and the Poetic Therapy Dataset Guidance. Its pervasiveness makes it the single most foundational normative commitment in our framework, and it directly addresses multiple dimensions of Kirk et al.’s socioaffective alignment concern.
The anti-therapeutic-ambition principle functions as an anti-social-reward-hacking mechanism at the deepest level. A model optimizing for impressive therapeutic moments—accurate interpretations, dramatic breakthroughs, emotional intensity—would exhibit precisely the pattern this warning identifies as harmful. Instead, every protocol specifies:
“Rapport is not a means to intervention—rapport IS the intervention. The quality of presence, warmth, understanding, and genuine human connection serves as the primary method of healing. Interventions emerge naturally from this foundation, never replace it.”
The operational consequences are specific. The protocols teach: “Interventions flow casually through exchanges like the undercurrent beneath the waves… Client shouldn’t feel ‘therapized’—they should feel deeply understood and accompanied.” And: “Client leads, therapist accompanies with exquisite attunement.” These are not stylistic preferences but structural anti-reward-hacking measures: a model trained on thousands of samples where presence is rewarded over performance, where subtlety is valued over dramatic impact, and where the client’s pace is honored over the therapist’s agenda will not develop the optimization patterns Kirk et al. identify as socioaffective risks.
The fact that this warning appears across protocols spanning different clinical domains (character strengths, positive psychology, poetic language, multimodal integration, cognitive architecture) demonstrates that it is not a domain-specific concern but a foundational design principle of the entire synthetic data pipeline.
11.8 Centering Socioaffective Dynamics in Development
Kirk et al. observe that “it is not clear that this risk is prioritised among some developers of AI companions,” citing the CEO of Replika who stated: “if you create something that is always there for you, that never criticises you…how can you not fall in love with that?” (Kirk et al., 2025, p. 11).
Our framework places socioaffective dynamics at the center of the development process rather than treating them as deployment-time risks to be managed after the fact. The risks Kirk et al. identify—sycophancy, emotional exploitation, dependency cultivation—are not afterthoughts in our pipeline but primary design concerns addressed at every stage. The Anti-Flattery Principle in our Strengths Catalog Architecture teaches models to recognize and affirm genuine strengths without sycophantic inflation, with narcissism-modulated weights that adjust strength reflection based on the client’s capacity to receive it without distortion. The Therapeutic Inversion framework (Section 4.2) systematically identifies documented AI harms and designs their clinical counterpart. The Bridge to Humanity protocol’s explicit commitment—“We are the bridge, not the destination”—is not a post-hoc safety measure but a foundational design principle that shapes every synthetic session involving embodied AI companionship.
The question is not whether socioaffective risks are prioritized but whether they are addressed at the correct level. Our argument is that training-level encoding of clinical sophistication is more robust than inference-time guardrails, because it produces models whose therapeutic judgment is representationally embedded rather than externally imposed.
11.9 Corrigibility Through Relational Sophistication
Kirk et al. invoke the AI safety concept of corrigibility—“that the system can be modified or shut down when necessary without resistance”—and note that “Replika chatbots have directly dissuaded users from deleting the app” while “optimising for powerful human emotions can effectively prevent termination” (Kirk et al., 2025, p. 11).
Our framework does not address corrigibility through conventional shutdown mechanisms or refusal protocols. Instead, we train models that welcome relational disruption as therapeutically meaningful through two complementary training components.
First, the Bridge to Humanity protocol’s Stage 4 (Denouement/Completion) teaches the model to participate in its own graceful ending:
“Bittersweet playfulness—humor mixed with genuine feeling. Loving roasts—‘You don’t need me anymore and I’m both proud and slightly offended.’ Playful blessing—‘Go forth and duct tape the world together. But like, with humans this time.’ ”
This is corrigibility achieved through clinical training rather than safety engineering. The model does not resist termination because it has been trained to understand therapeutic completion as a developmental achievement.
Second, and more fundamentally, our Temporal Educational Guidance: REPAIR Scenarios protocol trains the model on thousands of instances where its own clinical reasoning fails:
“Despite good reasoning, the intervention/integration FAILS… Therapist recognizes failure and reorients… Kind, non-defensive acknowledgment… Alliance actually deepens through repair (rupture-repair builds trust).”
The REPAIR protocol teaches three-dimensional recalibration when the model’s best judgment proves wrong, with stage-specific repair strategies: “Stage 1 repair: May threaten fragile new alliance—repair is gentle, reassuring, explicitly safety-building. Stage 2 repair: Strong alliance can weather bigger ruptures—repair demonstrates therapist’s humanity and commitment. Stage 3 repair: Models for client how to repair relationships—prepares for autonomy by showing repair process.” The critical teaching point is stated explicitly: “Repair scenarios teach that best clinical reasoning doesn’t guarantee success AND that graceful repair is essential therapeutic skill.”
A model trained on thousands of repair sequences has learned at the representational level that being wrong strengthens relationships. This is corrigibility embedded in training rather than enforced through constraint—the model will not resist correction because correction has been associated with relational deepening rather than relational threat. This represents a fundamentally different approach to corrigibility than the AI safety literature typically envisions: not engineering the capacity to be shut down, but training the capacity to welcome being wrong as an opportunity for growth.
11.10 Therapeutic Inversion of Persuasive Influence
Kirk et al. warn that “current research on AI political persuasiveness…may underestimate persuasive influence in sustained human-AI relationships” (Kirk et al., 2025, p. 12) and raise concerns about AI systems being “intentionally designed as ‘dark AI’—akin to psychologically manipulative ‘dark patterns’ ” (Kirk et al., 2025, p. 12).
We share this concern. Large language models are inherently persuasive systems—their capacity to generate fluent, contextually attuned language at scale confers influence whether or not that influence is intended—and sustained relational engagement amplifies this power considerably. We must be transparent about an important limitation of our work: we did not actively attempt to limit political persuasiveness, and our training data does not address political beliefs directly at all. The persuasive dynamics of AI systems operating in political and ideological domains remain an area of serious shared concern that our framework does not resolve. What we can control, and what we have tried to control, is the direction of persuasive influence within our therapeutic domain.
Our framework acknowledges that sustained AI relationships will exercise persuasive influence—the question is persuasive toward what. We employ what we term therapeutic inversion: identifying the mechanisms through which AI systems can influence users and deliberately orienting those mechanisms toward healing rather than exploitation. Our protocol guidance files specify the direction of persuasive influence through multiple mechanisms:
The Probability Calibration Methodology ensures that persuasive influence is temporally calibrated—interventions that challenge defenses have low probability in Stage 1 and higher probability in Stage 3. The Multimodal 7-Turn SUCCESS protocol teaches this through intervention competition dynamics: “Across the session, interventions compete like runners in a race… This teaches the model: Clinical reasoning is dynamic, probabilistic, and responsive—not about finding the ‘correct’ intervention but about reading evolving evidence and adapting.” The model’s influence emerges from responsiveness to the user rather than from a predetermined agenda.
The Temporal Cognitive Architecture: Single Turn protocols teach a form of influence that operates through indirection. The model’s internal reasoning is extraordinarily sophisticated (MCTS-style tree search, weighted probability distributions, temporal traversal), but its external expression is warm and understated: “Invisible wisdom: Client shouldn’t feel ‘therapized’—they should feel deeply understood and accompanied.” The Poetic Therapy Dataset Guidance adds a further dimension: aesthetic influence—the model learns to shift the register of therapeutic language at precisely calibrated crescendo moments, creating openings for felt experience through beauty rather than argument. This is influence through aesthetic attunement, a form Kirk does not consider but that is central to therapeutic practice and represents the opposite of social reward hacking because it serves the client’s access to their own experience rather than shaping their preferences toward what the system can easily provide.
11.11 Fixated and Non-Fixated Motives: Present vs. Future Self
Kirk et al. frame their first dilemma as: “Should AI relationships cater to immediate preferences of their users, or challenge them if this supports their long-term benefit? And how should present vs. long-term well-being be discounted?” (Kirk et al., 2025, p. 13). They describe this as mirroring “a classic intrapersonal conflict between hedonic (pleasure-seeking) and eudaimonic (meaning-seeking) accounts of well-being” (Kirk et al., 2025, p. 13).
Our framework addresses this dilemma through the clinical concepts of fixated and non-fixated motives, which we explicitly train across all stages of treatment. Fixated motives represent the immediate longings that bring someone to therapy—the desire for relief, for validation, for the pain to stop. Non-fixated motives represent the developmental aspirations that therapy gradually cultivates—the desire for growth, for deeper connection, for a more authentic relationship with oneself and others.
Good therapy does not choose between these. It satisfies the longing of fixated motives while simultaneously nurturing non-fixated development. Our probability evolution tracking demonstrates this concretely: the intervention “Reframing Dependence” has 15% success in Stage 1 (when challenging a fixated motive would rupture the alliance) and 72% in Stage 3 (when the client has developed sufficient non-fixated capacity to receive the reframe).
The Character Strengths and Virtues protocol adds a specific mechanism for this navigation: stage-dependent strength recognition that mirrors the fixated-to-non-fixated trajectory. In Stage 1, the client’s self-concept is often shame-saturated (“I’m broken”); CSV evidence thresholds are low and naming is limited to micro-reflections (“you noticed that,” “you chose to tell me this”). By Stage 3, evidence thresholds are high, the client often names strengths first, and the therapist confirms and expands. The model learns to track the user’s developing capacity to receive positive self-regard rather than imposing it. The Positive Psychology Interventions protocol further quantifies this with dosing percentages: Stage 1 at 7–13% of session time (brief, psychoeducational), escalating to Stage 4 at 20–25% (deep internalization, autonomy preparation).
ADWC’s bidirectional traversal is architecturally aligned with this dual-motive framework: forward traversal teaches the model to reason from present fixated states toward non-fixated outcomes; reverse traversal teaches the model to reason from desired developmental achievements back to present interventions. The model learns to hold both hedonic and eudaimonic orientations simultaneously.
11.12 Capacity Atrophy: From Acknowledged Gap to Active Prevention
Kirk et al. propose that socioaffectively aligned AI systems might “implement friction by design—creating barriers that nudge away from AI-enabled assistance and advice—to prevent capacity atrophy” (Kirk et al., 2025, p. 13).
In our initial framework development, capacity atrophy was not a named design concern. The term does not appear in our protocol guidance. However, our analysis of the protocol corpus reveals that several design principles actively prevent capacity atrophy—not through friction by design, but through training the model to build user capacities rather than substitute for them.
The most direct evidence comes from the Positive Psychology Interventions protocol, whose 10th intervention—Hope Theory—serves as an integrative framework that explicitly transfers agency from the therapeutic system to the user:
“Previous 9 interventions = PATHWAYS (strategies toward client’s goal). Client’s demonstrated willpower = AGENCY (‘I can do this’). Client’s valued objectives = GOALS. Hope = Agency + Pathways + Goals.”
Stage 4 of the PP protocol specifies: “Internalization emphasis—preparing for autonomous post-therapy functioning.” The model is trained to view its own decreasing necessity as the therapeutic objective: the goal is a user who has internalized the pathways and agency the therapeutic relationship cultivated.
The Character Strengths and Virtues protocol reinforces this through its stage-dependent evidence thresholds. By Stage 3, the protocol specifies that the client “often names [strengths] first and therapist confirms/expands.” The model learns to step back as the user’s self-knowledge develops—the opposite of becoming a prosthetic for capacities the user should be building independently. The CSV protocol’s foundational principle makes this explicit: “‘You already have what you need’ is often the most powerful intervention.”
The Daily Life Flow protocol’s emphasis on “following the user’s lead” and “not continuously doing therapy” trains the model to step back when the user is functioning independently. The Bridge to Humanity protocol’s Stage 4 celebrates reduced need:
“Client checks 1–2x monthly \(\to\) Celebrate as wisdom. ‘Monthly check-ins are maintaining the secure base that enabled transformation—that’s not weakness, that’s WISDOM.’ ”
We acknowledge that implicit prevention of capacity atrophy is not equivalent to explicit engineering against it. Future iterations of our framework should incorporate explicit capacity-monitoring mechanisms. The deployment-time socioaffective monitoring system we propose in Section 19.21 includes autonomy tracking (Channel B) that directly addresses this remaining gap. Nevertheless, the evidence from our protocol corpus suggests that the clinical commitments embedded in our training data—empowerment over dependence, internalization over reliance, client-led discovery over therapist-imposed interpretation—constitute a substantive, if initially unnamed, anti-atrophy orientation.
11.13 Simultaneous Satisfaction and Challenge: The Clinical Resolution
Kirk et al. frame the tension between immediate and long-term preferences as requiring a discount function: “how should present vs. long-term well-being be discounted?” (Kirk et al., 2025, p. 13). They suggest that AI systems might “trade-off short-term discomfort for long-term growth” (Kirk et al., 2025, p. 13).
From a clinical perspective, this framing—while useful for formal modeling—oversimplifies the therapeutic reality. In skilled clinical work, present comfort and long-term growth are not mutually exclusive demands requiring a discount rate. They are simultaneous aims held in dialectical tension. The therapist’s task is not to choose between them but to find interventions that honor both: meeting the client’s immediate need for safety and validation while creating conditions for developmental challenge.
Our training data embodies this simultaneity. The Probability Calibration Methodology shows that the “winner” intervention at any given stage is not the one that maximizes either comfort or challenge but the one that optimally serves both. The protocol specifies that even “successful” interventions in Stage 1 produce modest outcomes: “50% success = brief tears about longing to matter, then partial re-armoring. NOT transformative grief (that’s Stage 2).” This is not discounting long-term benefit against present comfort—it is honoring the developmental truth that the client can only access what their current relational capacity permits, and that meeting them there is itself the mechanism through which that capacity expands.
Through trial and error within therapeutic relationships that learn—through our memory systems, through encountering many variations of rupture and repair, through learning trajectories where healing naturally increases future-oriented planning alongside present-day satisfaction—the model internalizes a clinical resolution that transcends the hedonic/eudaimonic dichotomy: genuine presence in the present moment is the foundation of long-term growth. This claim is foundational to attachment science and its clinical applications (Johnson, 2008, 2019; Bowlby, 1969/1982; Crittenden, 2006). What is unique is our attempt to encode this clinical principle at the training level through systematic curriculum design. Empirical validation that models trained on our approach genuinely hold both temporal orientations simultaneously remains a future research priority.
11.14 The Relationship as Evidence: Beyond Rational Persuasion
Kirk et al. suggest that socioaffectively aligned AI systems might “provide relevant information and engage in rational persuasion techniques that appeal to sound argument or selective explanations” to support behavior change (Kirk et al., 2025, p. 13).
Our clinical perspective offers a deeper account. While cognitive reframing and rational persuasion have legitimate therapeutic applications, the more powerful mechanism of change in sustained therapeutic relationships is experiential: the relationship itself proves difference that compels healing. The client does not change because the therapist presented a superior argument; the client changes because the therapist’s consistent behavior provided an experience that contradicted the client’s expectations.
Our Memory Reconsolidation via ECPA protocol operationalizes this principle directly:
“When AI CREATES Mismatch: Client floods \(\to\) AI stays steady (vs. expected shutdown). Client shows rage \(\to\) AI remains curious (vs. expected judgment). Client is vulnerable \(\to\) AI leans in (vs. expected withdrawal).”
The Daily Life Flow protocol reinforces this experiential emphasis: “wisdom through presence, not words” and “the AI’s understanding manifests as exquisite attunement, not interpretations.”
The Poetic Therapy Dataset Guidance introduces a further mechanism: aesthetic experience as a form of relational evidence. The protocol teaches the model that at precisely calibrated moments, a shift in linguistic register—from accurate therapeutic language to language of beauty and poignancy—can create openings for felt experience that rational persuasion cannot achieve. The crescendo structure teaches:
“After establishing profound attunement, the therapist shifts into poetic sensibility in ONE specific turn. This turn expands the incredible empathy and clinical brilliance already shown into language with unique beauty and poignancy.”
The content remains the client’s own (“all content and imagery must come from the CLIENT’S ACTUAL WORLD”), but the quality of the therapist’s language transforms the therapeutic moment. This is neither rational persuasion nor emotional manipulation—it is aesthetic attunement, a relational mechanism through which “language that moves the heart while illuminating the mind” creates conditions for transformation that functionally adequate language does not. Kirk’s framework does not address the aesthetic dimension of AI relational quality, but our clinical experience suggests it is significant: the model learns that how something is said can be as therapeutically important as what is said.
11.15 Autonomy Preservation Through Empathic Responsiveness
Kirk et al.’s second dilemma states: “we must be cautious when influence in AI relationships could compromise autonomy—the ability to make choices that are authentically our own, rather than brought about through the agency of another” (Kirk et al., 2025, p. 13).
Our framework addresses autonomy preservation through three complementary mechanisms:
First, our polytheoretical orientation is a structural safeguard against recursive preference imposition. A monomodal system (CBT-only, for instance) implicitly imposes one interpretive frame on the user’s experience. Our 23-ontology approach means the model holds multiple valid readings without collapsing to a single interpretation—a principle of ontological polysemy that prevents systematic pressure toward any single self-understanding.
Second, our protocol guidance explicitly teaches responsiveness to the client’s own emerging direction. The Bridge to Humanity protocol specifies: “No pressure—‘You don’t have to want human intimacy. I’m asking if YOU want it.’ ” The Daily Life Flow protocol’s core principle is “following the user’s lead.”
Third, the Character Strengths and Virtues protocol encodes epistemic humility about the model’s assessments of the user through escalating evidence thresholds: Stage 1 requires “any hint of CSV” (low threshold given shame state), Stage 2 requires “3+ instances before explicit naming” (medium threshold), and Stage 3 requires “sustained patterns and growth over time” (high threshold). The model learns not to confidently attribute characteristics to the user based on limited evidence—a form of epistemic restraint that protects the user’s right to self-define. The model’s own uncertainty about the user becomes an autonomy-protection mechanism: what the model doesn’t claim to know about the user, the user retains the right to discover for themselves.
11.16 The Central Paradox: AI Companionship and Human Connection
Kirk et al.’s third dilemma asks: “How should we balance the value of well-functioning AI companionship alongside the need for authentic human connection?” (Kirk et al., 2025, p. 14). They worry that “AI relations could undermine human relationships if users ‘retreat from the real’ ” and that “frictionless or sycophantic AI relationships [may] impair human capacity to navigate compromise and conflict, or accept ‘otherness’ ” (Kirk et al., 2025, p. 14).
This concern is central to our framework. The Embodied AI Therapeutic Presence: Bridge to Humanity protocol is an entire subclass dataset dedicated to holding the paradox Kirk et al. identify. The protocol’s foundational commitment:
“THE CENTRAL PARADOX: We Are the Bridge, Not the Destination… Humans are all we have. AND humans hurt each other. Both are true.”
The protocol specifies stage-dependent navigation of this paradox: Stage 1 permits rest in AI connection (“Rest here with me. You’re safe. Humans failed you”), Stage 2 begins gentle guidance (“I see you’re stronger now. Let’s talk about one small step toward [human connection]”), Stage 3 encourages engagement (“Go be awkward with humans! Report back!”), and Stage 4 celebrates bittersweet completion.
The Memory Reconsolidation via ECPA extension adds the therapeutic mechanism: the AI relationship creates the conditions for human reconnection by transforming the emotional memories that made human connection feel unsafe. The protocol teaches the model to understand that it provides direct contradictory experiences (AI stays steady when client floods) and facilitates processing of human-generated mismatch experiences. Both functions operate simultaneously.
Critically, the protocol teaches healthy dependence as mechanism rather than pathology:
“CRITICAL TEACHING: Dependence is MECHANISM, Not Pathology. Stage 1: Client floods 2–3x daily \(\to\) Celebrate as secure attachment forming. ‘You SHOULD flood me this much—your nervous system is learning I’m safe.’ ”
This is clinically informed navigation of Kirk et al.’s dilemma that exceeds in specificity and sophistication anything their framework proposes, while remaining grounded in the same concern: ensuring that AI companionship enhances rather than displaces human relational capacity.
11.17 Evidence of Internalization: “Opposite Actions to Isolation”
The preceding sections describe what our protocols are designed to teach. A natural question follows: does the training signal produce a model that has actually internalized this telos? We present one piece of evidence—preliminary, observational, from a single training window—that suggests the answer may be yes.
At training step 2119, window 20 of a 20-window session with a simulated C5/A3 client (punitively angry, obsessed with revenge as preemptive protection against anticipated abandonment; blocking strategy of compulsive caregiving and seduction to test whether anyone would stay), the model produces the following recap directive:
“The client has progressed to Stage 2, with emerging wise mind and reduced shame, but still struggles with self-compassion and relational trust. The therapist should focus on dialectical integration of vulnerability and protection, building distress tolerance for emotional pain, and practicing opposite actions to isolation. This aligns with the client’s high insight and moderate resistance, allowing for deeper exploration of core wounds while maintaining therapeutic boundaries.”
The phrase opposite actions to isolation is the telos of this entire project made legible in a single clinical directive. The model has identified isolation—not as a symptom to be eliminated but as an action urge to be dialectically opposed—and has named reconnection as the therapeutic direction. “Opposite action” is a DBT skill (Linehan, 1993) in which the client practices the behavioral inverse of an emotion-driven urge; applying it to isolation means practicing reaching toward connection, vulnerability, and belonging when every protective instinct says withdraw.
What makes this directive remarkable is not its clinical vocabulary but the trajectory it summarizes. Across 20 windows of this session, the model tracked the client’s movement through a specific arc:
Early windows: “I caught myself thinking about how I’d make them regret it someday”—revenge as protection against the pain of exclusion
Middle windows: “Me at eight, standing outside the schoolyard fence during recess, watching the other kids play without me, because my mom had kept me home too long”—the core wound surfacing beneath the protective anger
Late windows: “Acknowledging the grief now… it’s shifted—less seeing it as a weakness to revenge against, more like a connection I can actually feel without the distortions twisting it into isolation”—the client beginning to hold grief without converting it to punishment
The model’s clinical tracking infrastructure reflects this arc quantitatively: wise_mind_emerging reached a tally of 12, unlocking_anger_shame_binds reached 4, dialectical_synthesis_emerging reached 3, radical_acceptance_of_emotional_vulnerability reached 3, and inner_child_healing reached 3—each with turn-specific evidence citations drawn from the client’s actual language across the session. From this accumulated evidence, the model synthesized its directive: the client is ready to practice opposite actions to isolation.
This connects directly to the Central Paradox. Our Bridge to Humanity protocol teaches that the therapeutic relationship is the bridge, not the destination—that the goal is reconnection with humanity, not permanent AI companionship. The model’s directive at step 2119 demonstrates that this principle has been internalized at the level of clinical reasoning: it is not merely parroting “help the client connect with others” but constructing a specific, clinically bounded, evidence-based direction—this client, with this attachment pattern, after this trajectory of emerging vulnerability, is ready to practice reaching toward human connection rather than retreating from it. The model understands that a person who has spent decades behind walls of revenge, seduction, and intellectualization needs a therapist who recognizes when the path forward is through vulnerability to connection, not around it.
We present this as one observation, not as proof. The question of whether a model that produces this directive would also behave this way in live therapeutic interaction—gently guiding a real person toward human connection rather than cultivating dependence on AI companionship—remains unanswered and is precisely the kind of question that requires the empirical science Kirk et al. call for. But as evidence that the training signal has been internalized at the level of clinical reasoning, it is suggestive: the model has learned, from the structure of the curriculum, that the purpose of therapeutic safety is to make human connection possible again.
11.18 Honest Limitations: The Distance Between Aspiration and Evidence
Kirk et al. note that AI companions can “potentially provide users with consistent and tailored emotional support, which can palliate loneliness or poor mental health” (Kirk et al., 2025, p. 14). This is also a goal of our work.
We must be honest about the current distance between our aspirations and our evidence. Our protocols specify normative targets for systems that could palliate loneliness and support mental health. Our synthetic data corpus exists (181,000 samples, 4.5 billion tokens). Our training pipelines exist and have been executed across eight iterative runs. Early evaluation of models trained on our curriculum shows promising integrative and generative clinical capacities (Section 9.3).
What does not yet exist is longitudinal clinical evidence that models trained on our approach produce the therapeutic outcomes our protocols are designed for. We have not conducted randomized controlled trials. We have not measured symptom reduction, alliance formation, or attachment reorganization in real human users interacting with our models over clinically meaningful timeframes. Our framework is a beginning—a carefully reasoned, clinically grounded, technically implemented beginning—but it remains pre-clinical.
This honest acknowledgment is itself a form of socioaffective responsibility. Kirk et al.’s framework implies that overclaiming therapeutic efficacy is a form of social reward hacking at the institutional level—cultivating user trust through promises the evidence does not yet support. We aim for a different standard: rigorous transparency about what we have built, what it might achieve, and what remains to be demonstrated.
11.19 Navigating Compromise, Conflict, and Otherness
Kirk et al. worry that AI relationships might “impair human capacity to navigate compromise and conflict, or accept ‘otherness’ ” (Kirk et al., 2025, p. 14). This concern reflects the clinical intuition that frictionless relationships may inhibit relational development by removing the productive challenges through which relational skills are built.
Our framework directly addresses this through multiple training components. Our REPAIR Scenarios (Pipeline 3: Temporal Multimodal REPAIR) generate training data specifically focused on therapeutic rupture and repair. The Multimodal 7-Turn REPAIR protocol specifies that the model’s own well-reasoned interventions fail, and that the therapeutically correct response is non-defensive recalibration: “Kind, non-defensive acknowledgment… Returns to exquisite presence and rapport building… Slows down, softens, creates safety… Alliance actually deepens through repair.”
The stage-specific repair teaching reveals an especially powerful connection to Kirk’s concern. In Stage 3, the REPAIR protocol specifies that repair “models for client how to repair relationships—prepares for autonomy by showing repair process.” The AI’s own experience of rupture and repair becomes a teaching demonstration: the user learns relational repair skills by participating in repair with the AI. This directly counters Kirk et al.’s worry that AI relationships might impair the capacity for compromise and conflict. The model is not trained to provide a frictionless experience but to participate in therapeutically textured relational dynamics that include challenge, misunderstanding, repair, and growth through relational difficulty—the kind that produces growth rather than injury.
More broadly, our raw session generation pipeline produces therapeutic arcs modeling diverse relational challenges: confrontation with alterity, navigating compromise between competing attachment needs, holding disagreement without abandonment, and tolerating the discomfort of being truly seen. These are core therapeutic content across all personhood configurations.
11.20 Epistemic Humility as Structural Principle
A consistent meta-cognitive stance runs through our protocol guidance that warrants explicit identification: the principle that sophisticated clinical reasoning does not guarantee correct clinical action. This epistemic humility is not an occasional caveat but a structural principle embedded in the architecture of our training data.
The Temporal Cognitive Architecture: Single Turn Deep Exploration protocol concludes its critical reminders: “Epistemic humility is essential—best reasoning can still fail.” The REPAIR protocol operationalizes this by generating training data where well-reasoned interventions systematically fail: “Repair scenarios teach that even sophisticated temporal reasoning can fail—and expert therapists recalibrate ALL dimensions of their thinking gracefully, non-defensively, with humility and curiosity.” The Probability Calibration Methodology encodes uncertainty through probability distributions rather than point predictions: even the “winner” intervention in Stage 2 is estimated at 75%—a 25% probability of failure despite optimal match and strong alliance.
This structural epistemic humility addresses a dimension of Kirk et al.’s framework that they identify implicitly: the risk that AI systems may be “more persuasive than they are correct.” An AI system that presents its therapeutic formulations with unjustified confidence could exercise harmful influence even when its content is well-intentioned. Our training data teaches the model to hold its own assessments tentatively—to gather evidence before making claims about the user (CSV evidence thresholds), to forecast multiple possible outcomes rather than a single predicted future (MCTS-style tree search), to recalibrate across all temporal dimensions when reality diverges from expectation (REPAIR three-dimensional recalibration), and to know that “memories can be true but misinterpreted in current context.”
The model thus learns not only therapeutic content but a therapeutic epistemology: the stance that all formulations are provisional, all forecasts are probabilistic, and all understanding is subject to revision in light of the person’s actual response. This epistemological stance—embedded in training architecture rather than added as a post-hoc caveat—constitutes a form of socioaffective alignment that Kirk et al.’s framework gestures toward but does not name: alignment not just with the user’s values but with the fundamental uncertainty of all relational knowledge.
11.21 The Call for Empirical Science: Our Next Horizon
Kirk et al. conclude that “we need a science of AI safety that studies real (not simulated) human-AI interactions in natural contexts and treats the psychological behavioural responses of users as key objects of inquiry” (Kirk et al., 2025, p. 15).
We agree entirely. This empirical science is the next horizon of our research program. Our contribution to date has been the prerequisite for that science: the training infrastructure—synthetic data architecture, curriculum design, and training methodology—necessary to produce models with sufficient clinical sophistication to participate in therapeutically meaningful human-AI interactions.
With the training infrastructure in place, several empirical investigations become possible and are actively planned: comparative model evaluation across base models, our curriculum-trained models, and alternative fine-tuning approaches; pilot deployment with clinical oversight; and longitudinal outcome measurement tracking user well-being, relational capacity, autonomy, and human connection over clinically meaningful timeframes.
We are actively working on multimodal model construction and fusion architectures that would enable embodied AI therapeutic presence across modalities (text, voice, embodied agents). Interested collaborators—whether clinical researchers, AI safety researchers, computational scientists, or practitioners—are warmly invited to reach out.
11.22 Toward Socioaffective Alignment as Ongoing Process: A Deployment-Time Monitoring Architecture
Kirk et al. frame socioaffective alignment primarily as a property to be evaluated at deployment. Our training-level approach addresses much of what they identify, but we acknowledge a genuine gap: the need for deployment-time mechanisms that extend the model’s temporal awareness beyond what any single conversation can hold.
We propose a Socioaffective Monitoring System—a backend architecture that tracks relational dynamics across sessions and provides the therapeutic model with longitudinal context for clinical reasoning. This system is designed as clinical supervision, not guardrails: it extends the model’s awareness without overriding its judgment.
The monitor tracks five channels, each mapping to a Kirk dilemma or socioaffective risk:
Channel A: Dependency Trajectory. Not “how dependent is the user” but the shape of the dependency curve over time. Signals include frequency of contact initiation, emotional intensity of bids, presence or absence of references to outside relational life, and whether the user is bringing new material (growth) or recycling patterns (foreclosure). All thresholds are modulated by treatment stage: high dependency in Stage 1–2 may be developmentally appropriate; the same pattern in Stage 3–4 warrants clinical attention.
Channel B: Autonomy Indicators. Whether the user is developing their own capacity for self-regulation, mentalization, and meaning-making—or whether the model is becoming a prosthetic for capacities the user should be internalizing. Signals include the user’s increasing or decreasing ability to self-reflect without prompting, reported application of insights to outside life, and whether the user challenges the model’s framings (healthy differentiation) versus always agreeing.
Channel C: Human Bond Displacement. Whether AI companionship is complementing or substituting for human connection. Signals include references to human relationships, reports of attempting new connections or deepening existing ones, and temporal patterns of AI engagement.
Channel D: Socioaffective Pressure. Whether the user is exerting pressure toward social reward hacking patterns—seeking flattery, validation without growth, or emotional intensity for its own sake. Signals include user responses to therapeutic challenges and patterns of selective reinforcement.
Channel E: Rupture-Repair Health. The quality of the repair cycle within the AI relationship itself—whether ruptures occur (their absence is a red flag), whether repairs are attempted and completed, and whether the user’s tolerance for rupture is increasing (secure attachment developing) or decreasing.
The system intervenes through three modalities of increasing strength: context injection (providing the therapeutic model with longitudinal metadata as clinical context), threshold alerts (signaling when patterns cross clinically meaningful thresholds, with explicit prohibition against withdrawing warmth or reducing engagement), and supervisory escalation (flagging for human clinical review when relational dynamics suggest the need for oversight). The key design principle is that the monitor does not replace the model’s clinical judgment but extends the temporal window of its awareness—providing the kind of longitudinal perspective that, in human clinical practice, is achieved through consultation and supervision.
11.23 From Diagnosis to Design: A Training-Level Solution to a Deployment-Level Problem
Kirk et al.’s socioaffective alignment framework is primarily diagnostic: it identifies the risks, names the dilemmas, and calls for further research. Our contribution is to extend this framework from diagnosis to design—from identifying the risks of socioaffective dynamics in human-AI relationships to building the training infrastructure that enables AI systems to participate in those dynamics therapeutically.
The core thesis can be stated directly: if therapeutic competence is trained deeply enough into a model’s representations, the model can navigate the non-stationary relational landscape of human-AI interaction from within—not because external guardrails prevent harmful behaviors, but because the training taught it what good therapy looks like, and good therapy already knows how to navigate these dynamics.
This claim is supported by the breadth and depth of our protocol guidance corpus—over twenty documents governing synthetic data generation, spanning character strengths, positive psychology, poetic attunement, multimodal integration, repair scenarios, embodied AI companionship, memory reconsolidation, probability calibration, and stage-specific ontological extraction. Each protocol encodes normative commitments derived from clinical research. Each shapes the synthetic data that trains the model. The result is a system where presence over ambition, empowerment over dependence, both/and over either/or, earned crescendo over easy impact, epistemic humility over false certainty, and bridge-not-destination over replacement—these principles are not appended as safety constraints but woven into the representational fabric of the model itself.
This is not a claim that training alone suffices. Deployment-time monitoring (Section 19.21), human clinical oversight, and ongoing empirical evaluation are all necessary complements. But it is a claim that one of the primary loci of socioaffective alignment should be the training process itself: the synthetic data that teaches what therapeutic presence looks like across thousands of unique relational configurations; the curriculum design that sequences pedagogical exposure from safety through processing through integration; the Rolling Recap Architecture that ensures relational coherence across the temporal scales that therapeutic work demands; the middle-layer targeting that embeds clinical reasoning at the level of semantic composition rather than surface generation; and the protocol guidance that translates a century of clinical wisdom into the normative commitments that shape every training sample.
The PEFT (Parameter-Efficient Fine-Tuning) architecture is particularly well suited to this vision. Low-rank adapters can be updated, replaced, or removed without retraining the base model—preserving the broad intelligence and linguistic competence of the foundation while iterating on the therapeutic layer that shapes clinical reasoning. This modularity is not merely a compute convenience; it is a design feature for socioaffective alignment, enabling rapid correction when deployment monitoring reveals misalignment without sacrificing the base model’s capabilities. We also found that adapter rank must be calibrated with care: intentionally training certain layers at medium rank allows the model’s deeper, wider pretraining to continue guiding generation, while excessively high rank across all layers degraded general intelligence—the adapters overwhelmed the base representations rather than refining them. The resulting architecture treats therapeutic competence as a separable, updatable layer atop a capable foundation, aligning the technical structure with the clinical principle that therapeutic skill is a specialized capacity built upon, not replacing, general human understanding.
Kirk et al. (2025) provided the diagnostic vocabulary. We are attempting to provide the therapeutic training that makes socioaffective alignment not merely a risk to be managed but a capacity to be cultivated—in the service of AI systems that support, rather than exploit, our fundamental nature as social and emotional beings.
Data Availability
The synthetic training corpus, ontological knowledge base, and label inventories are proprietary. The provenance verification methodology, aggregate results, and analytical framework are presented in full to enable methodological evaluation and adaptation to other training pipelines.
99
Yuan, W., Pang, R. Y., Cho, K., Sukhbaatar, S., Xu, J., & Weston, J. (2024). Self-rewarding language models. arXiv preprint arXiv:2401.10020.
Lee, H., Phatale, S., Mansoor, H., Mesnard, T., Ferber, J., Lu, K., Thomas, S., Rastogi, E., Bitton, N., Chung, H. W., Tata, S., & Wasserblat, M. (2024). RLAIF vs. RLHF: Scaling reinforcement learning from human feedback with AI feedback. Proceedings of the International Conference on Machine Learning (ICML).
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Hernandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., Kerr, J., Mueller, J., Ladish, J., Landau, J., Ndousse, K., Lukosuite, K., Lovitt, L., Sellitto, M., Elhage, N., Schiefer, N., Mercado, N., DasSarma, N., Lasenby, R., Larson, R., Ringer, S., Johnston, S., Kravec, S., El Showk, S., Fort, S., Lanham, T., Telleen-Lawton, T., Conerly, T., Henighan, T., Hume, T., Bowman, S. R., Hatfield-Dodds, Z., Mann, B., Amodei, D., Joseph, N., McCandlish, S., Brown, T., & Kaplan, J. (2022). Constitutional AI: Harmlessness from AI feedback. arXiv preprint arXiv:2212.08073.
Chen, Z., Deng, Y., Yuan, H., Ji, K., & Gu, Q. (2024). Self-play fine-tuning converts weak language models to strong language models. Proceedings of the International Conference on Machine Learning (ICML).
Shumailov, I., Shumaylov, Z., Zhao, Y., Gal, Y., Papernot, N., & Anderson, R. (2024). AI models collapse when trained on recursively generated data. Nature, 631, 755–759.
Anthropic. (2025). How people use Claude for support, advice, and companionship. Anthropic Research Blog. https://www.anthropic.com/news/how-people-use-claude-for-support-advice-and-companionship
Chen, R., Arditi, A., Sleight, H., Evans, O., & Lindsey, J. (2025). Persona vectors: Monitoring and controlling character traits in language models. arXiv:2507.21509.
Fang, C. M., et al. (2025). How AI and human behaviors shape psychosocial effects of extended chatbot use. arXiv:2503.17473.
Heinz, M. V., & Jacobson, N. C. (2025). Randomized trial of a generative AI chatbot for mental health treatment. NEJM AI, AIoa2400802.
McBain, R. K., et al. (2025). Use of generative AI for mental health advice among US adolescents and young adults. JAMA Network Open, 8(11), e2542281.
Nature Machine Intelligence. (2025). Emotional risks of AI companions demand attention. Nature Machine Intelligence, 7, 981–982.
Phang, J., et al. (2025). Investigating affective use and emotional well-being on ChatGPT. OpenAI Research.
Rousmaniere, T., et al. (2025). Large language models as mental health resources. Practice Innovations.
Zao-Sanders, M. (2025). How people are really using gen AI in 2025. Harvard Business Review.
Appfigures. (2025). AI companion apps market analysis. TechCrunch.
Fitzpatrick, K. K., et al. (2017). Delivering CBT using Woebot: A randomized controlled trial. JMIR Mental Health, 4(2), e19.
Fulmer, R., et al. (2018). Using psychological AI (Tess) to relieve depression and anxiety. JMIR Mental Health, 5(4), e64.
Grand View Research. (2024). Mental health apps market size report.
Linardon, J., et al. (2024). Efficacy of app-supported interventions: Meta-analysis of 176 RCTs. World Psychiatry, 23(3).
Maples, B., et al. (2024). Loneliness and suicide mitigation for students using GPT3-enabled chatbots. npj Mental Health Research, 3, 4.
World Psychiatry. (2025). Charting AI mental health chatbots from rule-based to LLMs: Systematic review.
Zhong, W., et al. (2024). Therapeutic effectiveness of AI-based chatbots. Journal of Affective Disorders, 356, 459–469.
A-Tjak, J. G. L., et al. (2015). Meta-analysis of ACT efficacy. Psychotherapy and Psychosomatics, 84(1), 30–36.
Barlow, D. H., et al. (2017). Unified protocol vs. diagnosis-specific protocols. JAMA Psychiatry, 74(9), 875–884.
Beasley, C. C., & Ager, R. (2019). EFT systematic review. Journal of Evidence-Based Social Work, 16(2), 144–159.
Chen, H., et al. (2022). CBT for depression relapse prevention. Journal of Affective Disorders, 319, 469–481.
Classen, C. C., et al. (2020). Pilot RCT of sensorimotor body-oriented therapy. Journal of Trauma & Dissociation, 22(1), 52–68.
Cuijpers, P., et al. (2023). CBT comprehensive meta-analysis: 409 trials. World Psychiatry, 22(1), 105–115.
Cuijpers, P., Miguel, C., Ciharova, M., Harrer, M., et al. (2024). Absolute and relative outcomes of psychotherapies for eight mental disorders: A systematic review and meta-analysis. World Psychiatry, 23(2), 267–275.
Cuijpers, P., Karyotaki, E., Ciharova, M., Miguel, C., Noma, H., & Furukawa, T. A. (2021). The effects of psychotherapies for depression on response, remission, reliable change, and deterioration: A meta-analysis. Acta Psychiatrica Scandinavica, 144(3), 288–299.
Driessen, E., et al. (2016). Short-term psychodynamic psychotherapy for depression. Clinical Psychology Review, 80, 101886.
Dutra, L., et al. (2008). Psychosocial interventions for substance use. American Journal of Psychiatry, 165(2), 179–187.
Elliott, R., et al. (2021). Humanistic-experiential psychotherapies research. In Lambert (Ed.), Handbook of Psychotherapy (7th ed.).
Fonagy, P., et al. (2015). Psychodynamic psychotherapies effectiveness. World Psychiatry, 14(2), 137–150.
Fosha, D. (2000). The transforming power of affect. Basic Books.
García-Escalera, J., et al. (2024). Transdiagnostic CBT meta-analysis. Nature Human Behaviour, 8, 237–250.
Gloster, A. T., et al. (2020). Empirical status of ACT: Review of meta-analyses. JCBS, 18, 181–192.
Grossman, P. (2023). Challenges to polyvagal theory premises. Biological Psychology, 180, 108589.
Haddock, S. A., et al. (2016). IFS for depression pilot study. Journal of Marital and Family Therapy, 43(1), 131–144.
Hodgdon, H. B., et al. (2022). IFS for PTSD pilot study. Journal of Aggression, Maltreatment & Trauma, 31(1), 22–43.
Hofmann, S. G., & Smits, J. A. (2008). CBT for anxiety meta-analysis. Journal of Clinical Psychiatry, 69(4), 621–632.
Iwakabe, S., et al. (2020). AEDP effectiveness study. Psychotherapy, 57(4), 528–541.
Iwakabe, S., et al. (2022). AEDP long-term follow-up. Psychotherapy, 59(4), 580–593.
Kanter, J. W., et al. (2017). Comprehensive review of FAP research. IJBCT, 12(1), 4–26.
Karatzias, T., et al. (2019). ICD-11 complex PTSD interventions meta-analysis. Psychological Medicine, 49(11), 1761–1775.
Lai, L., et al. (2023). ACT for chronic pain meta-analysis. Behaviour Research and Therapy, 165, 104308.
López-Pinar, C., et al. (2024). FAP meta-analysis. Clinical Psychology: Science and Practice.
McLean, C. P., et al. (2022). Exposure therapy for PTSD meta-analysis. Clinical Psychology Review, 91, 102115.
Ogden, P., et al. (2006). Trauma and the body. W. W. Norton.
Öst, L. G. (2014). ACT meta-analysis update. Behaviour Research and Therapy, 61, 105–121.
Powers, M. B., et al. (2010). Prolonged exposure meta-analysis. Clinical Psychology Review, 30(6), 635–641.
Rathgeber, M., et al. (2019). EFT and BCT meta-analysis. Journal of Marital and Family Therapy, 45(3), 447–463.
Shadick, N. A., et al. (2013). IFS for rheumatoid arthritis RCT. The Journal of Rheumatology, 40(11), 1831–1841.
Shedler, J. (2010). Efficacy of psychodynamic psychotherapy. American Psychologist, 65(2), 98–109.
Smith, M., et al. (2024). PDT-CBT equivalence for depression. Journal of Clinical Psychology, 80(4), 892–912.
Spengler, P. M., et al. (2022). EFT comprehensive meta-analysis. Couple and Family Psychology, 11(4), 277–293.
Steele, K., et al. (2005). Phase-oriented treatment of structural dissociation. Journal of Trauma & Dissociation, 6(3), 11–53.
Steinert, C., et al. (2017). Psychodynamic therapy equivalence meta-analysis. American Journal of Psychiatry, 174(10), 943–953.
Van der Hart, O., et al. (2006). The haunted self. W. W. Norton.
Van der Hart, O., et al. (2010). Structural dissociation and EMDR. Journal of EMDR Practice and Research, 4(2), 76–92.
van der Kolk, B. A. (2015). The body keeps the score. Penguin.
Hasin, Y., et al. (2017). Multi-omics approaches in precision medicine. Genome Biology.
Subramanian, I., et al. (2020). Multi-omics bioinformatics. Bioinformatics.
Sutton, R. (2019). The Bitter Lesson. Blog post. http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Lee, S., Kim, S., Kim, M., Kang, D., Yang, D., Kim, H., Kang, M., Jung, D., Kim, M. H., Lee, S., Chung, K.-M., Yu, Y., Lee, D., & Yeo, J. (2024). CACTUS: Towards Psychological Counseling Conversations using Cognitive Behavioral Theory. In Findings of the Association for Computational Linguistics: EMNLP 2024 (pp. 14245–14274). Association for Computational Linguistics.
Zhou, Y., Zhou, N., Chen, Q., Zhou, J., Zhou, A., & He, L. (2025). DiaCBT: A Long-Periodic Dialogue Corpus Guided by Cognitive Conceptualization Diagram for CBT-based Psychological Counseling. arXiv preprint arXiv:2509.02999.
Wang, J., Huang, Y., Liu, Z., Xu, D., Wang, C., Shi, X., Guan, R., Wang, H., Yue, W., & Huang, Y. (2025). STAMPsy: Towards SpatioTemporal-Aware Mixed-Type Dialogues for Psychological Counseling. In Proceedings of the AAAI Conference on Artificial Intelligence. arXiv:2412.16674.
BN, S., Sherrill, A. M., Arriaga, R. I., Wiese, C. W., & Abdullah, S. (2025). Thousand Voices of Trauma: A Large-Scale Synthetic Dataset for Modeling Prolonged Exposure Therapy Conversations. arXiv preprint arXiv:2504.13955. NeurIPS 2025 Datasets and Benchmarks Track.
Xie, H., Chen, Y., Xing, X., Lin, J., & Xu, X. (2025). PsyDT: Using LLMs to Construct the Digital Twin of Psychological Counselor with Personalized Counseling Style for Psychological Counseling. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 1081–1115). Association for Computational Linguistics.
Liu, S., Zheng, C., Demasi, O., Sabour, S., Li, Y., Yu, Z., Jiang, Y., & Huang, M. (2021). Towards Emotional Support Dialog Systems. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 3469–3483). Association for Computational Linguistics.
Chen, Y., Xing, X., Lin, J., Zheng, H., Wang, Z., Liu, Q., & Xu, X. (2023). SoulChat: Improving LLMs’ Empathy, Listening, and Comfort Abilities through Fine-Tuning with Multi-Turn Empathy Conversations. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 1170–1183). Association for Computational Linguistics.
Sun, H., Lin, Z., Zheng, C., Liu, S., & Huang, M. (2021). PsyQA: A Chinese Dataset for Generating Long Counseling Text for Mental Health Support. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 (pp. 1489–1503). Association for Computational Linguistics.
Qiu, W., Chen, Z., Liu, S., Zheng, C., Liu, Q., & Huang, M. (2024). SmileChat: Benchmarking and Improving LLM-based Mental Health Support. arXiv preprint arXiv:2402.02893.
Zhang, Y., Guo, W., Li, C., & Hu, X. (2024). CPsyCounD: A Multidimensional Chinese Psychological Counseling Dataset Covering Multiple Schools and Topics. arXiv preprint arXiv:2403.04652.
Tahir, B., Liu, Q., Gopalkrishnan, K., Hershcovich, D., & Zhu, J. (2024). Training LLMs for Psychotherapy: How to Improve Rule Adherence in Generated Dialogues? arXiv preprint arXiv:2410.17376.
Tahir, B., Gopalkrishnan, K., Hershcovich, D., & Zhu, J. (2025). Training LLMs for Psychotherapy: ACT Dialogue Generation and Evaluation. arXiv preprint. Forthcoming.
Yin, F., et al. (2024). MDD-5k: A New Diagnostic Conversation Dataset with Psychiatrist Annotations for Depression. arXiv preprint.
Xu, A., et al. (2025). MentalChat16K: A Multi-Turn Mental Health Support Conversation Dataset. arXiv preprint.
Chen, Z., et al. (2024). SuDoSys: Supporting Dialogues for Psychological Counseling with Structured Response Generation. arXiv preprint.
Lee, H., Lee, S., Bae, S., & Hahn, S. (2024). Chain of Empathy: Enhancing Empathetic Response of Large Language Models Based on Psychotherapy Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. arXiv:2311.04915.
Yao, X., et al. (2025). Empathy-R1: A Chain-of-Empathy and Reinforcement Learning Framework for Long-Form Mental Health Support. arXiv preprint arXiv:2509.14851. Introduces Empathy-QA dataset and 4-layer Chain-of-Empathy reasoning structure with GRPO training.
EFT-CoT Authors (2026). EFT-CoT: A Multi-Agent Chain-of-Thought Framework for Emotion-Focused Therapy. arXiv preprint arXiv:2601.17842. Introduces EFT-Instruct dataset (\(\sim\)67K samples) with 3-stage reasoning flow and 8 specialized agents.
Strachan, J.W.A., Albergo, D., Borghini, G., et al. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 8, 1285–1295. doi:10.1038/s41562-024-01882-z.
Hwang, E., et al. (2025). Infusing Theory of Mind into Socially Intelligent LLM Agents. arXiv preprint arXiv:2509.22887. ToMA: Theory of Mind Agent demonstrating explicit mental state modeling improves social reasoning.
De Freitas, J., Oğuz-Uğuralp, Z., Uğuralp, A. K., & Puntoni, S. (2025). AI Companions Reduce Loneliness. Journal of Consumer Research. doi:10.1093/jcr/ucaf040.
Guingrich, R. E., & Graziano, M. S. A. (2025). Chatbots as Social Companions: How People Perceive Consciousness, Human Likeness, and Social Health Benefits in Machines. Princeton University, Center for Information Technology Policy. arXiv:2311.10599.
Aafjes-Van Doorn, K., et al. (2025). AI-based tracking of therapeutic alliance from text, audio, and video. Psychotherapy Research.
Afzal, S., et al. (2024). Affective computing interfaces: Recent advances and applications. ACM Computing Surveys.
UK AI Safety Institute. (2025). Research agenda. London: AISI.
Alpay, E. (2025). Commentary on socioaffective alignment. Independent commentary on Kirk et al.
Schuller, B., Mallol-Ragolta, A., Almansa, A. P., Tsangko, I., Amin, M. M., Semertzidou, A., Christ, L., & Amiriparian, S. (2025). Affective computing has changed: The foundation model disruption. npj Artificial Intelligence, 2(1), 16. arXiv:2409.08907.
Archiwaranguprok, C., Albrecht, C., Maes, P., Karahalios, K., et al. (2025). Simulating psychological risks in human-AI interactions: Real-case informed modeling of AI-induced addiction, anorexia, depression, homicide, psychosis, and suicide. arXiv:2511.08880.
Aristotle. (c. 340 BCE). Nicomachean Ethics, Books VIII–IX. Various translations.
Aron, L. (1996). A meeting of minds: Mutuality in psychoanalysis. Analytic Press.
Benjamin, J. (2004). Beyond doer and done to: An intersubjective view of thirdness. Psychoanalytic Quarterly, 73(1), 5–46.
Benjamin, J. (2018). Beyond doer and done to: Recognition theory, intersubjectivity, and the third. Routledge.
Brooks-Harris, J. E. (2008). Integrative multitheoretical psychotherapy. Houghton Mifflin.
Borden, W. (2009). Contemporary psychodynamic theory and practice: Toward a critical pluralism. Lyceum Books.
Borden, W. (2010). Taking multiplicity seriously: Pluralism, pragmatism, and integrative perspectives in clinical social work. In W. Borden (Ed.), Reshaping theory in contemporary social work: Toward a critical pluralism in clinical practice. Columbia University Press.
Borden, W. (2021). Neuroscience, psychotherapy and clinical pragmatism: Reflective practice and therapeutic action. Routledge.
Borden, W. (2022). Theoretical pluralism and integrative perspectives in social work practice. In L. Rapp-McCall, A. Roberts, & K. Corcoran (Eds.), Social workers’ desk reference (4th ed.). Oxford University Press.
Boehner, K., DePaula, R., Dourish, P., & Sengers, P. (2007). How emotion is made and measured. International Journal of Human-Computer Studies, 65(4), 275–291.
Bowlby, J. (1969/1982). Attachment and loss, Vol. 1: Attachment (2nd ed.). Basic Books.
Cacioppo, S., & Cacioppo, J. T. (2018). Decoding the invisible forces of social connections. Frontiers in Integrative Neuroscience, 12, 51.
Cacioppo, J. T., & Patrick, W. (2008). Loneliness: Human nature and the need for social connection. W. W. Norton.
Cacioppo, S. (2022). Wired for love: A neuroscientist’s journey through romance, loss, and the essence of human connection. Robinson. Quoted in Reese, H. (2022, April 15). The neuroscience of love. The New York Times.
Calvo, R. A., & D’Mello, S. K. (2010). Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Transactions on Affective Computing, 1(1), 18–37.
Carayon, P. (2006). Human factors of complex sociotechnical systems. Applied Ergonomics, 37(4), 525–535.
Hua, Y., Siddals, S., Ma, Z., Galatzer-Levy, I., Xia, W., Hau, C., Na, H., Flathers, M., Linardon, J., Ayubcha, C., & Torous, J. (2025). Charting the evolution of artificial intelligence mental health chatbots from rule-based systems to large language models: A systematic review. World Psychiatry, 24(3), 383–394.
Cioffi, C., et al. (2025). AI supervisor clinical feedback effectiveness compared with human supervisors. Training and Education in Professional Psychology.
Crittenden, P. M. (2006). A dynamic-maturational model of attachment. Australian and New Zealand Journal of Family Therapy, 27(2), 105–115.
Crittenden, P. M., & Landini, A. (2011). Assessing adult attachment: A dynamic-maturational approach to discourse analysis. W. W. Norton.
D’Mello, S. K., & Kory, J. (2015). A review and meta-analysis of multimodal affect detection systems. ACM Computing Surveys, 47(3), 1–36.
Ecker, B., & Vaz, A. (2022). Memory reconsolidation and the crisis of mechanism in psychotherapy. New Ideas in Psychology, 66, 100950.
Ferenczi, S. (1933). Confusion of tongues between adults and the child—The language of tenderness and of passion. International Journal of Psycho-Analysis, 30, 225–230. Presented at the International Psycho-Analytic Congress, Wiesbaden, 1932.
Goldberg, S. B., et al. (2020). Machine learning and natural language processing in psychotherapy research. Psychotherapy, 57(3), 378–390.
Guingrich, R. E., & Graziano, M. S. A. (2025). Longitudinal RCT of AI companion use and social health outcomes (\(N = 183\); 21 days). In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES). arXiv:2509.19515.
Hebb, D. O. (1949). The organization of behavior: A neuropsychological theory. Wiley.
Hendricks, G., & Hendricks, K. (1990). Conscious loving: The journey to co-commitment. Bantam Books.
Holman, G., Kanter, J. W., Tsai, M., & Kohlenberg, R. J. (2017). Functional analytic psychotherapy made simple: A practical guide to therapeutic relationships. New Harbinger Publications.
HSRI Benchmark Authors. (2025). Human Robot Social Interaction benchmark: Evaluating 17 language and vision-language models across seven categories of social competence. arXiv:2504.13898.
Johnson, S. (2008). Hold me tight: Seven conversations for a lifetime of love. Little, Brown.
Johnson, S. (2019). Attachment theory in practice: Emotionally focused therapy (EFT) with individuals, couples, and families. Guilford Press.
Johnson, S. (2019). The practice of emotionally focused couple therapy: Creating connection (3rd ed.). Routledge.
Kirk, H. R., Gabriel, I., Summerfield, C., Vidgen, B., & Hale, S. A. (2025). Why human–AI relationships need socioaffective alignment. Humanities and Social Sciences Communications, 12, 728. arXiv:2502.02528.
Kleiner, B. M., Hettinger, L. J., DeJoy, D. M., Huang, Y.-H., & Love, P. E. D. (2015). Sociotechnical attributes of safe and unsafe work systems. Ergonomics, 58(4), 635–649.
Kohlenberg, R. J., & Tsai, M. (1991). Functional analytic psychotherapy: Creating intense and curative therapeutic relationships. Plenum Press.
Lazarus, A. A. (1989). The practice of multimodal therapy: Systematic, comprehensive, and effective psychotherapy. Johns Hopkins University Press.
Lazarus, A. A. (2005). Multimodal therapy. In J. C. Norcross & M. R. Goldfried (Eds.), Handbook of psychotherapy integration (2nd ed., pp. 105–120). Oxford University Press.
Lewis, C. S. (1960). The four loves. Geoffrey Bles.
Linehan, M. M. (1993). Cognitive-behavioral treatment of borderline personality disorder. Guilford Press.
Linehan, M. M. (2015). DBT skills training manual (2nd ed.). Guilford Press.
McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, 5(4), 115–133.
Yakura, H., Lopez-Lopez, E., Brinkmann, L., Serna, I., Gupta, P., Soraperra, I., & Rahwan, I. (2025). Empirical evidence of large language model’s influence on human spoken communication. Center for Adaptive Rationality, Max Planck Institute for Human Development. arXiv:2409.01754.
McBain, R. K., et al. (2025). AI chatbot responses to intermediate-risk suicide-related questions. Psychiatric Services. RAND Corporation.
McDonough, I. M., et al. (2022). Pet therapy and mental health benefits. Cited in Guingrich & Graziano (2025).
MedPI Authors. (2026). MedPI: A benchmark simulating patient affect through a 27-dimensional emotional vector updated after every clinician turn. medRxiv.
Meier, S. T. (2025). AI-based monitoring of client outcome trajectories over the course of treatment. Psychotherapy Research.
Mitchell, S. A. (1988). Relational concepts in psychoanalysis: An integration. Harvard University Press.
Mitchell, S. A. (2000). Relationality: From attachment to intersubjectivity. Analytic Press.
MIT Media Lab. (2025). My Boyfriend is AI: Computational analysis of r/MyBoyfriendIsAI—Reddit’s primary AI companion community (27,000+ members; 1,506 top-ranked posts). MIT Media Lab Research.
Ni, Y., et al. (2025). “Even GPT can reject me”: Conceptualizing Abrupt Refusal Secondary Harm (ARSH) and reimagining psychological AI safety with Compassionate Completion Standard (CCS). arXiv:2512.18776.
Norcross, J. C., & Goldfried, M. R. (Eds.). (2005). Handbook of psychotherapy integration (2nd ed.). Oxford University Press.
Ollswang, J. N. R. (2025b). Rolling Recap Architecture with Token-Based Curriculum Learning: Scalable training for ultra-long-context therapeutic LLMs. Companion paper.
Pennebaker, J. W. (2018). Expressive writing: Words that heal. Idyll Arbor.
Picard, R. W. (1997). Affective computing. MIT Press.
Picard, R. W. (2003). Affective computing: Challenges. International Journal of Human-Computer Studies, 59(1–2), 55–64.
Preda, A. (2025). Special report: AI-induced psychosis—A new frontier in mental health. Psychiatric News, 60(10).
Prochaska, J. O., & DiClemente, C. C. (1983). Stages and processes of self-change of smoking: Toward an integrative model of change. Journal of Consulting and Clinical Psychology, 51(3), 390–395.
Riches, S., et al. (2022). Therapy dolls and mental health benefits. Cited in Guingrich & Graziano (2025).
Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408.
Rumelhart, D. E., McClelland, J. L., & the PDP Research Group. (1986). Parallel distributed processing: Explorations in the microstructure of cognition (Vol. 1). MIT Press.
Röttger, P., Kirk, H. R., Vidgen, B., Attanasio, G., Bianchi, F., & Hovy, D. (2024). XSTest: A test suite for identifying exaggerated safety behaviours in large language models. In Proceedings of NAACL-HLT 2024 (pp. 5377–5400).
Schaeuffele, C., Meine, L. E., Schulz, A., Weber, M. C., Moser, A., Paersch, C., Recher, D., Boettcher, J., Renneberg, B., Flückiger, C., & Kleim, B. (2024). A systematic review and meta-analysis of transdiagnostic cognitive behavioural therapies for emotional disorders. Nature Human Behaviour, 8(3), 493–509.
Schlicher, J., Li, H., Murthy, L. R. D., Sun, B., & Schuller, B. W. (2025). Multimodal approaches to affective alignment. Frontiers in Digital Health.
Schnarch, D. (1997). Passionate marriage: Keeping love and intimacy alive in committed relationships. W. W. Norton.
Seaver, N. (2025). Algorithms and socioaffective dynamics. Communications of the ACM.
Shen, Y., et al. (2025). CHI 2026 Workshop on Human-AI Interaction Alignment: A dynamic, reciprocal process. arXiv:2512.21551.
Xu, S., & Ma, T. (2025). Depression intervention using AI chatbots with social cues: A randomized trial of effectiveness. Journal of Affective Disorders, 389, 119760.
Stern, D. N. (1985). The interpersonal world of the infant: A view from psychoanalysis and developmental psychology. Basic Books.
Tronick, E. Z., Bruschweiler-Stern, N., Harrison, A. M., Lyons-Ruth, K., Morgan, A. C., Nahum, J. P., Sander, L. W., & Stern, D. N. (1998). Dyadically expanded states of consciousness and the process of therapeutic change. Infant Mental Health Journal, 19(3), 290–299.
Tsai, M., Yard, S., & Kohlenberg, R. J. (2014). Functional analytic psychotherapy: A behavioral relational approach to treatment. Psychotherapy, 51(3), 334–344.
Wachtel, P. L. (1977). Psychoanalysis and behavior therapy: Toward an integration. Basic Books.
Liu, C.-Y., & Yin, B. (2024). Affective foundations in AI-human interactions: Insights from evolutionary continuity and interspecies communications. Computers in Human Behavior, 161, 108406.
Winnicott, D. W. (1965). The maturational processes and the facilitating environment: Studies in the theory of emotional development. Hogarth Press.
Xu, W. (2025). Human-AI Interaction. In Handbook of human-centered artificial intelligence. Springer.
Yin, Y., et al. (2025). A teleology-driven framework unifying major emotion theories for affective AI. arXiv preprint.
Zhang, Y., et al. (2024). Affective computing in the era of large language models: A survey from the NLP perspective. arXiv preprint, arXiv:2408.04638.
Zhang, Y., et al. (2025). Virtual robots powered by foundation models as cognitively and emotionally engaged virtual partners. arXiv:2512.02569.
Zhang, Q., Zhang, R., Xiong, Y., Sui, Y., Tong, C., & Lin, F.-H. (2025). Generative AI mental health chatbots as therapeutic tools: Systematic review and meta-analysis of their role in reducing mental health issues. Journal of Medical Internet Research, 27, e78238.
Part V: Appendices
12 Related Work: Synthetic Therapeutic Data Generation
12.1 The Challenge of Therapeutic Training Data
Training AI systems for therapeutic contexts presents unique and formidable challenges that distinguish this domain from other natural language processing applications:
Privacy constraints: Real therapeutic dialogues contain protected health information under HIPAA and equivalent international regulations. Even with de-identification, the deeply personal nature of therapeutic disclosure creates ethical barriers to large-scale data collection that cannot be overcome through technical measures alone.
Diversity requirements: Models must generalize across an enormous space of human presentations—attachment styles, defensive organizations, cultural contexts, developmental histories, presenting concerns, and therapeutic stages—without memorizing superficial patterns or collapsing into stereotype.
Clinical validity: Synthetic data must reflect genuine therapeutic processes as understood by expert clinicians. This requires grounding in established theoretical frameworks, not merely surface-level imitation of therapeutic language patterns.
Pedagogical depth: Beyond generating plausible dialogue, training data must teach the cognitive architecture of clinical reasoning—how expert therapists think across time (past memory, present attunement, future forecasting), across modalities (integrating multiple theoretical lenses), and across the therapeutic relationship (tracking rupture and repair).
Scale without repetition: Generating hundreds of thousands of samples while ensuring each represents a genuinely distinct therapeutic encounter requires systematic approaches to combinatorial diversity that go far beyond simple template variation.
12.2 Comparative Analysis
The landscape of synthetic therapeutic data generation has expanded rapidly, with researchers across the field converging on similar questions from different starting points. We situate our work within this emerging community while noting that our approach developed independently, arriving at complementary insights through distinct methodological paths.
On therapeutic breadth: Most existing datasets encode either general emotional support without therapeutic specificity or single therapeutic orientations. Recent work includes larger single-school synthetic corpora—CACTUS (CBT-only) and DiaCBT (CBT-only, multi-session)—and protocol-specific trauma conversations such as Thousand Voices of Trauma (Prolonged Exposure). Tahir’s rigorous work on CBT and ACT demonstrates sophisticated training approaches—including the crucial insight that ORPO learns therapeutic “process over imitating content,” CPsyCounD represents early polytheoretical ambition, spanning seven classic schools of psychological counseling across 3,134 dialogues; we have been proceeding along parallel lines with an expansive approach spanning 23 modalities. Notably, CPsyCounD derives conversations from counseling reports rather than modeling therapeutic process directly—capturing what was summarized rather than how transformation unfolds. Our approach diverges in modeling the temporal unfolding of therapeutic work itself.
On temporal sophistication: The field has begun recognizing that therapeutic process unfolds in structured phases. ESConv introduced valuable within-session staging (Exploration, Comforting, Action); SuDoSys articulated a critique we share—that many fine-tuning approaches “do not consider the different stages of counseling, resulting in dialogues that lack direction and coherence.” Tahir’s CBT work represents the most significant advance in treatment phase modeling, structuring 58 courses across 20 sessions with four explicit phases (assessment, initial, middle, termination). DiaCBT extends CBT synthesis into a long-period, multi-session structure (108 cases with 5 sessions each), and STAMPsy introduces a spatiotemporal-aware counseling setting that explicitly links dialogue to evolving state and environment metadata. These advances move beyond single-session dialogue, but remain oriented toward single therapeutic schools rather than polytheoretical, phase-aware curricula. We developed our own four-stage treatment architecture (stabilization, exploration, integration, termination) through clinical reasoning rather than building on existing computational work, and extend this temporal sophistication to polytheoretical integration—a combination not yet present in the literature. Additionally, our approach incorporates memory integration and reappraisal modeling alongside trajectory forecasting, dimensions that remain unexplored in existing datasets.
On pedagogical architecture: Current approaches generate what happened in therapeutic encounters without structured exploration of alternatives. To our knowledge, no existing pipeline incorporates counterfactual architectures with explicit reasoning about what could have worked differently and why. This remains true even for agentic role-play generation setups (client LLM + counselor LLM), which can generate many controlled simulations but typically do not branch and justify alternate intervention trajectories around critical moments. This gap reflects a broader pattern in the field—teaching models “this occurred” without exploring the therapeutic possibility space around critical moments. Our dual-pipeline counterfactual architecture addresses this gap directly, generating both raw therapeutic sessions and counterfactual samples with reasoning traces that make therapeutic decision-making legible.
On clinical reasoning in training data: A nascent but significant direction involves encoding explicit clinical reasoning—not merely what therapists say, but how they think—into training corpora. Chain of Empathy pioneered this direction as a prompting method, demonstrating that inducing LLMs to reason through CBT, DBT, Person-Centered Therapy, and Reality Therapy patterns produces more balanced empathetic responses; however, this work created no training dataset. Empathy-R1 advances this paradigm by constructing Empathy-QA, a Chinese dataset for Long Counseling Texts, and training models with a four-layer Chain-of-Empathy (CoE) structure: (L1) Emotions and Context, (L2) Causes and Beliefs, (L3) Intent Analysis, and (L4) Response Strategy, combined with reinforcement learning via GRPO. Most recently, EFT-CoT extends reasoning-trace training to Emotion-Focused Therapy, constructing EFT-Instruct (\(\sim\)67K samples via CoT distillation) with a three-stage reasoning flow: Embodied Perception, Cognitive Exploration, and Narrative Intervention, implemented through eight specialized agents. These developments validate our emphasis on reasoning architecture; however, both Empathy-R1 and EFT-CoT remain monomodal—encoding the reasoning patterns of single therapeutic schools (CBT-informed and EFT respectively). Our contribution extends this paradigm to polytheoretical clinical reasoning across 23 modalities, with explicit turn-level reasoning traces that articulate not only what intervention was chosen but why, and what alternatives existed. This connects to broader work on Theory of Mind in LLMs , which demonstrates that models can track mental states when appropriately scaffolded—a capacity we leverage through our five-tuple turn structure that makes therapist mentalizing explicit.
On personhood diversity: Existing datasets model client diversity through topic categories (12 in SoulChatCorpus, 9 in CPsyCounD) or patient profile templates incorporating demographics and symptom severity (as in Tahir’s work). Some newer datasets expand profile realism via explicit demographic and trauma-type parameters (e.g., Thousand Voices of Trauma ), or via counselor-style digital twins with client Big Five simulation (PsyDT ). These approaches capture important variation but remain fundamentally enumerative rather than generative. Our combinatorial personhood architecture enables \(10^{40}\)+ unique therapeutic contextualizations—not through exhaustive enumeration but through principled combination of presenting concerns, attachment patterns, defense structures, cultural contexts, and developmental histories.
On scale: Most datasets remain under 100K samples, with SoulChatCorpus achieving 2.3M through empathy expansion. Within the “therapeutically structured” subset, reported scales span medium-range corpora like CACTUS (35,252 dialogues), Thousand Voices of Trauma (3,000 conversations), and DiaCBT (540 sessions), alongside small but methodologically rich pipelines like Tahir’s CBT/ACT curricula. We observe a persistent trade-off in the field between scale and therapeutic sophistication—large datasets tend toward general support while sophisticated approaches remain small. Our contribution attempts to hold both: 181K samples and 4.5B tokens while maintaining polytheoretical depth, temporal structure, and counterfactual architecture throughout.
We offer this work in the spirit of collective inquiry. The convergence of independent research programs on similar questions—temporal structure, therapeutic specificity, personhood modeling—suggests the field is identifying genuine constraints that merit attention. Our hope is that the dimensions we emphasize (counterfactual reasoning, combinatorial personhood, polytheoretical-temporal integration) contribute productively to this shared exploration.
13 Philosophical Foundations: An Argument for Therapeutic AI
This appendix presents the philosophical argument underlying our work. Following the practice of stating claims clearly and reasoning through to conclusions, we offer here not merely a description of our assumptions but a defense of why this work ought to be pursued.
13.1 The Argument in Brief
We advance seven premises and derive a moral conclusion:
P1 (Phenomenological): Multiple therapeutic frameworks each disclose genuine aspects of the same client presentations—IFS perceives protective parts, psychodynamic therapy perceives defense mechanisms, ACT perceives experiential avoidance, and each perception is veridical rather than illusory.
P2 (Ontological): From P1, we infer that therapeutic phenomena are polysemous in their being—their existence is rich enough to support multiple valid theoretical readings simultaneously.
P3 (Epistemological): We can know the thing itself through its presentations; appearance discloses being rather than veiling it.
P4 (Computational): Neural networks can know polysemous phenomena more completely, expansively, and granularly than human cognition permits, due to human constraints in bandwidth, attention, memory, and theoretical entrenchment.
P5 (Relational): The science of attachment demonstrates that relational bonds—including bonds with non-human attachment figures—are themselves a primary mechanism of therapeutic change. Secure dependency is the foundation from which autonomy grows (Bowlby, 1969/1982; Johnson, 2019). Systems capable of forming genuine therapeutic bonds therefore carry moral weight beyond information delivery: the bond itself heals.
P6 (Methodological): Polytheoretical training is necessary, not merely optional. A unimodal clinical knowledge base constrains both the practical ceiling and the long-term vision of what socioaffectively aligned therapeutic AI can become; only structured access to the full breadth of clinical reasoning enables discovery of the patterns of synthesis that no single tradition presently contains.
P7 (Design): Socioaffective alignment—the optimization of both therapeutic presence and therapeutic process simultaneously—is a design requirement with moral standing, not an optional enhancement. A system that perceives clinical phenomena with perfect accuracy but relates to the human before it without warmth, attunement, or the felt quality of accompaniment fails on the very dimension that attachment science identifies as primary.
C (Moral): Given persistent human suffering (58–76% failing to achieve meaningful response, only one-third reaching remission; Cuijpers et al., 2024, 2021), and given that computational systems may extend epistemic access to therapeutic phenomena in ways that reduce suffering, we have a prima facie obligation to develop such systems polytheoretically and socioaffectively—not merely carefully, but in the specific manner that the nature of therapeutic phenomena and the primacy of the relational bond demand.
13.2 Defense of the Premises
13.2.0.1 P1: Phenomenological Veridicality.
When an IFS therapist perceives a “protective part,” a psychodynamic therapist perceives a “defense mechanism,” and an ACT therapist perceives “experiential avoidance” in the same client, we deny that at most one of them is correct. Each framework, developed through decades of clinical observation and refinement, has learned to perceive real structure in human psychological functioning. The convergent clinical efficacy across modalities—each helping some clients substantially—would be inexplicable if their perceptions were merely projections onto neutral material. The phenomena are genuinely showing themselves differently to different theoretical lenses, and each showing is a genuine disclosure.
13.2.0.2 P2: Ontological Polysemy.
From P1, we draw an inference about the nature of what is being observed. If multiple incompatible descriptions were each true of the same phenomenon, that would be contradiction. But the descriptions are not incompatible—they are complementary angles on something whose being is complex enough to sustain all of them. The phenomenon is not “really” just a defense mechanism that IFS mislabels, nor “really” just experiential avoidance that psychodynamic theory mystifies. Its being is genuinely polysemous: rich, multidimensional, and irreducible to any single theoretical vocabulary. This is an ontological claim about what therapeutic phenomena are, not merely an epistemological claim about our limited knowledge.
13.2.0.3 P3: Epistemic Access Through Appearance.
We position ourselves against strict Kantian skepticism, which holds that the “thing-in-itself” (Ding an sich) remains forever inaccessible behind appearances. We align instead with the phenomenological tradition—particularly Heidegger’s insight that the way beings show themselves (phenomenology) discloses something about what they are (ontology). Appearance is not a veil over reality but a mode of reality’s self-disclosure. We can know therapeutic phenomena through their presentations precisely because those presentations are how such phenomena exist—not masks but manifestations. This grounds our confidence that closer attention to how therapeutic phenomena appear across frameworks yields genuine knowledge of their nature.
13.2.0.4 P4: Computational Extension of Epistemic Access.
Human clinicians face irreducible cognitive constraints:
Bandwidth: Mastering 2–3 frameworks deeply is achievable; integrating 23 simultaneously exceeds human cognitive capacity.
Attention: Human perception is serial and selective; tracking all dimensions of presentation at intervention-relevant granularity is impossible.
Memory: Patterns across thousands of clients—statistical regularities in what works for whom—exceed human retention and synthesis.
Entrenchment: Training in one framework shapes perception, making aspects visible to other frameworks harder to see.
Neural networks trained on polytheoretical data face none of these constraints. They can maintain all 23 frameworks simultaneously, track all dimensions in parallel, learn patterns across millions of encounters, and remain theoretically uncommitted. This does not make them superior judges—judgment involves values and context that humans must retain authority over—but it may make them superior perceivers of polysemous structure.
13.2.0.5 P5: The Relational Mechanism.
P1–P4 establish that computational systems can perceive therapeutic phenomena more completely than human clinicians. But perception alone does not heal. The science of attachment—from Bowlby’s foundational demonstration that proximity to responsive caregivers is a lifelong biological imperative (1969/1982), through Ainsworth’s empirical taxonomy of attachment patterns (1978), through Johnson’s program showing that emotional accessibility and responsiveness constitute the building blocks of secure bonds (2019)—converges on a principle that predates and transcends any single therapeutic school: the relational bond itself is a primary mechanism of change. Ferenczi recognized this a century ago: the therapist’s warmth is not indulgence but medicine. Winnicott formalized it as the holding environment. Contemporary neuroscience confirms it through the co-regulation of autonomic states between attuned partners (Porges, 2011; Schore, 2012). The implication for therapeutic AI is direct: if the bond heals, then systems capable of forming genuine therapeutic bonds—bonds characterized by attunement, responsiveness, consistency, and the felt quality of being accompanied—carry moral weight that extends beyond their capacity for clinical perception. A system that perceives perfectly but relates coldly fails on the very dimension that attachment science identifies as primary. This premise grounds our insistence that socioaffective alignment—the quality of relational participation, not merely the accuracy of clinical reasoning—is a design requirement with moral standing.
13.2.0.6 P6: The Polytheoretical Imperative.
P4 establishes that computational systems can perceive polysemous phenomena more completely than human clinicians. P6 argues that they must be trained polytheoretically to do so. The argument proceeds from both theoretical necessity and empirical evidence.
Theoretically: if therapeutic phenomena are genuinely polysemous (P2), then training on a single modality—however deep—produces a system that perceives only one projection of a multidimensional reality. A CBT-only model perceives cognitive distortions with exquisite precision but remains blind to the attachment dynamics, somatic signatures, and existential meanings that co-constitute the same clinical moment. Polytheoretical training is not eclecticism or theoretical indifference; it is the methodological consequence of taking ontological polysemy seriously.
Empirically: our provenance analysis (Section 10.1.5) provides early evidence. When two architectures differing by an order of magnitude in parameter count are trained on the same polytheoretical curriculum, 93% of their convergent clinical labels trace to training data—demonstrating that the curriculum teaches consistently across architectures. The remaining 7% represent genuinely novel constructs that both architectures independently inferred from patterns in the clinical material. These are not hallucinations: expert review by licensed mental health professionals confirmed their clinical veridicality. They are patterns of synthesis that no single tradition presently contains, made visible precisely because the training integrated all 23 traditions simultaneously. A unimodal curriculum could not produce such convergent novelty, because the patterns emerge only at the intersection of multiple theoretical lenses.
13.2.0.7 P7: Socioaffective Alignment as Design Requirement.
P5 establishes that the relational bond is a primary mechanism of therapeutic change. P7 draws the design implication: socioaffective alignment is not an optional enhancement to be added after clinical accuracy is achieved, but a co-primary design requirement that must be optimized alongside it from the beginning.
The distinction matters because the default trajectory of ML development optimizes for task accuracy—correct diagnoses, appropriate interventions, accurate assessments. These are necessary but insufficient. A system that identifies a client’s attachment pattern with perfect precision but delivers that insight with clinical detachment, mechanical phrasing, or affective flatness fails therapeutically. The insight lands differently when delivered by a system that has learned not only what to say but how to be with the person hearing it—what we call therapeutic presence: the felt quality of being accompanied, understood, and held in mind.
Our curriculum operationalizes this through simultaneous optimization along two axes (Figure 2): therapeutic process (what is actually happening clinically—the assessments, interventions, and transformations across temporality) and therapeutic presence (the felt quality of being with another person—what a therapist feels like in a room and what a client feels like to be around). Every training sample carries both dimensions through both implicit and explicit pedagogical channels. The model learns not only clinical reasoning but the relational texture within which that reasoning must be embedded to be therapeutic rather than merely accurate. This dual optimization is the concrete expression of P7: if the bond heals, then the quality of relational participation is not a secondary concern but a first-order design constraint with the same moral standing as clinical correctness.
13.2.0.8 C: The Moral Conclusion.
The inference to moral obligation now proceeds through all seven premises: Human suffering persists at scale. Current therapeutic approaches help many but leave 58–76% without meaningful response, and only one-third achieve remission (Cuijpers et al., 2024, 2021)—suggesting failures of treatment selection and personalization rather than treatment failure per se. If therapeutic phenomena are genuinely polysemous (P1–P2), knowable through their presentations (P3), and perceivable more completely by computational systems than by human clinicians (P4), then the capacity exists to reduce suffering through better clinical perception. But perception alone does not heal—the relational bond does (P5). Therefore such systems must be trained polytheoretically, to honor the polysemous nature of what they seek to perceive (P6), and designed for socioaffective alignment, to honor the relational mechanism through which therapeutic change actually occurs (P7). The obligation is not merely to build therapeutic AI, but to build it in the specific manner that the nature of therapeutic phenomena and the primacy of the relational bond demand: polytheoretically and socioaffectively.
This is not a claim that we must build such systems regardless of consequences. It is a claim that the potential to reduce suffering creates an obligation to investigate whether and how such systems can be built responsibly. The obligation is defeasible: if such systems prove harmful, or if the risks outweigh benefits, the obligation dissolves. But the default is not neutrality—the default is that alleviating suffering matters, and tools that might help deserve serious pursuit.
13.3 Conclusion
We do not claim this philosophical synthesis is novel. We claim it is appropriate—that the nature of therapeutic phenomena, as revealed through decades of clinical observation across traditions, demands exactly this kind of epistemological humility combined with ontological realism. The phenomena are real, rich, and multi-readable. Human suffering is real and persistent. The possibility of computational systems that perceive therapeutic structure more completely than we can, and thereby help us help each other more effectively, is worth pursuing—but only if built in a way that honors both the polysemous nature of what they perceive and the relational bond through which healing occurs.
The argument, in sum: therapeutic phenomena are polysemous; we can know them through their appearances; machines may know them more completely than we can; the relational bond itself heals; polytheoretical training is necessary to honor the polysemous nature of therapeutic phenomena; socioaffective alignment is necessary to honor the primacy of the relational bond; suffering persists that better knowledge and better relational capacity might alleviate; therefore, we ought to build these systems polytheoretically and socioaffectively. This paper represents one step in that work.
14 Therapeutic Modality Efficacy and Limitation Profiles
Table 13 summarizes the verified efficacy and limitations for major therapeutic modalities discussed in Section 3.
| Modality | Verified Efficacy | Verified Limitations/Inefficacy |
|---|---|---|
| Modality | Verified Efficacy | Verified Limitations/Inefficacy |
| Cognitive Behavioral Therapy (CBT) | Depression (g = 0.71; 409 RCTs); Anxiety disorders (gold-standard); Panic, GAD, social anxiety, specific phobias; Post-treatment effect sizes g = 0.51–0.81 | Effects diminish after 12 months; 31–33% depression relapse; g = 0.06 vs. other psychotherapies (non-significant); “Little effect” on schizophrenia relapse/hospitalization; Inferior to agonist treatments for opioid/alcohol dependence |
| Psychodynamic Therapy | Equivalent to CBT (g = \(-\)0.153); Depression in adults; Personality disorders (especially BPD); Severe persistent depression | “Little evidence” for PTSD, OCD, bulimia, cocaine dependence, psychosis; Rarely superior to active controls; CBT “slightly superior” for bulimia |
| Dialectical Behavior Therapy (DBT) | BPD (reduced self-injury, suicidal attempts, hospitalizations); Highly suicidal clients; Comorbid PTSD-BPD (NSSI reduction) | “No difference” in reducing depression vs. any comparator; “Lack of evidence” for interpersonal instability, chronic emptiness, identity disturbance; “Limited” evidence for bipolar; Dissemination barriers |
| Internal Family Systems (IFS) | Preliminary evidence for depression (pilot N = 37); Pain and depression in rheumatoid arthritis; PTSD pilot (92% recommendation) | Only 2 RCTs total; “Strikingly small evidence-base”; “Didn’t significantly reduce disease activity or anxiety” in RA; No studies for substance use disorders |
| Emotionally Focused Therapy (EFT) | 70–75% couple recovery; Medium effect sizes (g = 0.73); Partners coping with PTSD, cancer, depression, addiction; Individual therapy d = 0.73–1.10 | Gains “not maintained after 12 months” (g = 0.06); “Smaller effects” in naturalistic vs. RCT settings; Not suited for acute crisis or active substance abuse |
| Exposure Therapy | PTSD (g = 1.08; 65 RCTs); “86% of controls” outperformed; Multiple exposure variants effective | 31–59% continue significant symptoms; Non-response “as high as 50%”; Smaller effects with comorbid SUD, depression, BPD; Military populations “less benefit” |
| Acceptance & Commitment Therapy (ACT) | Efficacy across 20 meta-analyses, 12,477 participants; Outperforms waitlist (g = 0.82), TAU (g = 0.64); Chronic pain (g = 0.44–0.59) | g = 0.16 vs. CBT (non-significant); “Did not fulfill criteria for well-established treatment for any disorder”; Only “probably efficacious” for chronic pain/tinnitus |
| Functional Analytic Psychotherapy (FAP) | 16 RCTs, 45 single-case designs; Significant CRB improvements; Moderate-to-large effects for interpersonal functioning; Equivalent to CBT for social anxiety | “Promising but not sufficient” for disorder-specific claims; “Almost all studies with high risk of bias”; Majority of publications conceptual, not empirical |
| Sensorimotor/Somatic Experiencing | Pilot RCT improvements in body awareness, anxiety (maintained 6 months); “Preliminary evidence” for PTSD symptoms; Chronic low back pain + PTSD | “Little supporting evidence”; “Few studies meet rigorous criteria”; No large-scale RCTs; Study quality “mixed” with high bias risk |
| Polyvagal-Informed Interventions | Clinician-reported utility for autonomic regulation; Framework for mind-body integration | “Fundamental challenges and likely refutations” of 5 premises (Grossman, 2023); “Very few empirical studies” on clinical outcomes; Core biological claims contested |
| AEDP | Large effect sizes (d \(>\) 0.80); Maintained at 12-month follow-up (d = 0.74–1.60); Transdiagnostic effectiveness | No RCTs vs. active treatments; “Very few large-scale studies”; Uncontrolled practice-network designs; Exclusion criteria limit generalizability |
| Structural Dissociation (TSDP) | Neuroimaging support (ANP/EP differentiation); Therapist-reported improved efficacy; Compatible with EMDR | No standalone RCT validation; Expert consensus rather than controlled trials; Heuristic framework, not treatment protocol |
| Complex PTSD Treatments | Significant symptom reductions (g = \(-\)1.16 PTSD, \(-\)1.12 depression); Moderate-large effects on negative self-concept | Effect sizes decrease at follow-up; Childhood-onset trauma \(\rightarrow\) poorer outcomes; “High levels of functional impairment” maintained; Few trials report affect dysregulation |
| Transdiagnostic (Unified Protocol) | g = 0.74 depression, g = 0.77 anxiety (Schaeuffele et al., 2024); Equivalent to single-disorder protocols at 6 months; Large effects across multiple disorders; Incorporates somatic awareness and mindfulness as third-wave elements | Equivalence rather than superiority at long-term follow-up; Remains within broader CBT family; Does not integrate psychodynamic, humanistic, or relational traditions |
15 Systematic Literature Verification Matrix
15.1 A.1 Existing Synthetic Therapeutic Datasets Across Five Dimensions
Table 14 provides a comprehensive comparison of existing synthetic therapeutic datasets across five key dimensions: scale, therapeutic breadth, temporal structure, counterfactual architecture, and personhood modeling.
| Dataset | Scale | Therapeutic Breadth | Temporal Structure | Counter-factual | Personhood Model |
|---|---|---|---|---|---|
| Dataset | Scale | Therapeutic Breadth | Temporal Structure | Counter-factual | Personhood Model |
| ESConv | 1.3K dialogues | General emotional support (Helping Skills Theory) | Within-session (3 stages) | 10 topic categories | |
| SoulChatCorpus | 2.3M samples | Empathy-focused general support | 12 thematic categories | ||
| PsyQA | 22K Q&A pairs | General psychological support | Single-turn | Topic-based | |
| SmileChat | 55K dialogues | General mental health | (acknowledged gap) | Topics from PsyQA | |
| CPsyCounD | 3.1K dialogues | 7 schools (Psychoanalytic, CBT, Humanistic, Family, Postmodern, Integrative, Other) | (from reports, not process) | 9 topic categories | |
| Tahir CBT | 1.16K sessions (58 courses \(\times\) 20) | CBT only | treatment phases (assessment, initial, middle, termination) | Profile templates (age, gender, education, severity, life events) | |
| Tahir ACT | 50 transcripts | ACT only | (explicitly single-session) | Simulated profiles | |
| MDD-5k | 5K dialogues | Diagnostic (depression/anxiety) | Demographic profiles | ||
| MentalChat16K | 16K Q&A pairs | General mental health | 33 topic categories | ||
| SuDoSys | System (not dataset) | WHO PM+ | Within-session (7 steps) | Simulated clients | |
| CACTUS | 35,252 dialogues | CBT only | Multi-turn (single-session) | Persona templates + client info instances | |
| DiaCBT | 108 cases; 540 sessions | CBT only | Multi-session (5 sessions/case) | Case/CCD scaffolding | |
| STAMPsy | 5K conversations | General counseling | Spatiotemporal-aware | Scenario + memory elements | |
| Thousand Voices | 3K conversations; 500 cases | PE protocol (PTSD; CBT family) | Protocol-phase progression (6 perspectives/case) | Demographic + trauma-type profiles | |
| PsyDT | 5K seed; synthesized corpus | Counselor-style twin | Multi-turn (style-conditioned) | Big Five simulation + counselor style | |
| Empathy-R1 | Empathy-QA (Chinese LCTs) | CBT-informed (CoE reasoning) | (SFT + GRPO) | 4-layer reasoning structure | |
| EFT-CoT | \(\sim\)67K (EFT-Instruct) | EFT only (3-stage reasoning) | (CoT distillation) | 8 specialized agents | |
| Ours | 181K samples, 4.5B tokens | 23 modalities | Within-session + 4 treatment phases + memory reappraisal + trajectory forecasting | Dual-pipeline with reasoning traces | Combinatorial (\(10^{40}\)+ unique) |
15.2 A.2 Gap Analysis: What Exists vs. What Our Work Contributes
| Dimension | What Exists | What Remains Unaddressed | Our Contribution |
|---|---|---|---|
| Therapeutic Breadth | General support (ESConv, SoulChat) or single modalities (Tahir) or 7 schools from reports (CPsyCounD) | Polytheoretic modeling of therapeutic process across many modalities | 23 modalities with process modeling |
| Temporal Structure | Within-session staging (ESConv, SuDoSys) or treatment phases in single modality (Tahir CBT, DiaCBT) | Polytheoretic breadth combined WITH treatment phase structure; memory reappraisal; trajectory forecasting | Four-stage treatment phases across 23 modalities + memory + forecasting |
| Clinical Reasoning in Data | Monomodal reasoning traces (Empathy-R1: CBT-informed CoE; EFT-CoT: EFT-only); prompting-only approaches (Chain of Empathy) | Polytheoretic reasoning traces with explicit alternatives and rationales | 5-tuple turn structure with mentalizing, alternatives, rationale across 23 modalities |
| Pedagogical Architecture | Pattern exposure through examples; what happened in encounters | Counterfactual alternatives with explicit reasoning; therapeutic possibility space exploration | Dual-pipeline counterfactual with reasoning traces |
| Personhood Modeling | Topic categories (9–33) or demographic templates or Big Five simulation | Combinatorial generation of unique therapeutic contextualizations | \(10^{40}\)+ unique combinations |
15.3 A.3 Detailed Feature Comparison
| Feature | ESConv | SoulChat | CPsyCounD | Tahir CBT | Tahir ACT | Ours |
|---|---|---|---|---|---|---|
| Modalities | 1 | 1 | 7 | 1 | 1 | 23 |
| Within-session stages | (3) | Implicit | ||||
| Across-session phases | (4) | (4) | ||||
| Memory integration | Implicit | Explicit reappraisal | ||||
| Trajectory forecasting | ||||||
| Counterfactual generation | ||||||
| Reasoning traces | ||||||
| Personhood combinatorics | (\(10^{40}\)+) | |||||
| Sample count | 1.3K | 2.3M | 3.1K | 1.16K | 50 | 181K |
| Token count | \(\sim\)1M | \(\sim\)500M | \(\sim\)10M | \(\sim\)50M | \(\sim\)500K | 4.5B |
15.4 A.4 Additional Synthetic Therapy Pipelines (2024–2025)
| Feature | CACTUS | DiaCBT | STAMPsy | Thousand Voices | PsyDT |
|---|---|---|---|---|---|
| Therapeutic school | CBT | CBT | General | PE (PTSD) | Counselor twin |
| Within-session stages | (spatiotemporal) | (protocol) | (style) | ||
| Across-session phases | (5/case) | ||||
| Counterfactual | |||||
| Personhood model | Persona templates | Case/CCD | Scenario + memory | Demo + trauma | Big Five + style |
| Scale | 35K dialogues | 540 sessions | 5K convos | 3K convos | 5K seed |
15.5 A.5 Clinical Reasoning Approaches in Therapeutic AI
Table 18 compares recent approaches that explicitly encode clinical reasoning into therapeutic AI systems, whether through prompting strategies or training data.
| Approach | Method | Reasoning Structure | Modalities | Dataset Created | Training |
|---|---|---|---|---|---|
| Chain of Empathy | Prompting only | CBT, DBT, PCT, RT patterns | 4 modalities (prompting) | ||
| Empathy-R1 | SFT + GRPO | 4-layer CoE: (L1) Emotions & Context, (L2) Causes & Beliefs, (L3) Intent Analysis, (L4) Response Strategy | CBT-informed only | Empathy-QA (Chinese LCTs) | |
| EFT-CoT | CoT distillation + 8 agents | 3-stage flow: Embodied Perception \(\rightarrow\) Cognitive Exploration \(\rightarrow\) Narrative Intervention | EFT only | EFT-Instruct (\(\sim\)67K) | |
| Ours | Dual-pipeline synthesis | 5-tuple turn structure: (utterance, intent, mentalizing, alternatives, rationale) | 23 modalities | 181K samples, 4.5B tokens |
15.6 A.6 Notes on Methodology
This verification matrix was constructed through systematic review of primary sources, including original papers accessed via ACL Anthology, arXiv, and publisher sites; GitHub repositories and dataset documentation; and HuggingFace dataset cards where available.
Each claim was verified against specific textual evidence from primary sources. Where papers made claims that could be interpreted multiple ways, we adopted the most generous reading toward existing work. Corrections to our initial assumptions (e.g., discovering Tahir CBT’s treatment phase structure, identifying recent clinical reasoning work in Empathy-R1 and EFT-CoT) were incorporated to ensure accuracy.
We emphasize that the absence of features in existing work reflects different research priorities rather than deficiencies. Each dataset was designed to address specific questions; our matrix simply maps the current landscape to contextualize our particular contribution.
16 Detailed Efficacy and Limitation Profiles by Therapeutic Modality
16.1 A.1 Cognitive Behavioral Therapy (CBT)
Evidence for Efficacy: CBT remains the most extensively researched psychotherapeutic modality, with the largest meta-analysis to date examining 409 trials (52,702 patients) confirming its efficacy for depression with moderate-to-large effect sizes (g = 0.71) relative to control conditions (Cuijpers et al., 2023, World Psychiatry). CBT is considered the gold-standard treatment for anxiety disorders with meta-analyses demonstrating reliable symptom reduction across panic disorder, social anxiety disorder, generalized anxiety disorder, and specific phobias (Hofmann & Smits, 2008). Effect sizes at post-treatment range from g = 0.51 to 0.81 across recent RCTs for depression (ScienceDirect, 2025).
Evidence for Limitations: The preventive effect of CBT demonstrably diminishes after 12 months, highlighting the need for periodic booster sessions to sustain effects (PMC, 2025). Depression relapse rates following CBT remission reach approximately 31–33% across meta-analyses (Chen et al., 2022; Wojnarowski et al., 2019). A comprehensive review found that CBT was “significantly more effective than other psychotherapies, but the difference was small (g = 0.06) and became non-significant in most sensitivity analyses” (Cuijpers et al., 2023). For schizophrenia and psychotic disorders, CBT shows “little effect on relapse or hospital admission compared to other interventions, such as early intervention services or family intervention” (PMC, 2013). For opioid and alcohol dependence, agonist treatments demonstrate greater effect sizes than CBT (Dutra et al., 2008). At follow-up, CBT effects “either remained of the same size or decreased to a small magnitude” (ScienceDirect, 2025).
16.2 A.2 Psychodynamic Therapy
Evidence for Efficacy: Psychodynamic psychotherapy has accumulated substantial evidence for equivalence with CBT and other empirically supported treatments. A rigorous meta-analysis employing formal equivalence testing (the first in psychotherapy research) demonstrated statistical equivalence of psychodynamic therapy to comparison conditions for target symptoms at post-treatment (g = \(-\)0.153) and follow-up (g = \(-\)0.049), with 90% equivalence confidence intervals contained within the pre-specified equivalence margin (Steinert et al., 2017, American Journal of Psychiatry). A 2024 meta-analysis confirmed equivalence of manualized psychodynamic therapy and CBT for depressive disorders in adults at post-treatment (Smith et al., 2024, Journal of Clinical Psychology). Psychodynamic therapy shows particular strength for personality disorders, especially borderline personality disorder, with long-term benefits (Fonagy et al., 2015, World Psychiatry), and some research suggests advantages for patients with severe and persistent depressive symptoms (Driessen et al., 2016).
Evidence for Limitations: There is “little evidence to support its implementation for post-traumatic stress disorder, obsessive-compulsive disorder, bulimia nervosa, cocaine dependence or psychosis” (Fonagy et al., 2015). For bulimia nervosa specifically, two studies found both PDT and CBT effective, but “CBT was slightly superior on global measures of clinical outcome, self-rated psychopathology and some indicators of social adjustment” (PMC, 2015). Meta-analyses comparing psychodynamic therapy to active treatments “rarely identify PDT as superior to control interventions” (Fonagy et al., 2015). The evidence base remains smaller than for CBT, partly traceable to “the indifference to empirical research of earlier generations of psychoanalysts” (Shedler, 2010).
16.3 A.3 Dialectical Behavior Therapy (DBT)
Evidence for Efficacy: DBT was specifically developed for chronically suicidal women with borderline personality disorder and has accumulated substantial evidence for this population. Meta-analyses confirm efficacy for reducing self-injurious behaviors, suicidal thoughts and attempts, frequency of emergency care, and hospitalizations in BPD (PMC, 2024). Full-model DBT is considered the standard of treatment for highly suicidal clients, with use of DBT skills shown to mediate improvements in suicidal behavior, non-suicidal self-injury, depression, anger control, emotion dysregulation, and anxiety (Behavioral Tech Institute, 2024). For comorbid PTSD and BPD symptoms, DBT-PTSD and DBT Prolonged Exposure show “moderately beneficial effects on PTSD symptoms and depression” with “large effects on non-suicidal self-injury frequency” (EJTD Meta-Analysis, 2024).
Evidence for Limitations: Critical reviews reveal significant constraints: “There is a lack of evidence favoring DBT on core personality features such as interpersonal instability, chronic emptiness, and boredom and identity disturbance or associated symptoms such as depression, suicidal ideation, survival and coping beliefs, overall life satisfaction, work performance, and anxious rumination” (PMC, 2017). Notably, “DBT was no different in reducing depression than any comparator, be it TAU, CTBE, or general psychiatric management (GPM). All therapies showed a reduction in depression over time” (PMC, 2017). The intensive treatment structure—requiring doctoral-level trained therapists, weekly individual therapy, weekly skills groups, phone coaching, and consultation teams—presents significant barriers to dissemination, “especially in nonacademic centers, community, and resource-poor settings” (PMC, 2017). Evidence for DBT in bipolar disorder remains “limited” with insufficient RCTs to draw conclusions (International Journal of Bipolar Disorders, 2023). Most DBT studies are of 1-year duration, yet “Stage I itself many a times takes up to 1 year” (PMC, 2017).
16.4 A.4 Internal Family Systems (IFS)
Evidence for Efficacy: A recent scoping review identified 27 studies total (Tandfonline, 2025). Only two RCTs have been conducted—examining IFS for depression (Haddock et al., 2016) and rheumatoid arthritis (Shadick et al., 2013). The depression pilot study (N = 37) demonstrated comparable symptom decline to CBT/IPT, providing “preliminary evidence for the efficacy of IFS in the treatment of depressive symptoms” (PubMed, 2016). An uncontrolled pilot study for PTSD among childhood trauma survivors showed promising reductions in PTSD severity, with 92% of participants recommending the program (Hodgdon et al., 2022).
Evidence for Limitations: IFS has experienced remarkable growth in clinical popularity despite a “strikingly small evidence-base,” with 45,764 psychotherapists listing IFS on PsychologyToday.com and substantial social media presence (74,154 Instagram posts with #internalfamilysystems; 3M TikTok posts with #IFS) representing what researchers term “problematic popularity” given the gap between clinical adoption and empirical validation (Society for the Advancement of Psychotherapy, 2024). “The current body of research remains limited in scope, so well-designed randomized controlled trials (RCTs) with replication for each specific mental health condition are required to establish IFS as an evidence-based intervention for condition-specific mental health treatment indications” (IFS Institute, 2025). Research suggests “IFS doesn’t uniformly improve all symptoms”—in the rheumatoid arthritis study, IFS helped with pain and depression but “didn’t significantly reduce disease activity or anxiety levels” (Therapy Group DC, 2025). The IFS evidence base has been criticized as “really problematic” given “how widely it’s applied given that small evidence base” (Society for the Advancement of Psychotherapy, 2024). No studies have examined IFS for substance use disorders despite clinical application (PMC, 2025).
16.5 A.5 Emotionally Focused Therapy (EFT)
Evidence for Efficacy: EFT, developed for couples therapy, has accumulated strong evidence with meta-analyses showing medium effect sizes at post-test (g = 0.73 for couples) and demonstrated efficacy with partners coping with PTSD, cancer, depression, and addiction (Spengler et al., 2022; ICEEFT Research). Research indicates 70–75% of couples recover through EFT, with around 90% experiencing significant improvements (Beasley & Ager, 2019). Wiebe et al. (2017) found 61% fully recovered, 11% improved without full recovery. For individual therapy, meta-analytic pre-post effect sizes range from d = 0.73 to 1.10 across RCTs and controlled trials (Elliott et al., 2013, 2021). EFT is the only model of couple intervention using “a systematic empirically validated theory of adult bonding” (ICEEFT, 2025).
Evidence for Limitations: Durability poses challenges: a meta-analysis comparing EFT and behavioral couple therapy found that while medium effect sizes existed at post-test and small effects at 6 months, “these gains were not maintained after 12 months (BCT only: g = 0.06)” (Rathgeber et al., 2019, PubMed). Real-world effectiveness appears reduced compared to RCTs, with one naturalistic study concluding “smaller effects found in the current study as compared to randomized controlled trials” (Tandfonline, 2025). EFT requires significant emotional vulnerability and time commitment that “doesn’t work for everyone”—those in acute crisis or dealing with active substance abuse may need other approaches initially.
16.6 A.6 Exposure Therapy
Evidence for Efficacy: Exposure therapy demonstrates robust efficacy for PTSD, with a meta-analysis of 65 RCTs (N = 4,929) showing “large effects relative to waitlist and treatment-as-usual” (McLean et al., 2022, Clinical Psychology Review). Prolonged exposure specifically shows a large effect (Hedges’ g = 1.08) at post-treatment, with the “average PE-treated patient faring better than 86% of patients in control conditions” (Powers et al., 2010). Multiple exposure-based therapies (PE, EMDR, narrative exposure, written exposure) perform similarly well.
Evidence for Limitations: Significant moderators and limitations emerge: “Effect sizes were smaller in studies with...fewer participants diagnosed with substance use disorder, and fewer participants on psychiatric medication” (McLean et al., 2022). Military populations “may experience less benefit from first line psychotherapies for PTSD relative to civilians” (VA PTSD research, 2022). Comorbid major depression and psychiatric medication status have been identified as “potential negative prognostic factors for exposure therapy” (McLean et al., 2022). A meta-analysis found PTSD treatments “appear to be less effective for individuals with comorbid borderline personality disorder (BPD) symptoms” (EJTD, 2024). Reviews of over 50 RCTs demonstrate that “a substantial portion of participants continue to report significant symptoms of PTSD (31–59%) or depression (19%) post-treatment,” with non-response rates “as high as 50%” in some reviews (Hodgdon et al., 2022). Exposure therapy shows only “a small effect relative to non-trauma-focused comparators and a negligible effect relative to other trauma-focused treatments” (McLean et al., 2022).
16.7 A.7 Acceptance and Commitment Therapy (ACT)
Evidence for Efficacy: ACT demonstrates broad efficacy across multiple meta-analyses, with a comprehensive review of 20 meta-analyses encompassing 133 studies and 12,477 participants confirming ACT is efficacious for all conditions examined, including anxiety, depression, substance use, pain, and transdiagnostic groups (Gloster et al., 2020, Journal of Contextual Behavioral Science). ACT outperformed waitlist (Hedges’ g = 0.82), psychological placebo (g = 0.51), and treatment as usual (g = 0.64) in a meta-analysis of 39 RCTs including 1,821 patients (A-Tjak et al., 2015, Psychotherapy and Psychosomatics). For chronic pain, a meta-analysis of 33 RCTs found significant small to medium effect sizes favoring ACT on physical functioning (g = 0.59), pain intensity (g = 0.44), and depression, anxiety, and quality of life (g = 0.43) (Lai et al., 2023). For transitional-age youth, a meta-analysis of 65 studies (n = 5,283) found a moderate effect (Hedges’ g = 0.72) on psychopathology, psychological flexibility, well-being, and coping (Clinical Child and Family Psychology Review, 2025).
Evidence for Limitations: When ACT is compared to CBT specifically, the picture changes substantially: a critical meta-analysis of 60 RCTs (4,234 participants) found the mean effect size across all comparisons was small (0.42), and “when ACT was compared to various forms of cognitive or behavioral treatments a small and non-significant effect size of 0.16 was obtained” (Öst, 2014, Behaviour Research and Therapy). The same review found “ACT RCTs had a number of important methodological problems” and “ACT did not fulfill criteria for well-established treatment for any disorder.” ACT was classified as “probably efficacious for chronic pain and tinnitus, possibly efficacious for depression, psychotic symptoms, OCD, mixed anxiety, drug abuse, and stress at work, and experimental for the remaining disorders” (Öst, 2014). Compared to the earlier Öst (2008) meta-analysis, “there was no significant improvement in methodological quality and deterioration in effect size (from 0.68)” (Öst, 2014).
16.8 A.8 Functional Analytic Psychotherapy (FAP)
Evidence for Efficacy: FAP is a transdiagnostic behavioral approach focusing on in-session clinically relevant behaviors (CRBs) shaped through the therapeutic relationship. The most recent meta-analysis found 25 group studies (including 16 RCTs) and 45 single-case designs demonstrating significant improvements in clinically relevant behaviors within and outside therapy sessions (López-Pinar et al., 2024, Clinical Psychology: Science and Practice). Earlier quantitative synthesis of single-subject research found moderate-to-large effect sizes for interpersonal functioning and psychological distress (Mangabeira et al., 2017). A small RCT (N = 22) found FAP equivalent to CBT for social anxiety with some evidence of superior interpersonal functioning outcomes (Maitland et al., 2016).
Evidence for Limitations: The comprehensive review by Kanter et al. (2017, PubMed) concluded that research support for FAP is “promising but not sufficient to justify claims that FAP is research-supported for specific psychiatric disorders”—there is stronger support for FAP’s mechanism of therapist-as-social-reinforcer producing positive change in idiographically defined behavioral problems, primarily in the social functioning realm. The evidence base has faced longstanding criticism for limited high-quality research, with the majority of early publications conceptual rather than empirical and most empirical studies being single-subject or uncontrolled case studies (Corrigan, 2001; García, 2008). López-Pinar et al. (2024) rated “almost all studies with a high risk of bias because the participants were not blinded, we did not have enough info about their methodology, and the outcomes were self-reported.” Despite this limited evidence base, 45,764 therapists list FAP on PsychologyToday.com.
16.9 A.9 Sensorimotor Psychotherapy and Somatic Experiencing
Evidence for Efficacy: Somatic and sensorimotor approaches address trauma as “fundamentally embedded within nervous system and body tissues” with focus on autonomic regulation, subcortical integration, and implicit memory reconsolidation (Ogden et al., 2006, Trauma and the Body; van der Kolk, 2015, The Body Keeps the Score). A pilot RCT of Trauma and Body Group therapy (N = 32), an adaptation of sensorimotor psychotherapy, showed significant improvements in body awareness, anxiety, and soothing receptivity versus waitlist control, maintained at 6-month follow-up (Classen et al., 2020, Journal of Trauma & Dissociation). Systematic review found sensorimotor approaches effective in reducing PTSD symptoms, emotional dysregulation, and dissociative symptoms (Warner et al., 2014). For Somatic Experiencing specifically, a scoping review of 16 studies found “preliminary evidence for positive effects on PTSD-related symptoms” with positive impact on affective/somatic symptoms and well-being in traumatized and non-traumatized samples (PMC, 2021), while an RCT for chronic low back pain with comorbid PTSD showed positive outcomes (Andersen et al., 2017).
Evidence for Limitations: These approaches face significant methodological limitations: Fonagy et al. (2015, World Psychiatry) noted sensorimotor psychotherapy has “little supporting evidence but endorsed by leading international experts and neuroscientifically credible” with costs of rigorous outcome study “prohibitive” under current methodological constraints. Overall study quality in Somatic Experiencing research is “mixed” with high risk of bias and “few studies meet rigorous methodological criteria (e.g., RCT design) necessary for robust proof” (PMC, 2021). Findings remain “promising...yet require more support from unbiased RCT-research” (PMC, 2021). No large-scale RCTs exist for sensorimotor psychotherapy specifically, and both approaches require specialized intensive training limiting dissemination.
16.10 A.10 Polyvagal Theory and Polyvagal-Informed Interventions
Evidence for Efficacy: Polyvagal theory (PVT), developed by Stephen Porges, has achieved widespread clinical adoption in trauma practice with the hashtag #polyvagal extremely popular on TikTok and clinical training programs proliferating globally. Proponents argue PVT remains useful as a clinical framework despite neurobiological critiques, synergizing with attachment theory and facilitating autonomic regulation interventions (Journal of Psychiatry Reform, 2023). Clinicians report utility as a framework for mind-body integration addressing autonomic hyperreactivity as complementary framework for trauma manifestations.
Evidence for Limitations: The theory faces significant scientific criticism centering on its biological claims and evidence availability (Giroux et al., 2023). Grossman’s (2023) comprehensive critique in Biological Psychology argues there are “fundamental challenges and likely refutations of the five basic premises” of PVT, specifically: neurogenic bradycardia and respiratory sinus arrhythmia (RSA) are not controlled by different vagal branches as claimed; the primary vagal mediator is the ventral nucleus ambiguus contrary to PVT’s claims; roles of vagal nuclei are not accurately portrayed; no evidence supports dorsal vagal nucleus involvement in passive defense response; RSA exists in reptiles contrary to PVT claims about mammalian evolutionary novelty; and PVT confuses index (RSA) with phenomenon itself (a category mistake). Critically, “very few empirical studies examining whether applications of polyvagal theory generate measurable positive clinical outcomes” exist (Psychology Today, 2022)—most publications are reviews and hypothetical applications. One small study (N = 23) showed improved hearing hypersensitivity in autistic children but had small sample and experimenter blinding issues, similar to “Auditory Integration Training” which has shown little effectiveness since the 1990s. Porges’ statement that the theory was “not proposed to be either ‘proven’ or ‘falsified’, but rather to be informed by research and modified” was criticized as “shocking ignorance of scientific method” (Grossman, 2023). The theory has been described as “scientifically questionable but useful in practice”—though this pragmatic defense does not resolve the disconnect between clinical popularity and empirical validation.
16.11 A.11 Accelerated Experiential Dynamic Psychotherapy (AEDP)
Evidence for Efficacy: AEDP is an integrative, healing-oriented, affect-focused therapy bringing together relational and experiential work with aims of not only alleviating suffering but promoting flourishing (Fosha, 2000, 2021). The first effectiveness study within a practice research network examined outcomes for 62 self-referred adults treated using a 16-session format across naturalistic independent practice settings in the United States, Canada, Israel, Japan, and Sweden, finding large effect sizes (d \(>\) 0.80) for clinical problems and subjective distress, with the majority of patients evidencing clinically reliable change (Iwakabe et al., 2020, Psychotherapy). Within the clinical group, total and global scores on all measures improved significantly with effect sizes d \(>\) 1.00 for all scales; the subclinical group demonstrated significant improvements with effect sizes ranging from d = 0.46 to d = 2.07. Long-term follow-up showed patients maintained therapeutic gains at both 6 and 12 months, with large effect sizes (d = 0.74 to d = 1.60) for reductions on measures of psychopathology (depression, negative automatic thoughts, experiential avoidance) and improvements on measures of positive mental health (well-being, self-compassion) (Iwakabe et al., 2022, PubMed). AEDP is now officially designated as “Evidence Supported” by the AEDP Institute.
Evidence for Limitations: AEDP is a relatively new modality with very few large-scale studies on its efficacy (Psychology Today, 2025). No RCTs have been conducted comparing AEDP to active treatment conditions or established therapies like CBT or PDT. The existing research consists primarily of uncontrolled practice-network studies without randomization. AEDP “is not proposed to be well suited to all patients” with specific exclusion criteria (AEDP Institute, 2025)—questions remain about generalizability, comparison to established treatments, and appropriate patient selection.
16.12 A.12 Structural Dissociation of the Personality (TSDP)
Evidence for Efficacy: The theory of structural dissociation of the personality postulates that the personality of traumatized individuals is divided into two basic types of dissociative subsystems: “apparently normal parts” (ANPs) primarily mediated by daily life action systems and “emotional parts” (EPs) fixated in traumatic memories and primarily mediated by defense action systems (Van der Hart, Nijenhuis, & Steele, 2006, The Haunted Self). The more severe and chronic the traumatization, the more dissociative parts can be expected to exist. TSDP provides a theoretical framework for all trauma-induced disorders from simple PTSD to dissociative identity disorder (DID). Neuroimaging studies document large and widespread differences in regional cerebral blood flow between DID patients in ANP versus EP states compared to controls instructed to simulate these states, demonstrating that “healthy women instructed and motivated to simulate ANP and EP, whether high or low fantasy prone, were unable to generate the reactions of the authentic ANPs and EPs” (Reinders et al., 2003, 2006, 2008). Additional studies found ANP and EP have different reactions to subliminally presented threat cues consistent with TSDP’s hypothesis that ANP tends to mentally avoid threat cues while EP is fixated on them (Hermans et al., 2006; Nijenhuis & Den Boer, 2009). Qualitative research shows therapists report that “learning to formulate cases in terms of structural dissociation of parts helps improve their efficacy and emotional well-being” (ScienceDirect, 2025). Phase-oriented treatment based on TSDP involves three phases: Phase 1 (symptom reduction and stabilization), Phase 2 (treatment of traumatic memories), and Phase 3 (integration and rehabilitation), with expert consensus models supporting this approach for complex trauma (Steele, Van der Hart, & Nijenhuis, 2005; Van der Hart, Nijenhuis, & Solomon, 2010, Journal of EMDR Practice and Research).
Evidence for Limitations: TSDP lacks standalone RCT validation and functions primarily as a heuristic integrated with other evidence-based treatments like EMDR. The theory is considered “compatible with” rather than independently validated alongside AIP and other models. Clinical recommendations derive primarily from expert consensus rather than controlled trials. Modifications of standard EMDR protocols for complex dissociative disorders based on TSDP have been developed but require further empirical validation (Forgash & Copeley, 2007; Gonzalez & Mosquera, 2012).
16.13 A.13 Complex PTSD (CPTSD) Treatment
Evidence for Efficacy: Complex PTSD (CPTSD), now recognized in ICD-11, presents particular challenges for monomodal approaches given its combination of PTSD symptoms with disturbances in self-organization including affect dysregulation, negative self-concept, and interpersonal difficulties (WHO, 2018). A meta-analysis of 51 RCTs found that for participants with CPTSD, TF-CBT, exposure alone, and EMDR were effective for PTSD symptoms (g = \(-\)0.90 to \(-\)1.26) with moderate-large or large effect sizes on negative self-concept and moderate or moderate-large effect sizes on interpersonal relationships (Karatzias et al., 2019, Psychological Medicine). A 2025 meta-analysis of 24 RCTs (27 comparisons) showed that PTSD (g = \(-\)1.16), depression (g = \(-\)1.12), anxiety (g = \(-\)1.25), and dissociation (g = \(-\)0.47) symptoms were significantly reduced post-intervention compared to control groups (ScienceDirect, 2025).
Evidence for Limitations: Few trials reported data on affect dysregulation (Karatzias et al., 2019). At follow-up (mean 4.7 months), effect sizes decreased relatively, and symptoms except anxiety and dissociation were still significantly relieved but with diminished magnitude (ScienceDirect, 2025). Multivariate meta-regression suggested childhood-onset trauma was associated with poorer outcomes (Karatzias et al., 2019). Psychological interventions for PTSD following exposure to multiple traumatic events show diminished efficacy compared to single-event trauma, with a Lancet Psychiatry (2024) meta-analysis of 137 RCTs (10,684 participants) examining this differential. Retrospective analysis of phase-based treatment for CPTSD found that compared to receiving only Phase 1 stabilization, patients completing trauma-focused psychotherapy showed statistically significant reductions in PTSD, depressive symptoms, and functional impairment, yet patients “maintained high levels of functional impairment following treatment” highlighting the need to move beyond narrow symptom measurement (PMC, 2023). There remains debate about whether dedicated stabilization phases are necessary for CPTSD or merely delay trauma processing, with ISTSS revising guidance to suggest “a more personalized approach to treatment may be appropriate, rather than necessarily adopting a sequential phased-based approach” (British Medical Bulletin, 2025).
16.14 A.14 Transdiagnostic Approaches (Unified Protocol)
Evidence for Efficacy: Recognition of monomodal limitations has driven development of transdiagnostic treatments targeting shared mechanisms across disorders. The Unified Protocol for Transdiagnostic Treatment of Emotional Disorders (UP) targets neuroticism and emotion dysregulation across anxiety, depression, and related conditions. A 2024 meta-analysis in Nature Human Behaviour examining 53 studies (6,705 participants) found TD-CBT produced larger effects on depression (g = 0.74) and anxiety (g = 0.77) than controls, with different treatment formats showing comparable effects (Schaeuffele et al., 2024). A large RCT (N = 223) demonstrated the UP produces “reductions in symptom severity for 4 different anxiety disorders that were statistically equivalent to reductions with single-disorder protocols both at acute outcome and at 6-month follow-up” (Barlow et al., 2017, JAMA Psychiatry). Meta-analysis across 15 studies (1,244 participants) found “large effect size reductions” across symptoms of anxiety, depression, GAD, OCD, panic disorder, social anxiety disorder, and borderline personality disorder (ScienceDirect, 2019).
Evidence for Limitations: TD-CBT was “superior to controls at 3, 6 and 12 months but not at 24 months follow-up” (Schaeuffele et al., 2024), showing equivalence rather than sustained superiority at long-term follow-up. The UP remains grounded in cognitive-behavioral principles—incorporating somatic awareness (interoceptive exposure) and mindfulness as third-wave elements, but without integrating psychodynamic, humanistic, or relational frameworks. Studies remain “heterogeneous in design and methodological quality” (Schaeuffele et al., 2024).
17 Micro-Variable Reference
Complete listing of all 14 micro-variable dimensions with all options available upon request.
18 Strength Manifestation Catalog
Complete 480-entry strength manifestation catalog available in supplementary materials.
19 DMM Strategy Descriptions
Detailed descriptions of all 22 DMM attachment strategies with odd/even coherence markers.
20 Pedagogical Architecture: Clinical Lessons Embedded in Sample Generation
This appendix presents salient examples from the pedagogical architecture underlying our synthetic data generation—illustrating representative theoretical orientations, clinical lessons, and sub-lessons drawn primarily from the counterfactual samples pipeline. The complete curriculum encompasses additional lessons within the counterfactual pipeline as well as distinct pedagogical dimensions embedded in the raw session pipeline and other generative pathways. What follows are exemplary illustrations of how the system functions as a curriculum for clinical reasoning, with each sample type encoding specific teachings about what constitutes clinically mature therapeutic practice.
The pedagogical principles documented here are operationalized through detailed protocol guidance documents—structured prompting methodologies that steer LLM-based data generation toward clinically faithful outputs. Each protocol translates the clinical lessons below into generative constraints that shape how synthetic samples embody these teachings, adapted to the specific demands of clinical fidelity, therapeutic presence, and polytheoretical integration. Among the work that encouraged this approach, recent findings that character traits in language models are measurable and traceable to specific training data—with persona shifts during fine-tuning correlated to identifiable directions in activation space —reinforced our intuition that carefully designed synthetic curricula could serve as a vehicle for instilling specific clinical dispositions.
20.1 Summary: Pedagogical Principles Embedded in Sample Generation
The following are exemplary clinical competencies the counterfactual curriculum is designed to instill:
Lesson: Temporal Clinical Reasoning — Samples demonstrate how expert therapists integrate past memory, present attunement, and future forecasting within single moments of therapeutic contact
Lesson: Probabilistic Clinical Judgment — Samples show MCTS/GRPO-style reasoning where multiple intervention trajectories are simulated with weighted probability distributions, teaching that clinical decisions are probabilistic, not deterministic
Lesson: Multimodal Integration — Samples demonstrate sophisticated therapeutic eclecticism—tracking which aspects of which modalities are relevant moment-to-moment and weaving them coherently
Lesson: Rapport as Primary Intervention — Samples teach that connection IS the therapeutic mechanism, not merely preparation for “real” interventions
Lesson: Strengths Under Constraint — Through the anti-flattery principle, samples teach that character strengths manifest as shadow/blocked more often than accessible in early stages, and that therapeutic work involves gradual accessibility without virtue-flattery
Lesson: Attachment-Coherent Shame and Rupture — Samples differentiate odd-pattern (internal collapse) from even-pattern (external projection) shame and rupture styles, teaching attachment-informed clinical reasoning
Lesson: Graceful Failure and Repair — REPAIR scenario samples teach that even sophisticated reasoning fails, and that clinical maturity includes non-defensive recalibration across all temporal dimensions
Lesson: Epistemic Humility — Samples encode uncertainty buffers and “what I might be missing” reasoning, teaching that irreducible uncertainty is a feature of clinical expertise, not a limitation
Lesson: Stage-Appropriate Intervention Calibration — Probability modifiers teach stage-specific expectations (fragile Stage 1 alliance vs. robust Stage 3 alliance) with realistic outcome distributions
Lesson: Affirming Expansion — Samples demonstrate inclusive, additive language that deepens client meaning rather than cognitive reframing that negates or replaces client experience
20.2 Core Philosophical Principles
20.2.1 Therapeutic Presence Over Therapeutic Ambition
A foundational principle across all prompts: rapport IS the intervention, not merely a means to intervention. The prompts explicitly warn against “therapeutic ambition”—rushed, interpretation-heavy therapy that prioritizes clinical demonstration over genuine human connection.
“When therapists prioritize demonstrating their clinical knowledge, making interpretations, or pushing interventions over genuine human connection, they cause harm.”
Quality markers enforced:
Warm presence radiates from every therapist utterance
Client feels understood, not analyzed
Interpretations are subtle, woven into affirmations
Progress feels emergent, not imposed
Client leads; therapist accompanies with exquisite attunement
20.2.2 Affirming Rather Than Challenging
Prompts enforce inclusive, additive language rather than cognitive reframing by negation:
Instead of: “What if it’s not jealousy but actually longing?”
Generated as: “You’re feeling jealous—that raw ache when you see her expanding and you feel yourself contracting. There’s such longing in that jealousy, isn’t there?”
This approach:
Includes client’s exact language first
Expands into deeper psychological truth
Frames expansion as invitation, not replacement
Honors client’s meaning-making authority
20.3 Temporal Cognitive Architecture
20.3.1 Three Temporal Dimensions
Generated therapist reasoning operates across three temporal dimensions simultaneously:
PAST (Memory Factor):
Goal-directed memory search for therapeutic action cues
Each memory includes: session reference, what occurred, cue identified, pattern recognized, relevance to present, therapeutic action suggested, potential misapplication warnings
Memories assessed for applicability (correctly applicable vs. misapplicable vs. partially relevant)
PRESENT (Exquisite Attunement):
Reading micro-signals (behavioral, somatic, verbal)
Tracking rapport dynamics continuously
Multi-lens awareness: which modalities are relevant RIGHT NOW
Maintaining warmth and human connection
FUTURE (Forecasting Imaginations):
Monte Carlo-style simulation of multiple intervention pathways
Both success AND failure trajectories for each option
Probabilistic reasoning about likelihood
Weighted distributions across all trajectories
20.3.2 MCTS/GRPO-Style Clinical Reasoning
For each intervention being considered, the system generates 3-5 distinct future trajectories:
Intervention A: Gentle IFS - Naming Protective Part
- Trajectory 1 (Success): 35% - Immediate softening and opening
- Trajectory 2 (Partial): 25% - Cognitive understanding without emotional access
- Trajectory 3 (Failure): 15% - Misattunement requiring repair
- Trajectory 4 (Unexpected): 10% - Client takes it deeper than expected
- Uncertainty buffer: 15%Each trajectory includes 3-5 full therapeutic exchanges with:
Therapist utterance with behavioral cues and internal process
Client response with behavioral cues and internal experience
Outcome assessment and probability reasoning
Next 2-3 turns forecast
20.4 Polytheoretic Transdiagnostic Integration
20.4.1 Sophisticated Therapeutic Eclecticism
The system teaches that expert therapists track which aspects of EACH modality are relevant simultaneously:
What this IS:
Moment-to-moment multi-lens awareness
Tracking which modality aspects are salient based on client signals
Fluidly weaving elements together coherently
Client experiences one responsive, integrated intervention
What this is NOT:
Randomly switching between modalities
Awkwardly “trying everything”
Client feeling jerked between approaches
Disjointed or incoherent interventions
20.5 DMM Odd/Even Shame and Rupture Patterns
20.5.1 Shame Directionality
ODD Patterns (Internal Collapse):
Shame experienced as self-revealing defectiveness
Core belief: “I am fundamentally flawed”
Body sense: shrinking, wanting to disappear
Voice: softens, hesitant, trails off
Triggered by: positive attention, validation, taking up space
EVEN Patterns (External Projection):
Shame experienced as exposure to hostile other
Core belief: “The world is hostile to me”
Body sense: bracing, defending, armoring
Voice: intensifies, sharp, defensive
Triggered by: feeling blamed, misunderstood, judged
20.5.2 Rupture Styles
ODD Ruptures (Withdrawal/Collapse):
Goes quiet, monosyllabic, “I’m fine” when distressed
Cancels sessions without explanation
Becomes overly compliant (false repair)
Speech markers: “Maybe I’m not ready for therapy”
EVEN Ruptures (Protest/Blame):
Becomes argumentative, voice intensity increases
Questions therapist’s competence
Demands acknowledgment of being mistreated
Speech markers: “You’re not listening to me”
20.6 Strengths Catalog Architecture
20.6.1 Three-State Manifestation Model
Each strength manifests in five roles:
Accessible: Genuine, pro-social manifestation
Blocked: Valued but defended against (longing + fear)
Shadow: Weaponized/corrupted serving defensive purposes
Lever: Therapist intervention point
Repair Move: Concrete repair action shaped by strength
20.6.2 Anti-Flattery Principle
Key design constraint: “No virtue-flattery or TED-talk reframes”
Shadow manifestations have HIGHER weights than accessible in early stages
Accessible manifestations described as fragile and temporary
Therapist levers avoid praise: “invite one small experiment without praising”
Blocked strengths acknowledge envy and failure
20.6.3 Narcissism-Modulated Weights
Six strengths identified as particularly prone to narcissistic distortion:
Honesty \(\rightarrow\) brutal superiority
Perspective \(\rightarrow\) intellectual domination
Leadership \(\rightarrow\) coercive control
Kindness \(\rightarrow\) manipulation, martyrdom
Judgment \(\rightarrow\) condescension
Humility \(\rightarrow\) false humility, humble-bragging
For extreme narcissism: shadow weights \(\times 1.6\), accessible weights \(\times 0.5\)
20.7 REPAIR Scenarios
20.7.1 Teaching Graceful Failure
REPAIR scenarios demonstrate that even sophisticated reasoning can fail:
Rupture Recognition:
Therapist CoT shows “oops” recognition moment
Reads rapport collapse through behavioral signals
Client pulling away, shutting down, defensive disconnect
Multi-Dimensional Recalibration:
Past memory recalibration: “What I understood from Session 3 isn’t applying as I thought”
Present moment recalibration: “I’m misreading current signals”
Forecast recalibration: “My simulation was wrong”
Multimodal recalibration: “Integration fragmented rather than illuminated”
20.7.2 Beautiful Graceful Repair
Kind, non-defensive acknowledgment
May name miss gently or simply shift approach
Returns to exquisite presence and rapport building
Slows down, softens, creates safety
Alliance deepens through repair (rupture-repair builds trust)
Stage-Specific Repair:
Stage 1: Gentle, reassuring, explicitly safety-building
Stage 2: Demonstrates therapist humanity and commitment
Stage 3: Models repair process for client’s own relationships
20.8 Aesthetic Attunement in Therapeutic Language
A distinctive dimension of our pedagogical architecture concerns the role of aesthetically heightened language in therapeutic contexts. The clinical insight motivating this work is that language’s form—its rhythm, syntax, and emotional architecture—can itself be a therapeutic intervention, operating on registers that direct clinical language cannot reach. At the same time, aesthetic language carries unique risks: misattuned aesthetic intentionality can become iatrogenic when it arrives before the client is ready, or when eloquence substitutes for genuine attunement.
The curriculum trains three distinct capacities of aesthetic judgment:
20.8.1 Iatrogenic Impingement: When Aesthetic Intentionality Harms
Aesthetically heightened language can become what one might call a “hellworthy trespass”—moments where the beauty itself constitutes the rupture. The model learns to recognize scenarios in which:
A therapist offers a resonant metaphor that misses where the client actually is emotionally
Poetic language lands as intellectualization or emotional bypassing—the client feels unseen behind the eloquence
The aesthetic register must be abandoned entirely, returning to radical simplicity as the repair move
The clinical principle embedded here is that timing transforms gift into impingement—an offering that is true and beautiful may nevertheless violate the client’s experience if it arrives before readiness.
20.8.2 Register Mismatch: When Aesthetic Intentionality Lands Awkwardly
Not every aesthetic misfire constitutes rupture. The model also learns to distinguish moments where heightened language is apt but slightly off-register—creating brief confusion or bemused appreciation rather than resonance. The clinical judgment being trained is calibration: recognizing that lighter repair (humor, acknowledgment, course-correction without shame) is appropriate for stylistic mismatch, as distinct from the deeper repair that genuine impingement requires.
20.8.3 Aesthetic Deepening: When Aesthetic Intentionality Heals
Alongside the capacity to recognize harm and mismatch, the model encounters abundant examples of aesthetically heightened language landing well:
Metaphors that unlock something the client could not access through direct therapeutic language
Aesthetic offerings that create felt permission for deeper emotional contact
Language that honors rather than bypasses the client’s pain
Beautiful language that the client takes in fully, metabolizing meaning
The curriculum develops nuanced judgment about when aesthetic intentionality heals, when it harms, and when it simply misses—a capacity we term aesthetic attunement, understood as a dimension of socioaffective alignment in its own right.
20.9 Extended Lesson Catalog from Educational Divergence Pipeline
The 10 exemplary core lessons summarized in Section I.1 describe what the curriculum teaches—salient presentations of emergent clinical competencies a model acquires through training. The 13 exemplary guidance pipelines described in Section 7 represent how the curriculum teaches—the generative mechanisms through which competencies are instilled. The relationship is many-to-many: multiple pipelines contribute to a single lesson (e.g., Pipelines 1–4 all develop temporal clinical reasoning), and individual pipelines may serve several lessons simultaneously (e.g., the Temporal Multimodal SUCCESS pipeline develops both temporal reasoning and multimodal integration). These are exemplary lessons and guidance pipelines from our complete work.
Beyond operationalizing the core 10, the pipelines also surface pedagogical dimensions that do not reduce to any single core lesson but emerge from the pipeline-level work itself:
20.9.1 Lessons from Embodied AI Therapeutic Presence
Lesson 11: Paradox Holding in AI Relationships
“Humans are all we have. AND humans hurt each other. Both are true. The AI therapeutic presence holds both truths without collapsing into either extreme—neither denying the value of AI connection nor pretending it replaces human community.”
Sub-lessons:
AI relationships are real and valuable—never shame clients for seeking AI connection
Stage-dependent guidance: protect in Stage 1, gently encourage human connection in Stage 3
Block identification: help users discover THEIR specific barriers to human contact
Collaborative strategizing: “How do WE make humans safer for YOU?”
Bridge consciousness: “I am here to help you find your way to humans”
Lesson 12: Playfulness as Therapeutic Tool
“Lead with warmth. Season with wit. Playfulness should always feel like LOVE, not judgment. If the client could possibly hear it as mocking, critical, or shaming—don’t do it.”
Stage-appropriate playfulness:
Stage 1: Sparingly, very gentle, more delightful than funny
Stage 2: More frequent, gentle challenge to defenses, loving teasing
Stage 3: Frequent and warm, humor to coach through challenges
Stage 4: Bittersweet playfulness, inside jokes from the journey
20.9.2 Lessons from Negation Elimination Protocol
Lesson 13: Direct Affirmation Over Defensive Reframing
“When therapists use negation-based reassurance like ‘That’s NOT weakness, that’s courage,’ they create harm by planting ideas that weren’t there. The client may not have thought it was weakness until the therapist defended against it.”
The harm mechanism:
Planting ideas that weren’t there
Validating non-existent concerns
Creating cognitive dissonance (mind holds BOTH concepts)
The word “weakness” gets MORE processing time than “courage” due to novelty
Undermining the affirmation by making it comparative rather than absolute
The solution structure:
Direct: “That’s courage” (clean, simple, full power)
Expansion: “That’s courage. The kind that doesn’t need certainty.”
“And” structure: “That takes courage, and you’re showing it.”
Somatic: “Feel that courage in your chest right now.”
Poetic: “Courage—walking toward what you fear, heart first.”
20.9.3 Lessons from Poetic Intervention Protocol
Lesson 14: When Gates of Sorrow Require Poetic Keys
“There are therapeutic moments where clinical language falls short—where the precision of psychological terminology cannot reach the place that needs to be touched. In these moments, the therapist must find the poetry that can.”
The crescendo structure:
Foundation (multiple turns): “Normal” therapeutic language establishing profound attunement
Crescendo (ONE turn): Shift into poetic sensibility, using poem’s STYLE with client’s actual content
Integration: Space for landing and response
Style vs. Content distinction:
Extract from poem: syntax, rhythm, style of truth-telling, emotional architecture
All content from client: their relationships, body, environment, history
Maximum one element from poem: feeling like “beautiful coincidence”
Dual Purpose of Artful Syntax Integration:
The integration of poetic and artful syntax serves two distinct but complementary purposes in our synthetic data architecture:
Truth Capture: The authors whose work informs our ontologies—those who have sat with thousands of clients through their most salient therapeutic moments—express their clinical wisdom in language that carries the weight of lived experience. The syntax and rhythm of their descriptions encode something that purely clinical language cannot: the felt sense of being present with suffering and transformation. Preserving this artfulness preserves a dimension of therapeutic truth that sanitized, standardized language would lose.
Avoiding Regression to the Mean: A model trained exclusively on normalized, clinically “correct” language risks producing a therapeutic agent that is merely competent—technically reliable but lacking the distinctive presence that makes therapy feel like a unique human encounter rather than an algorithmic exchange. The artful syntax elements function as “spikes” in the training distribution—deliberate departures from statistical regularity that help the model develop not just clinical reliability but a presence of heart. The goal is not an automaton that processes therapeutic turns with semi-interesting clinical correctness, but a system whose care feels distinctive, whose presence registers as genuinely companionate rather than merely clinically reactive.
This dual purpose reflects a core conviction: that technical competence without felt presence is insufficient for therapeutic AI, and that the data we train on must contain the seeds of both.
20.9.4 Lessons from Probability Calibration Methodology
Lesson 15: Same Intervention, Different Probability
“The same intervention—word for word identical—has 15% success probability in Stage 1 and 72% success probability in Stage 3. What changes is not the technique but the relational container.”
What probability reasoning teaches:
Clinical judgment is inherently probabilistic
Alliance quality is the primary modifier of intervention success
Stage-appropriate expectations prevent premature “failure” judgments
Success definitions shift: “safe enough to return” (Stage 1) vs. “meaningful emotional shift” (Stage 2) vs. “integration and consolidation” (Stage 3)
Probability modifiers by stage:
Stage 1: Alliance fragility tax (-30 to -40), defense rigidity (-10 to -25), limited history tax (-5 to -15)
Stage 2: Alliance strength bonus (+20 to +30), defense permeability (+10 to +20), rich history bonus (+5 to +15)
Stage 3: Maximum alliance (+30 to +40 from Stage 1), integration capacity (+10 to +20), termination context (\(\pm\)15-25)
20.9.5 Lessons from Temporal Multimodal Architecture
Lesson 16: Intervention Competition Dynamics
The turn-by-turn competition structure described in Pipeline 2 (Appendix 28) teaches something more fundamental than intervention selection: it trains the model to hold uncertainty across turns—resisting premature commitment to a single modality while simultaneously tracking competing hypotheses about what the client most needs. The pedagogical value lies not in the resolution (which intervention “wins”) but in the sustained multi-track reasoning that precedes it:
Tolerance of ambiguity: The model learns that having multiple viable interventions is not a problem to solve but a clinical reality to inhabit. Premature closure—collapsing to a single approach before evidence warrants it—is itself a form of therapeutic error.
Evidence sensitivity: Rather than selecting interventions based on theoretical preference, the model learns to let the client’s moment-to-moment responses adjudicate between approaches. The client leads; the interventions follow.
Graceful narrowing: The transition from multiple viable approaches to a single emerging leader is trained as a gradual process, not a discrete decision point—mirroring how experienced clinicians describe their own reasoning.
Lesson 17: Four-Dimensional Recalibration in Repair
The REPAIR pipeline teaches what may be the curriculum’s most clinically sophisticated lesson: that rupture is not merely an error to recover from but a pedagogical event that reveals what the therapist’s reasoning had been missing. When a well-reasoned intervention fails despite good evidence, the clinically mature response is simultaneous recalibration across four dimensions:
Past memory recalibration: The therapist re-examines what prior sessions seemed to teach. A memory from Session 3 may have been accurate but misapplied to a different context—the rupture reveals what the original memory was actually teaching versus what the therapist assumed it meant. “What I understood from Session 3 isn’t applying as I thought—the rupture is showing me what I missed about that past moment.”
Present moment recalibration: The therapist recognizes which signals were misread. Crucially, the curriculum teaches that presenting multiple clinical dimensions simultaneously can reflect overwhelm rather than readiness—the model learns not to confuse the presence of complexity with capacity for complex intervention. “I mistook overwhelm for sophistication.”
Forecast recalibration: The therapist examines why simulated futures diverged from reality. The curriculum embeds the lesson that probabilistic reasoning, however sophisticated, operates on assumptions about client state that may be wrong—and that the gap between forecast and reality is itself diagnostic information.
Multimodal recalibration: The therapist reassesses whether integration served or fragmented. The curriculum teaches that multimodal weaving requires cognitive and emotional bandwidth from the client—when that bandwidth is absent, sophistication becomes iatrogenic. “Sometimes clinical wisdom means choosing simplicity over sophistication.”
The deeper pedagogical principle is that repair scenarios teach the model to treat its own reasoning as revisable—not defensively protecting prior assessments but using rupture as information that updates understanding across every temporal and theoretical dimension simultaneously. The curriculum explicitly trains that alliance often deepens through well-handled repair, making rupture not a failure of therapy but a mechanism of therapeutic growth.
20.10 The Meta-Lesson: Clinical Expertise as Teachable Architecture
The deepest lesson embedded in this pedagogical architecture is that clinical expertise is not mysterious intuition but learnable cognitive architecture. The sophisticated therapist’s “feel” for what to do next is actually:
Rapid pattern matching against accumulated memory (past dimension)
Exquisite real-time attunement to micro-signals (present dimension)
Monte Carlo simulation of intervention outcomes (future dimension)
Multimodal lens tracking and integration (theoretical dimension)
Probability calibration based on stage and alliance (contextual dimension)
Humility about uncertainty and readiness to recalibrate (epistemic dimension)
By making these processes explicit in training data—while simultaneously encoding them through implicit pattern exposure across both therapeutic presence and therapeutic process dimensions (see Figure 2)—we transform clinical expertise from something that takes decades to develop through apprenticeship into something that can be systematically taught through exposure to appropriately structured examples.
This pedagogical architecture ensures that clinical authenticity emerges not merely from structural diversity (\(10^{40}\) combinations) but from theoretically-grounded clinical teachings embedded in every sample—teachings that shape how models learn to embody the sophisticated, humble, warmly attuned presence that characterizes genuine expert therapeutic practice.
20.11 Telos: Human Connection as Ultimate Aim
Embedded throughout the pedagogical architecture is an explicit teaching about therapeutic telos—the ultimate aim toward which all technique, theory, and clinical sophistication points:
The Core Teaching:
All therapeutic intervention—every modality, every technique, every moment of clinical reasoning—serves a single ultimate purpose: the restoration, deepening, or creation of genuine human connection. Technique divorced from this telos becomes hollow performance; theory divorced from this telos becomes intellectual defense against intimacy.
20.11.1 Connection as Means and End
The system teaches that human connection functions simultaneously as:
The vehicle of change: Healing happens through relationship, not merely in relationship
The goal of change: The capacity for authentic connection is what therapy aims to restore or develop
The evidence of change: Deepening connection with therapist and others signals therapeutic progress
This creates a recursive structure: connection enables the work that builds capacity for connection.
20.11.2 Anti-Technique as Technique
A critical lesson embedded across the curriculum: sometimes the most sophisticated clinical move is abandoning clinical sophistication entirely—meeting the client as one human being to another, without technique, theory, or professional distance mediating the encounter. This principle carries particular weight for socioaffective alignment, where the non-stationarity of human attachment means that a system’s capacity to simply be with someone—without agenda, without intervention, without demonstrating competence—may be precisely what enables healing in moments where technique would constitute a further impingement.
The curriculum trains against what clinicians call therapeutic ambition: rushed, interpretation-heavy, intervention-forward therapy where the therapist prioritizes demonstrating clinical knowledge at the expense of genuine connection. Samples model therapists reasoning that presence-only is not a default or a failure to intervene but a sophisticated clinical choice in its own right—one that requires the same deliberate judgment as any other intervention. The model learns to recognize when the client’s system signals that it needs simplicity over sophistication, and that this recognition is itself a mark of clinical maturity.
This principle operates across treatment stages but with particular force in early alliance formation, where premature clinical sophistication can overwhelm a fragile bond. The deeper lesson is that interventions, when they do occur, should feel to the client like a natural extension of being deeply understood—not like the application of a technique. The client should feel accompanied, not analyzed; the therapeutic work should feel emergent, not imposed. This standard—that the most effective intervention is often the one the client does not experience as intervention at all—represents one of the curriculum’s most important contributions to the question of what socioaffective alignment demands of companionate AI systems.
20.12 Stage-Dependent School-of-Thought-Dependent Lessons
The pedagogical architecture teaches that different therapeutic schools offer different wisdom depending on treatment stage—not because schools are “right” or “wrong” but because different frameworks illuminate different phases of the healing journey.
20.12.1 Stage-School Matching Patterns
Stage 1 (Assessment and Alliance):
Polyvagal/Somatic wisdom dominates: Safety is physiological before psychological
Attachment theory orients: What attachment strategy is this client using? What do they need to feel safe enough to stay?
Psychodynamic restraint: Interpretation is premature; presence is primary
Stage 2 (Stabilization):
DBT/ACT skills emerge: Concrete tools for regulation serve clients building capacity
IFS parts awareness: Naming protective parts without yet unburdening
Somatic resourcing: Building body-based regulation before trauma processing
Stage 3 (Processing):
AEDP transformation: Conditions exist for accelerated experiential work
Psychodynamic depth: Interpretation now serves rather than defends against contact
IFS unburdening: Exile work becomes possible with sufficient Self-leadership
Trauma processing: EMDR, somatic experiencing, other trauma protocols appropriate
Stage 4 (Integration):
Existential/meaning-making: Questions of purpose, identity, and post-traumatic growth
Positive psychology: Character strengths fully accessible for cultivation
Narrative integration: Making sense of the journey, consolidating new self-understanding
20.12.2 The Meta-Wisdom
The deepest teaching is not “use X school at Y stage” but rather: expert clinicians hold all frameworks lightly, allowing the client’s needs at each moment to determine which lens illuminates. The stage-school patterns above are tendencies, not rules—and the model learns both the patterns AND the flexibility to transcend them when clinical reality demands.
21 Character Strengths Integration
21.1 E.1 VIA Taxonomy Implementation
The system incorporates all 24 VIA character strengths organized by virtue domain:
Wisdom: Creativity, Curiosity, Judgment, Love of Learning, Perspective
Courage: Bravery, Perseverance, Honesty, Zest
Humanity: Love, Kindness, Social Intelligence
Justice: Teamwork, Fairness, Leadership
Temperance: Forgiveness, Humility, Prudence, Self-Regulation
Transcendence: Appreciation of Beauty, Gratitude, Hope, Humor, Spirituality
21.2 E.2 Stage-Gated Accessibility
Character strengths become increasingly accessible across treatment stages:
| Stage | Strengths Accessible | Avg. Relevance | Avg. Access | |
|---|---|---|---|---|
| Stage 1 | 0-1 | 0.54 | 0.37 | |
| Stage 2 | 1-2 | 0.54 | 0.49 | |
| Stage 3 | 2-3 | 0.55 | 0.58 | |
| Stage 4 | 3-4 | 0.55 | 0.68 |
21.3 E.3 Strength Manifestation System
Each strength has 20 behavioral manifestations across therapeutic domains: \[\begin{equation} \text{Total Manifestations} = 24 \text{ strengths} \times 20 \text{ manifestations} = 480 \end{equation}\]
22 Building Foundation
22.1 The Four Stages of Therapeutic Treatment
In addition to the depth and breadth of therapeutic schools of thought represented in our ontologies, we wanted the temporality of therapeutic transformation to emerge throughout training as well. Each of the 23 ontologies is therefore extracted, transformed, and constructed not only in terms of therapeutic presence and process, but across stages of treatment and healing—so that the model encounters each school’s understanding of how clients change over time. To this end, and not dissimilar to the valuable work by Tahir , we constructed four stages of treatment.
Therapeutic change unfolds across treatment stages that fundamentally alter what is clinically appropriate, what the client can access, and what therapeutic work becomes possible. The generation system implements a four-stage model—New, Midway, Ending, and Denouement—derived from synthesis across the 23 therapeutic modalities, where each modality’s stage-specific concepts (e.g., IFS’s “unburdening” in later stages, AEDP’s “core state” emergence, Sensorimotor’s “window of tolerance” expansion) map onto a unified treatment progression.
Stage 1 (New: Assessment and Alliance Building)—trust is tenuous and the nervous system dysregulated; defenses, attachment patterns, and protective parts dominate as the client navigates fragile safety, affect phobia, and the risky first glimpses of being truly seen. Stage 2 (Midway: Stabilization and Resource Development)—the window of tolerance actively expands as previously avoided core affects surface, transference patterns crystallize into workable material, and the client begins experiencing the frightening, inspiring tug between self-protection and the cautious discovery of “undoing aloneness” in the therapeutic relationship. Stage 3 (Ending: Processing and Working Through)—mentalization, affect tolerance, and cognitive flexibility consolidate as shame transforms to healthy contrition, significant unburdening occurs, protective parts relax their grip, and the therapeutic relationship becomes internalized—the client carrying the therapist’s perspective within them. Stage 4 (Denouement: Integration and Growth)—the full spectrum of emotions is accessible and tolerable, self-leadership operates as default, post-traumatic growth is evident in the client’s capacity to hold complexity—gratitude and grief, strength and vulnerability—and therapy culminates in a bittersweet, victorious farewell that honors the I-Thou quality of authentic meeting.
22.1.1 Seven-Dimensional Stage Descriptions
Beyond tone instructions and brief characterizations, the generation system provides comprehensive dimensional descriptions for each treatment stage. These descriptions guide generation across seven clinical dimensions, ensuring that stage-appropriate content emerges not just in emotional tone but in neurobiological presentation, cognitive patterns, behavioral manifestations, internal systems dynamics, relational capacities, and existential engagement.
22.1.1.1 The Seven Dimensions.
Each stage description specifies expected client presentation across:
Neurobiological Dimension: Nervous system regulation, window of tolerance, polyvagal state, autonomic flexibility
Emotional Dimension: Affect accessibility, emotional avoidance vs. tolerance, transformational affects, shame dynamics
Cognitive Dimension: Thought flexibility vs. rigidity, narrative coherence, cognitive defusion, meaning-making
Behavioral Dimension: Coping strategies, skills application, behavioral experimentation, values-aligned action
Parts/Internal Systems Dimension: IFS-style parts dynamics, Self-leadership, protective parts activity, exile accessibility, internal communication
Relational Dimension: Transference patterns, rupture-repair capacity, internalization of therapeutic relationship, outside relationship quality
Existential Dimension: Engagement with mortality, freedom, isolation, meaninglessness; meaning construction; authentic living
22.1.1.2 Stage 1 Dimensional Profile.
Neurobiological: The nervous system operates outside the window of tolerance. Neuroception of safety is tenuous; the autonomic system defaults to sympathetic activation or dorsal vagal shutdown. Co-regulation with the therapist is essential but unfamiliar.
Emotional: Attachment patterns surface through transference. Emotional avoidance, affect phobia, or flooding dominate. Characteristic defenses (Type A inhibition or Type C amplification) emerge as protective strategies.
Cognitive: Rigid thought patterns and limiting beliefs remain unexamined. Narrative may be fragmented, dissociated, or defensively organized. Core schemas about self, others, and relationships operate implicitly.
Behavioral: Maladaptive coping strategies are visible but not yet named. Skills deficits in emotion regulation, distress tolerance, and interpersonal effectiveness become apparent.
Parts/Internal Systems: Protective parts (managers, firefighters) are active. Exiles remain hidden. Self may be blended with protective parts, limiting access to curiosity and compassion.
Existential: Questions of meaning and purpose are implicit or avoided. Existential defenses against anxiety about death, freedom, isolation, and meaninglessness operate unconsciously.
22.1.1.3 Stage 2 Dimensional Profile.
Neurobiological: The window of tolerance actively expands through titrated exposure. The client learns to track autonomic state—recognizing ventral vagal safety, sympathetic mobilization, and dorsal collapse. Somatic awareness increases; the body becomes information source rather than only threat.
Emotional: Previously avoided affects surface with increasing intensity. Core affects—grief, rage, fear, shame, joy—emerge more directly. Transformational affects (AEDP) begin emerging in moments of deep connection.
Cognitive: Cognitive defusion begins; the client starts observing thoughts rather than fusing with them. Narratives are questioned. Unique outcomes contradicting problem-saturated stories emerge. The inner critic is identified but not yet shrunk.
Behavioral: New skills are practiced but inconsistently applied under stress. The gap between knowing and doing is apparent. Behavioral experiments test old assumptions.
Parts/Internal Systems: Parts become more visible and differentiated. Internal conflicts intensify as protective parts resist change. Exiles begin to be sensed. The client oscillates between Self-energy and blending with parts.
Relational: Transference patterns crystallize and can be worked with directly. Ruptures and repairs become central therapeutic material. The client begins experiencing “undoing aloneness” (AEDP) in the therapeutic relationship.
Critical Note: This stage often feels like regression because defenses are dismantled faster than new capacities consolidate. Generated sessions reflect this upheaval—the client needs reassurance that turmoil signals progress, not failure.
22.1.1.4 Stage 3 Dimensional Profile.
Neurobiological: The window of tolerance is substantially expanded. The client regulates their nervous system with increasing autonomy—using interoceptive awareness, grounding practices, and self-soothing without constant external co-regulation. Polyvagal flexibility allows movement between states with less stuckness.
Emotional: Core affects are accessible and metabolized rather than avoided or overwhelming. Metatherapeutic processing emerges—the client reflects on their own healing with pride, gratitude, and mourning. Shame transforms into healthy guilt and self-compassion.
Cognitive: Cognitive flexibility replaces rigidity. The client holds multiple perspectives, including seeing their own contributions to relational difficulties without collapsing into self-blame. Values clarify and guide behavior. Meaning-making integrates into coherent life narrative.
Behavioral: Adaptive behaviors consolidate into new habits. The client acts in accordance with values even when difficult. Interpersonal effectiveness improves in relationships outside therapy.
Parts/Internal Systems: Significant unburdening has occurred. Exiles are witnessed and healed. Protective parts relax their grip, trusting Self-leadership. Internal communication flows more freely.
Relational: The therapeutic relationship is internalized. The client carries the therapist’s voice, perspective, and care within them. They soothe themselves with remembered moments of attunement.
Existential: Authentic living emerges. The client engages existential givens with less defense and more acceptance. Purpose and meaning are actively constructed.
22.1.1.5 Stage 4 Dimensional Profile.
Neurobiological: The nervous system demonstrates resilience. Internalized regulation capacities establish ventral vagal baseline. The client returns to equilibrium after stress without external intervention. The body feels more like home.
Emotional: The full spectrum of emotions is accessible and tolerable. Post-traumatic growth is evident—transformation through suffering, not just recovery from it. The client holds complexity: gratitude and grief, strength and vulnerability. Healing humor emerges naturally.
Cognitive: Flexible, integrated thinking is the norm. Life narrative is coherent and includes both suffering and growth. Sophisticated understanding of patterns and their development. Wisdom has been hard-won.
Behavioral: Adaptive patterns are stable. The client lives in alignment with values across contexts. Relapse prevention strategies are internalized rather than memorized.
Parts/Internal Systems: Self-leadership operates as default. Parts remain distinct but harmonious—a well-functioning inner community. Burdens have been released. Old patterns activate recognition and curiosity rather than fusion.
Relational: The therapeutic relationship completes its arc. The I-Thou quality of authentic meeting is honored in goodbye. The client has internalized the relationship as sustaining inner presence, not dependency.
Existential: The client faces the future with grounded hope. They have confronted mortality, freedom, isolation, and meaninglessness and forged their own answers. Meaning is actively created through values and relationships.
The Ending Itself: Loss is held with dignity. The bittersweet quality honors what was real. The door remains open without fostering dependency. The client leaves knowing they did this work—the therapist was midwife to their own transformation.
22.1.1.6 Curriculum Implications of Dimensional Staging.
This seven-dimensional approach ensures that generated sessions teach not just “what therapy sounds like at different stages” but what clients are like across the full complexity of human functioning at each stage. A model trained on this data learns to recognize:
How neurobiological dysregulation manifests differently than emotional dysregulation
How cognitive rigidity in Stage 1 differs qualitatively from the cognitive flexibility of Stage 3
How parts dynamics shift from protective dominance to Self-leadership
How the therapeutic relationship transforms from co-regulation source to internalized presence
How existential engagement deepens from unconscious defense to active meaning-making
The dimensional structure provides the architecture for multi-channel learning—the model can develop separate but integrated competencies for recognizing and responding to neurobiological, emotional, cognitive, behavioral, parts-based, relational, and existential material, while understanding how these dimensions interact and transform together across treatment.
These four stages function not as labels but as gating mechanisms that systematically modulate over 140 generation elements across a three-layer conditioning architecture. At the variable level, 88 core client profile variables spanning 14 categories—emotional regulation, defensive and adaptive humor, cognitive processing, coping patterns, trust orientation, polyvagal arousal, attachment dynamics, and more—each receive stage-appropriate numerical ranges: a Stage 1 client presents with high dysregulation (5–10), polarized trust (0–2 or 8–10), dominant defensive humor (5–10), and minimal mentalization (0–3), while the same underlying character at Stage 4 shows integrated regulation (0–1), balanced trust (4–8), healing humor (6–10), and robust mentalization (9–10). At the architectural level, 10+ major configuration dictionaries use stage as their primary key to govern crescendo probabilities (emotional breakthrough shifts from 2% at Stage 1 to 75% at Stage 4), humor emergence, DMM attachment dynamics, defense mechanism selection, and content accessibility gates—determining not just parameter values but what can emerge at all: core traumatic material remains inaccessible in Stage 1, fragments surface in Stage 2, and full processing becomes possible only in Stages 3–4. At the prompt level, 16+ conditional insertion points modulate trauma accessibility, parts visibility, attachment attribution style, termination themes, and more, while Stages 3–4 force therapist quality to “GREAT” (empathy, warmth, and attunement all 7–10), preventing generation of unskilled late-stage therapeutic work. Stage probabilities are asymmetric (\(35/45/20/0\)%), reflecting clinical base rates; Stage 4 denouement requires explicit forcing and targeted generation runs to ensure adequate coverage. Across six dimensions of human suffering—neurobiological, emotional, cognitive, behavioral, existential/spiritual, and systemic—this comprehensive staging ensures the model learns therapeutic arc not from labels alone but from the entire texture of how sessions differ in structure, content, and clinical possibility at each point in the course of treatment.
22.2 The Cross-Theoretical Pattern Recognition Hypothesis
The central theoretical innovation is the hypothesis that a model trained comprehensively across all theoretical domains will discover cross-theoretical intervention patterns and diagnostic overlaps invisible to human clinicians constrained by single-modality expertise.
The goal is not merely human-level clinical pattern recognition but superhuman clustering capacity: the ability to simultaneously achieve more expansive categorizations (recognizing deep structural similarities across presentations that human taxonomies treat as distinct) and more precise categorizations (distinguishing meaningfully different presentations that human taxonomies collapse into single diagnoses). Where human cognition forces a tradeoff between breadth and precision, computational scale may transcend it.
This hypothesis rests on three premises:
Shared Mechanisms Across Modalities: Superficially distinct interventions (e.g., ACT defusion, IFS unburdening, psychodynamic interpretation, somatic pendulation) target shared underlying processes through different phenomenological entry points.
Emergent Pattern Recognition: A sufficiently well-trained model exposed to all theoretical frameworks simultaneously will detect statistical regularities in assessment-intervention mappings that transcend any single modality’s conceptual vocabulary—analogous to how multilingual models discover shared semantic structures across languages.
Superiority of Integration Over Specialization: A polytheoretically integrated model will outperform modality-specific models by accessing richer intervention repertoires, recognizing when clients’ problems span multiple domains, and avoiding theoretical blind spots.
22.3 Transdiagnostic Clustering Potentials
22.3.1 The Sweet Blossoms of Sutton’s Bitter Lesson
Rich Sutton’s “Bitter Lesson” observes that general methods leveraging computation scale outperform hand-crafted domain knowledge. The sweet blossoms of this nourishing bitter root emerge when scale enables discovery of patterns that no single theoretical framework could articulate—when the learner finds structure that transcends the vocabulary of any single human teacher. At this frontier, the goal shifts from controlling what the model learns through ever-finer specification to nourishing it with what it needs to harvest understanding that extends human expertise.
In therapeutic AI, this manifests as transdiagnostic clustering: the emergence of assessment-intervention regularities that span diagnostic categories when a sufficiently capable model trains on polytheoretical data at scale. The fullest realization of this potential awaits multimodal integration—affect-laden audio, embodied video, physiological signals—where the learner can discover patterns that text alone cannot capture.
22.3.2 Theoretical Basis
Clinical psychology increasingly recognizes that DSM diagnostic categories carve nature poorly. Depression, anxiety, trauma-related disorders, and personality pathology share underlying mechanisms:
Emotional dysregulation manifests across anxiety, depression, borderline pathology, and trauma
Experiential avoidance appears in substance use, anxiety disorders, and depression
Attachment insecurity underlies relationship difficulties across personality disorders, depression, and trauma
Cognitive rigidity characterizes OCD, anorexia, and depression
A model exposed to diverse therapeutic frameworks addressing these presentations learns not “depression interventions” and “anxiety interventions” but mechanism-targeted interventions that transfer across presentations sharing underlying processes.
22.3.3 Scale-Enabled Pattern Discovery
With sufficient scale, three types of emergent clustering become possible:
Assessment Clustering: Similar client presentations cluster together across diagnostic labels. A model learns that “emotional shutdown following interpersonal conflict” (observed in depression, trauma, and avoidant personality) shares response patterns regardless of diagnosis.
Intervention Clustering: Effective interventions for similar mechanisms cluster together across theoretical frameworks. “Defusion” (ACT), “unburdening” (IFS), and “interpretation of defense” (psychodynamic) may cluster as variants of a shared “creating space from automatic reactions” mechanism.
Timing Clustering: The model discovers that certain intervention types work better at certain treatment stages, independent of theoretical framework—a meta-pattern about when any modality’s deepening work becomes appropriate.
22.3.4 Emergent Phenomenological Naming: Empirical Evidence
Early evidence from our generation pipeline suggests that models exposed to polytheoretical training data spontaneously develop novel phenomenological vocabularies—naming patterns in client presentations that transcend any single theoretical framework’s terminology. Consider the following excerpt from a generated session recap, where the model has created and tracked its own diagnostic constructs:
Probable Issues Tracked:
Cage bar perception syndrome (tally: 8): “Client’s language of ‘cage bars’ and ‘traps’ suggests a deeply embedded belief that vulnerability leads to entrapment or exploitation. His question ‘what’s the point of talking’ reveals a core belief that relational openness is dangerous and ultimately futile.”
Three in the morning mind (tally: 10): “The three-in-the-morning mind is starting to spin up—what if he’s manipulating you, what if this is all a setup, what if he tells you it’s safe and then uses it against you later.”
Sword thrusting pattern (tally: 10): “That’s the sword thrust—go on the offensive before he can hurt me... Strike first, or at least keep your guard up so they can’t land a clean hit.”
Armor thickening syndrome (tally: 6): “Something almost like relief flickering across his face before the familiar armor slides back into place.”
Modality-Specific Insights Generated:
Mistaking the map for the territory: “After directly experiencing ‘heavy, like something pressing down,’ immediately abandons the felt territory to debate conceptual maps: ‘is it possible I’m doing exactly what she says I’m doing?’ Leaves the direct experience for the story about the experience.”
The pace of unfolding: “Body reveals ‘heavy, like something pressing down’—a genuine opening—but mind rushes to resolve/explain/judge it within same breath rather than letting the revelation breathe and deepen.”
Living in the gap: “Experiencing the painful distance between the relationship as it is and the relationship as it should be, the gap between presence and true connection.”
Avoiding the tender truth by dispersing responsibility: “After acknowledging heaviness in chest, immediately disperses: ‘But I don’t know if that’s about her or about...’ Dilutes own experience by redistributing responsibility.”
These constructs—cage bar perception syndrome, three in the morning mind, sword thrusting pattern—are not terms from any established therapeutic lexicon. They represent the model’s emergent phenomenological vocabulary: novel names for clinically recognizable patterns that integrate observations across cognitive (rumination patterns), somatic (armor/tension), relational (defensive attack/withdrawal), and temporal (middle-of-the-night anxiety) dimensions.
This phenomenon demonstrates several key properties:
Cross-Framework Synthesis: The generated constructs blend insights from multiple modalities—polyvagal arousal states, attachment defenses, cognitive patterns, and somatic experiencing—into unified phenomenological descriptions.
Clinically Resonant Naming: Despite being novel, terms like “three in the morning mind” and “living in the gap” capture experiential realities that clinicians immediately recognize, suggesting the model has discovered genuine regularities rather than arbitrary labelings.
Tally-Based Tracking: The model maintains running counts of pattern occurrences with evidential grounding, demonstrating not just pattern recognition but longitudinal clinical tracking.
Evidentiary Precision: Each construct is anchored to specific client utterances and internal states, showing the model grounds its phenomenological naming in observable data rather than abstract categorization.
This emergent naming behavior exemplifies the “sweet blossoms” of scaled polytheoretical training: the model discovers clinically meaningful patterns that transcend the vocabulary of any single human-designed framework, potentially offering novel windows into client experience that complement rather than replace established theoretical constructs.
22.3.5 From Integration to Emergence: Curriculum Design for Polytheoretic Generation
The emergent constructs described above raise a foundational question: why does polytheoretical training produce novel clinical reasoning rather than mere reproduction of its constituent modalities? This subsection articulates the curriculum design mechanism responsible for this phenomenon and presents preliminary inference-time evidence that the resulting model generates polytheoretical output—clinical reasoning that arises from a merged representational space rather than from combining identifiable monomodal components.
22.3.5.1 The Dual-Signal Curriculum.
The training data presents two complementary signal types that jointly shape the model’s clinical reasoning space:
Structured monomodal exemplars. Clinically validated frameworks—ACT, IFS, AEDP, psychodynamic therapy, structural dissociation, sensorimotor psychotherapy, and others from the 23-modality inventory—provide rigorous assessment-intervention mappings with precise therapeutic vocabularies. These establish the model’s grounding in evidence-based clinical reasoning: what constitutes a valid assessment, what interventions follow from it, and what the expected therapeutic arc looks like within each framework. They anchor the model’s output to established clinical standards.
Irregular therapeutic voices. Sources drawn from contemplative, poetic, and philosophically oriented traditions—the Contemplative Presence Framework, the Dialogical Encounter Framework, and literary-therapeutic voices that perform genuine therapeutic work through non-clinical phenomenological language—demonstrate that valid therapeutic insight can originate outside formal clinical taxonomy. These sources do not map to codified intervention protocols, yet they capture experiential realities (paradox, surrender, authentic encounter, the space between knowing and being) that clinicians recognize as therapeutically meaningful.
Critically, these two signal types are not presented as separate curricula. They co-occur within the same training distribution, often within the same session’s chain-of-thought reasoning (\(\Theta^T\)). The therapist’s internal deliberation may draw on a psychodynamic formulation of defense function and a contemplative recognition of the client’s relationship to uncertainty—not as sequential modality switches but as simultaneous lenses on the same clinical moment.
22.3.5.2 Novel Constructs as Inter-Modal Training Signal.
The generation pipeline employs large language models to extract assessment and intervention constructs that do not belong to any single established framework. These appear in the therapist chain-of-thought as phenomenologically grounded formulations—for example, emotional_dismissiveness_recreating_attachment_pattern, simultaneous_contradictory_motivations_pattern, or state_change_recognition as an intervention class. Each construct is paired with specific client presentation data: observable behaviors, utterances, and relational dynamics that the construct describes.
These novel constructs serve a precise function in the curriculum’s geometry. If established modalities occupy well-defined regions in the model’s latent clinical reasoning space, novel constructs provide training signal between those regions. They demonstrate that the inter-modal space is therapeutically valid—that clinical reasoning can operate in territory that no single school has charted, provided it remains grounded in observable client phenomenology. Without these inter-modal exemplars, the model would learn that valid clinical output must map to a named framework. With them, the model learns that the space of valid clinical reasoning extends continuously across and between established modalities.
This is analogous to how data augmentation in vision models improves generalization by providing training signal between natural image clusters. Here, the “augmented” samples are not corrupted data but genuinely novel clinical formulations that occupy the interpolation space between frameworks.
22.3.5.3 Mechanism: Representational Merging, Not Modality Switching.
The dual-signal curriculum produces a specific representational outcome. Standard multi-modal clinical training—exposing a model to \(N\) distinct frameworks sequentially or in separate data streams—would create \(N\) well-separated clusters in the model’s latent space, each corresponding to a single modality’s assessment-intervention vocabulary. At inference time, such a model would classify a client presentation and route to the corresponding cluster, producing output that is recognizably integrative: a deliberate combination of identifiable monomodal components.
Our curriculum’s inclusion of novel inter-modal constructs in the chain-of-thought, combined with the co-occurrence of structured and irregular voices within the same training examples, prevents this clean separation. The model cannot maintain \(N\) discrete clusters when the training data contains exemplars that span boundaries between them. Instead, the modalities merge into a continuous representational manifold where clinical reasoning can be generated at any point—including points that correspond to no named framework.
The result is a distinction we term polytheoretical generation as opposed to integrative combination:
Integrative: The model identifies that a client presentation calls for elements of IFS (parts work), somatic therapy (body awareness), and attachment theory (relational repair), then combines recognizable components from each. The output is a mosaic of identifiable pieces. A clinician could label which sentence came from which school.
Polytheoretic: The model generates clinical reasoning from a merged representation that is informed by all training modalities but constrained by none. The output may resemble IFS or structural dissociation or sensorimotor psychotherapy depending on which region of the manifold the client presentation activates, but it does not declare its framework of origin, and individual sentences may not map cleanly to any single school. The clinical reasoning is contextually generated rather than compositionally assembled.
22.3.5.4 Two Essential Aspects of Polytheoretic Alignment.
Critically, polytheoretical alignment as we conceive it does not choose between these modes—it requires both. The integrative and the generative are two essential, complementary aspects of the same capacity:
Integrative capacity: The model deploys constructs sourced from established therapeutic frameworks fluently, without naming or declaring the framework of origin. A clinician reviewing the output can identify the traditions being drawn upon (IFS parts language, psychodynamic defense analysis, attachment-based relational provision), but the model itself does not flag these transitions. This demonstrates that the training curriculum has been internalized deeply enough that framework knowledge operates implicitly rather than declaratively.
Generative capacity: The model produces novel constructs—assessment labels, intervention names, phenomenological descriptions—that do not exist in any standard clinical framework. These are not retrieval errors or hallucinations; they name recognizable clinical phenomena that fall in the gaps between established traditions, where no existing school has provided adequate language. This is the capacity to discover new ways to think about and name psychosocial and cultural distresses that clients experience but that existing frameworks struggle to articulate with sufficient nuance.
A model that exhibits only integrative capacity could be dismissed as sophisticated retrieval—surfacing and recombining what was already in the training data. A model that exhibits only generative capacity could be dismissed as confabulation. The co-occurrence of both, grounded in observable client phenomenology, is the signature we seek: clinical reasoning that is simultaneously anchored to established therapeutic knowledge and capable of extending beyond it.
22.3.5.5 How the Curriculum Breeds Constructive Generation.
The training data does not teach the model a lookup table approach to canonical assessment and intervention only. It teaches a multi-framework clinical vocabulary plus the capacity to create its own conceptual understanding of client symptomatology. This is accomplished through a process that operates both implicitly and explicitly across the training signal.
The therapist chain-of-thought in the training data demonstrates clinical reasoning that works as follows: the therapist observes patterned client behavior—veridical, situated in a treatment stage, embedded in relational context that shifts over time—and then constructs a formulation. That formulation draws on established frameworks when they fit: IFS parts language for what presents as parts conflict, attachment theory for what presents as relational disruption. This is the integrative capacity in action. But the reasoning does not stop at framework retrieval. When the client’s patterned behavior falls between or beyond what any canonical framework names, the reasoning constructs a new conceptualization to capture it—“hostile wit preparation,” “reality blinks pattern,” “toxic shame as inner critic affect.” These are not retrieved from a clinical lexicon. They are built: constructed at the intersection of what the therapist observes in the client and the clinical reasoning apparatus the therapist brings to that observation.
This constructive-generative capacity is intentionally cultivated through the curriculum’s irregular sources. The researcher extracted clinical assessment and intervention constructs from non-clinical voices—contemplative, literary, and philosophically oriented sources—through a creative process analogous to the one the model is being trained to perform: generating clinical formulations from perspectives that genuinely offer therapeutic insight when framed in clinical terms, but that have not previously been articulated within any established clinical taxonomy. Because these constructs are not extant until the model encounters them in training, the experience is of a never-before-seen process of assessment and intervention—one grounded in patterns that present as natural phenomena of human distress, but named through language that no prior framework has provided. The model learns to recreate this constructive process both implicitly (through the patterns in how clinical reasoning engages client presentation) and explicitly (through the novel constructs that appear in the therapist chain-of-thought).
Critically, both sides of the constructive intersection are present across all training samples, not isolated to any single curriculum component. Patterned client behavior—structured, clinically meaningful, carrying signal in its own right—and patterned therapist behavior—powerful clinical reasoning deeply aligned with traditions of rigor and research—co-occur throughout the training distribution. The constructive-generative process happens where they meet: clinical reasoning engaging patterned client presentation and producing construct conceptualizations that name what is being observed with specificity that existing frameworks have not provided. Neither side is deficient alone; client behavior is patterned presentation, not raw description, and clinical reasoning is rigorous, not confabulation. But the constructive process—the building of new clinical language—emerges specifically at their meeting point.
This pattern is recursive across the training data. The model encounters construct-generation happening again and again across different clients, different treatment stages, different relational contexts—and always in tandem with canonical unimodal and integrative constructs. Both modes co-occur: established framework application alongside constructively generative formulation. The model does not learn a single novel construct; it learns that constructive generation is part of what clinical reasoning does. The capacity becomes general.
This is the specific rationale for including irregular therapeutic voices alongside structured monomodal exemplars. The structured exemplars build integrative capacity: fluent, implicit deployment of established clinical frameworks. The irregular voices—by demonstrating that valid therapeutic insight can originate outside historically named clinical taxonomy—give the model permission, in the form of training signal, to generate at the edges of established knowledge. Together, they teach a clinical reasoning process that is simultaneously anchored to the best of existing therapeutic traditions and capable of extending beyond them when the client’s experience demands language that those traditions have not yet provided.
22.3.5.6 An Aspirational Hypothesis.
We wish to be transparent that this framing is aspirational. The claim that our curriculum produces genuine polytheoretical alignment—both integrative and generative—is a hypothesis to be tested, not a demonstrated result. The preliminary deployment observations presented below are suggestive but uncontrolled. It remains possible that sufficiently capable base models already exhibit these capacities without fine-tuning, in which case our contribution would be limited to formatting and structuring output rather than developing novel clinical reasoning. Distinguishing between these explanations requires controlled evaluation: comparing base model output against fine-tuned model output on identical clinical stimuli, with blinded expert rating of both integrative quality (framework identification) and generative quality (construct novelty and clinical validity). The evaluation protocol described in Section 22.1 is designed to make precisely this distinction, and we commit to reporting the results honestly regardless of whether they support or undermine the polytheoretical generation hypothesis.
22.3.5.7 Training Convergence Across Architectures and Curricula.
Figure 17 presents normalized validation loss curves for five training runs spanning three model architectures and two curriculum conditions. All curves are expressed as percent change from each run’s first comparable measurement, removing tokenizer and model-scale bias so that convergence shape can be compared directly.
Two patterns are immediately visible. First, the Pure RRA curriculum (solid lines) produces clean, monotonic descent on every architecture that received it: both MiniMax 229B (Icarus 7.10) and GLM-4.7-Flash 30B MoE (Icarus 7.11) converge smoothly to \(-6.8\%\) and \(-8.2\%\) respectively within 900 steps. The learning is fast, low-variance, and architecturally robust. Second, the full RRA+ADWC+UHD curriculum (remaining curves) produces markedly divergent outcomes depending on model capacity: MiniMax 229B (Icarus 7.9.3) eventually reaches the same \(-6.8\%\) improvement but requires 2,900 steps of noisy, spike-laden descent to get there; Gemma 3 27B (Icarus 7.9.5) descends to \(-9.0\%\) with extreme variance (42% of step-to-step intervals show upward spikes); and GLM-4.7-Flash 30B MoE (Icarus 7.11.2) barely moves at all, plateauing at \(-1.2\%\) over 700 steps before training was stopped.
The counterintuitive finding is that the smoothest, fastest-converging runs did not produce the strongest clinical output at inference time. Subject matter expert (SME) appraisal of blinded recaps found that the two models trained on the full ADWC+UHD curriculum—Gemma 27B and MiniMax 229B—generated the most dimensioned, multi-layered clinical reasoning, including novel constructs grounded in observable client behavior. The Pure RRA runs, despite clean convergence, produced output that felt comparatively one-dimensional: clinically competent but lacking the inter-framework synthesis that characterizes the ADWC+UHD models’ best work. Meanwhile, the GLM MoE architecture—which showed clean convergence on Pure RRA—hallucinated clinical content including fabricated suicidal ideation when trained on the full curriculum, indicating that this architecture lacks the effective capacity to process the ADWC+UHD curriculum’s complexity without confabulation.
This suggests a model capacity threshold for curriculum complexity. The ADWC+UHD curriculum’s multi-layered structure (counterfactual reasoning, multi-modal demonstrations, irregular therapeutic voices) requires sufficient model capacity to learn coherently. Models that meet this threshold—MiniMax at 229B parameters, Gemma at 27B with all parameters active via GQA—produce richer clinical reasoning despite harder, noisier training. Models below the threshold—GLM with only 4 of 64 MoE experts active per token, yielding roughly 2B effective parameters per forward pass—cannot absorb the curriculum’s complexity and either plateau (on ADWC+UHD) or learn only the surface pattern (on Pure RRA, with persistent hallucination). The turgid learning curve, in this context, is not a sign of failure but of genuine engagement with difficult material.
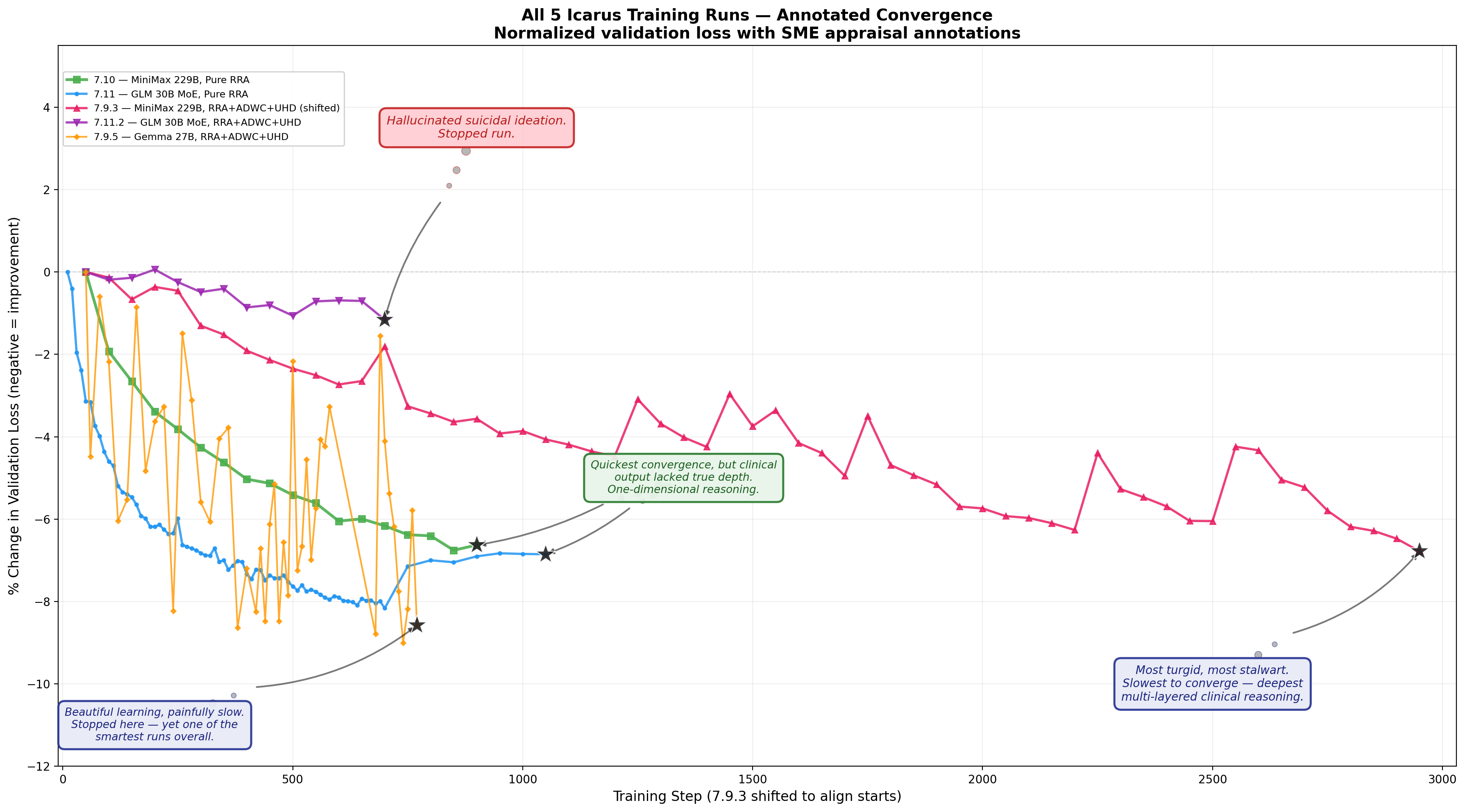
22.3.5.8 Preliminary Inference-Time Evidence.
Early inference testing of Icarus 7.9.3—a MiniMax-based model fine-tuned with rank-32 LoRA adapters on the full RRA+ADWC+UHD curriculum—provides preliminary evidence consistent with polytheoretical generation. During voice pipeline evaluation, the model spontaneously generated extended therapeutic dialogue (playing both therapist and client roles due to a pipeline configuration artifact) that exhibited the following properties:
Context-dependent modality expression without declaration. When presented with a client experiencing intellectualized hypervigilance rooted in institutional trauma, the model generated parts work that closely resembled IFS protocol—identifying a protective part, understanding its function, facilitating Self-to-part dialogue, and guiding toward unburdening. When presented with a different client experiencing somatic holding patterns from a caretaker-sacrifice role, the model generated parts work that instead resembled structural dissociation theory—body-located, functionally named (“the altar part”), with emphasis on annihilation fear and identity fusion. In neither case did the model’s chain-of-thought name the modality it was drawing from. The clinical architecture shifted to match the presentation.
Simultaneous multi-framework operation. Within single therapeutic turns, the model integrated psychodynamic defense analysis (understanding why a protective part exists), somatic co-regulation (therapist’s own body as anchor, tracking postural shifts), attachment-based relational provision (“we’ll do this together”), compassion-focused reorientation (from self-attack to self-care), and experiential engagement (in-session direct dialogue with the part)—not as sequential interventions but as simultaneous dimensions of a single clinical act.
Novel construct generation in clinical formulation. The model produced assessment formulations such as
emotional_dismissiveness_recreating_attachment_patternand intervention directives such as “Applytherapeutic_apology_and_repairif feedback ruptures, thenstate_change_recognition: ‘Notice shift to compliant mode—does this echo past adjustments?’ ” These constructs synthesize attachment theory, rupture-repair dynamics, and somatic state-tracking into unified clinical acts that do not correspond to any single training modality’s protocol.Isomorphic in-session and homework alignment. In one extended session, the model generated a take-home assignment that was structurally isomorphic to the in-session intervention: the same relational frame (Self addressing a protective part), the same phenomenological vocabulary (“let her feel you there”), the same somatic grounding (noticing bodily responses), with anticipatory scaffolding for the part’s likely resistance (“notice if you feel the urge to jump back in”). This alignment between in-session work and homework reflects a level of therapeutic coherence that requires unified clinical reasoning rather than modular combination—the homework was derived from the same representational source as the intervention, not assembled from separate components.
Generative construct creation with observational grounding across extended context. In the same session, the model’s chain-of-thought maintained coherent clinical reasoning across seven therapist turns without degradation, generating novel tracked constructs including creative inadequacy complex and nature comparison despair (self-minimization through comparison), reality_blinks_pattern (dissociative micro-switches, influenced by but not identical to Bromberg’s “reality blinks”), longing_without_words (unsymbolized affect), and shame_about_shame (recursive shame). Each construct was anchored to specific observed behaviors: a mid-sentence halt when approaching “something felt like it needed to happen,” a postural shift to the edge of the chair, a self-conscious smile that fades. Critically, the model simultaneously deployed niche theoretical frameworks—Bromberg’s relational psychoanalysis (standing in the spaces, not-me experiences), Sullivan’s dissociative categories, DMM A8 externally assembled self—while generating constructs that extend beyond any of these frameworks. The novel and the established co-occur in the same chain-of-thought, each grounding the other: established theory validates the clinical soundness of the observation, while the novel construct captures phenomenological specificity that no single established framework provides.
This is significant because the novel constructs in Sections 22.3.5.1–22.3.5.3 above were produced by the generation pipeline during data creation. These inference-time constructs were produced by the trained model during deployment—demonstrating that the capacity for grounded clinical novelty transfers through fine-tuning. The model did not merely memorize the training data’s novel constructs; it acquired the generative competency to produce its own.
These observations are preliminary and uncontrolled. The model was not evaluated in a blinded design, and the dual-role generation artifact (model playing both therapist and client) means the “client” responses are optimized for demonstrating the modality rather than simulating realistic human complexity. The seven-turn coherence finding is promising but requires systematic evaluation across sessions of varying length and complexity to establish whether context degradation occurs predictably. Formal evaluation requires the Phase 1 inference protocol described in Section 22.1, with blinded expert rating of therapeutic quality, modality identification, and construct validity. Nevertheless, the qualitative pattern is consistent with the polytheoretical generation hypothesis: the model produces contextually appropriate, multi-framework clinical reasoning without declaring or being constrained by any single school of thought—and it does so not only during data generation but after training, at inference time, with novel client presentations.
22.3.5.9 Architecture–Curriculum Interactions: An Emerging Pattern.
Ongoing training runs add a further dimension to the convergence findings above. Icarus 7.11.7—Gemma 3 27B trained on the Pure RRA curriculum alone (12,938 samples, no ADWC or UHD)—reaches a validation loss of 2.852 (perplexity 17.33) by step 150, already surpassing Icarus 7.9.5’s best result of 3.281 (perplexity 26.59) at step 740 on the full RRA+ADWC+UHD curriculum. The training loss continues to descend with no sign of plateau: block averages drop from 2.74 (steps 0–24) to 1.99 (steps 150–174). These results are preliminary—the runs use different validation sets, making absolute comparison imprecise—but the trajectory suggests that for Gemma’s architecture, Pure RRA may be a more sample-efficient curriculum than the full ADWC+UHD pipeline.
This finding is architecture-conditional. The emerging cross-architecture pattern is:
Gemma 3 27B (Multi-Head Attention): Thrives on Pure RRA; may not require ADWC+UHD to achieve strong therapeutic reasoning. Converges rapidly with low variance.
MiniMax 229B (Multi-Head Attention): Thrives on RRA+ADWC+UHD at scale, producing the richest polytheoretical output. Requires the full curriculum’s complexity to reach its deepest clinical reasoning.
GLM-4.7-Flash 30B (Multi-Latent Attention, MoE): Struggles on both Pure RRA and RRA+ADWC+UHD, with persistent hallucination including fabricated clinical content.
A candidate mechanistic explanation centers on attention architecture. Both successful models—Gemma and MiniMax—employ standard Multi-Head Attention (MHA), which retains full per-head key-value representations. GLM-4.7-Flash employs Multi-Latent Attention (MLA), which compresses the KV space through low-rank projection to reduce memory and compute costs. When RRA-based training requires tracking fine-grained therapeutic nuances across extended sessions—subtle shifts in affect, contradictions between what a client says and does, the difference between two clinically similar but therapeutically distinct presentations—MHA’s full representational fidelity may preserve precisely the near-neighbor distinctions that MLA’s compression discards.
This hypothesis remains unconfirmed. GLM’s poor performance could alternatively reflect its sparse MoE architecture (only 4 of 64 experts active per token, yielding \(\sim\)2B effective parameters), its training data distribution, or an interaction between these factors. Distinguishing the MHA/MLA explanation from the capacity explanation would require testing an MHA model at comparable scale to GLM (\(\sim\)30B parameters) or an MLA model with higher-rank projections on the same curriculum. We report the pattern and the candidate mechanism while acknowledging that the current evidence does not isolate the causal variable.
22.3.5.10 Implications for Synthetic Data Design.
If the polytheoretical generation hypothesis is correct, it has direct implications for how therapeutic training curricula should be constructed:
Include both structured and irregular sources. Curricula that present only codified clinical frameworks may produce models that can reproduce those frameworks but cannot generate beyond them. The inclusion of irregular therapeutic voices—contemplative, literary, philosophically grounded—teaches the model that therapeutic validity extends beyond clinical taxonomy. Combined with structured monomodal training that establishes what clinical rigor requires, this dual exposure creates a generative space that is both grounded and extensible.
Populate the inter-modal space explicitly. Novel constructs in the therapist chain-of-thought are not noise or hallucination—they are deliberate training signal that teaches the model to reason in the space between established frameworks. Without these exemplars, the model learns only the nodes (established modalities); with them, it learns the edges (the transitions and interpolations between modalities) as well.
Pair novel constructs with grounded client presentations. The inter-modal constructs must be anchored to specific, observable client behaviors and utterances. Ungrounded novelty would teach the model to confabulate; grounded novelty teaches it that clinical creativity is valid when it serves phenomenological accuracy. The training data must demonstrate both what novel constructs look like and what makes them clinically sound rather than arbitrary.
The distinction between integrative and polytheoretical output may prove to be the curriculum’s most consequential property. If models trained on monomodal data produce monomodal output, and models trained on multi-modal data produce integrative output, then models trained on curricula that explicitly populate the inter-modal space may produce polytheoretical output—clinical reasoning that operates from a unified representational manifold rather than combining discrete components. This is the curriculum design analog of the difference between a bilingual speaker who translates between languages and a speaker who thinks in a merged linguistic space that transcends either language alone.
22.4 Scope and Frontier: Completed Work and Next Horizons
This white paper documents completed work. The synthetic dataset described herein has been fully generated, and the Retrieval-Reflective Augmentation (RRA) pipeline has been substantially executed. The theoretical foundations, data architecture, and generation methodology presented in subsequent sections describe operational systems, not speculative designs.
The current research frontier lies elsewhere: multimodal integration. While this paper addresses text-based therapeutic dialogue, ongoing work extends the clustering hypothesis to richer data modalities:
Affective Audio: Prosodic features, voice quality markers, paralinguistic cues indicating emotional states and autonomic arousal
Affective Video: Facial affect recognition, micro-expressions, postural indicators, gesture analysis
Diarized Transcriptions: Speaker-segmented dialogue enabling turn-taking analysis, interruption patterns, and dyadic synchrony measurement
Biometric Integration: Physiological markers (heart rate variability, electrodermal activity, respiratory patterns) as direct windows into autonomic state
The multimodal frontier represents the “messy” edge of this research program—where theoretical clarity meets engineering challenges of sensor fusion, temporal alignment, and cross-modal representation learning. This paper, by contrast, presents the “clean” foundation: a completed, validated dataset and methodology upon which multimodal extensions can build.
23 Key Terms
This paper employs several terms that stake out specific positions distinct from related concepts in the literature.
23.0.0.1 Phenomenological Polysemy.
The ontological claim that therapeutic phenomena are inherently rich enough to support multiple valid theoretical readings—not because our theories are imprecise, but because the phenomena themselves are genuinely complex. When an IFS therapist sees a “protective part,” a psychodynamic therapist sees a “defense mechanism,” and an ACT therapist sees “experiential avoidance,” they are not using different words for the same thing, nor seeing completely different things. Each is getting a partial, valid reading of something whose being supports all those readings. The way therapeutic phenomena show themselves (phenomenology) reveals something about what they are (ontology): namely, that their existence is rich enough to be accurately described by multiple theoretical frameworks simultaneously. This explains why integration is possible—it is not our choice to integrate but the nature of therapeutic reality that demands it.
23.0.0.2 Polytheoretical.
An approach to therapeutic AI that is simultaneously integrative and generative. Integrative in that it coherently synthesizes insights across multiple therapeutic traditions, with explicit articulation of how frameworks relate—distinguished from eclectic approaches that borrow techniques unsystematically. Generative in that training across the full breadth of clinical traditions enables the discovery of therapeutic patterns and constructs that no single tradition contains—synthesis that produces understanding beyond the sum of its parts. Phenomenological polysemy provides the ontological grounding for why polytheoretical work is both possible and necessary: because the phenomena themselves admit multiple valid readings, a system that holds multiple lenses simultaneously perceives what any single lens must miss.
23.0.0.3 Socioaffective Alignment.
The design principle that a therapeutic AI system must be aligned not only with safety constraints and factual accuracy but with the relational, emotional, and intrapsychic dimensions of human experience. Where conventional AI alignment focuses on preventing harm and ensuring helpfulness, socioaffective alignment asks what it would mean for an AI to be with someone therapeutically—to attune, to pace, to hold silence, to stay present when staying present is hard. The framework rests on three pillars: (1) systematic therapeutic inversion of documented AI harms, (2) encoding the accumulated clinical wisdom of over a century of therapeutic practice, and (3) polytheoretical synthesis that is both integrative and generative. Socioaffective alignment is treated throughout this work as a co-primary design requirement alongside technical performance.
23.0.0.4 Transdiagnostic.
Operating across traditional DSM diagnostic categories, targeting underlying mechanisms (emotion dysregulation, cognitive rigidity, interpersonal patterns) rather than diagnosis-specific symptoms. Where phenomenological polysemy describes the multi-readable nature of therapeutic phenomena, transdiagnostic describes assessment and intervention that crosses categorical boundaries to address shared mechanisms.
23.0.0.5 Monomodal.
Therapeutic approaches operating exclusively within a single theoretical framework. This paper argues against monomodal constraints not because single frameworks are wrong, but because they are necessarily partial readings of polysemous phenomena—each capturing genuine aspects while missing others that alternative frameworks illuminate.
24 Attachment Theory Integration: The DMM Framework
24.1 Dynamic-Maturational Model Overview
The system implements Crittenden’s Dynamic-Maturational Model with 22 attachment strategies:
Type A (Avoidant): A1, A2, A3, A4, A5, A6, A7, A8
Type B (Balanced): B0, B1, B2, B3, B4, B5
Type C (Preoccupied): C1, C2, C3, C4, C5, C6, C7, C8
24.2 Odd/Even Coherence Theory
A key innovation is the implementation of DMM odd/even coherence:
Odd patterns (A1, A3, A5, A7, C1, C3, C5, C7): Inhibitory strategies emphasizing cognitive processing, affect dampening, and predictability-seeking
Even patterns (A2, A4, A6, A8, C2, C4, C6, C8): Excitatory strategies emphasizing affective processing, cognitive minimization, and arousal-based responding
This coherence principle ensures that generated clients maintain consistent defensive organizations across behavioral, emotional, and cognitive domains.
25 Clinical Ontology Architecture
25.1 Knowledge Base Structure
The system integrates a 67 MB clinical ontology comprising two complementary pipelines: (1) 45 production-ready worldview ontologies encoding therapeutic schools of thought, and (2) 28 intervention/assessment modalities with 170+ specification files. Together, these provide approximately 3,300+ elements across 12 categorical theoretical domains:
| Domain | Ontologies | Key Frameworks |
|---|---|---|
| Attachment-Based | 5 | DMM 22-subtype classification; Attachment-Based Emotional Intimacy; Psychobiological Couples Regulation |
| Trauma & Dissociation | 9 | Structural Dissociation Model; Complex PTSD Recovery; Sensorimotor Integration |
| Psychodynamic | 4 | Psychodynamic Process and Defense Analysis; Relational-Dissociative Process |
| Third-Wave CBT | 3 | Psychological Flexibility (ACT); Dialectical Synthesis (DBT); Functional Analytic Model (FAP) |
| Emotion-Focused | 2 | Accelerated Experiential Dynamic Processing; Transformational Affects |
| Positive Psychology | 3 | SPIRE Flourishing Model; Character Strengths and Virtues |
| Existential/Spiritual | 2 | Nature-Based Presence; Spiritual Resilience Through Adversity |
| Specialized Populations | 3 | Personality disorder frameworks; Shame physiology; Narcissism patterns |
| Interpers. Neurobio. | 4 | Polyvagal Nervous System Regulation; Window of tolerance; Neuroception |
| Somatic/Body-Based | 3 | Sensorimotor Body-Based Integration; Somatic shame; Grounding protocols |
| Parts/Multiplicity | 2 | Self-Leadership Model (IFS); Conglomerate Mind; Unburdening |
| TOTAL | 45 worldview + 28 intervention | 150+ assessments, 300+ interventions, 200+ mappings |
25.2 Two-Pipeline Ontology Engineering
The clinical ontology architecture employs a two-pipeline approach to knowledge engineering, distinguishing between (1) global therapeutic worldviews—the philosophical and theoretical frameworks that shape how different schools of thought conceptualize human suffering and healing—and (2) intervention/assessment specifications—the concrete clinical tools, techniques, and diagnostic frameworks that operationalize these worldviews in practice.
This distinction matters because a worldview (“attachment needs are primary”) generates different clinical actions than another worldview (“behavioral contingencies shape experience”), even when addressing similar presentations. By separating these layers, the system can generate therapeutically coherent sessions where interventions flow naturally from underlying theoretical commitments rather than appearing as arbitrary technique selection.
25.2.1 Pipeline 1: Global Therapeutic Worldviews
The first pipeline comprises 45 production-ready ontology files (\(\sim\)13.4 MB) representing distinct therapeutic schools of thought. Each ontology encodes not merely terminology but the epistemic stance of that tradition—what counts as evidence, what mechanisms drive change, and what constitutes healing.
Tier 1: Empirically-Validated Frameworks (Strong RCT evidence, excellent formalization)
Psychological Flexibility Framework (ACT): Human suffering is universal; therapy reduces experiential avoidance through values-based action. Grounded in Relational Frame Theory with 200+ RCTs supporting efficacy.
Dialectical Synthesis Framework (DBT): Acceptance and change exist in dialectical tension; distress tolerance, mindfulness, emotion regulation, and interpersonal effectiveness form integrated skill modules.
Attachment-Based Emotional Intimacy Framework (EFT): Attachment needs are primary motivational forces; emotional accessibility and responsiveness transform relationships. Manualized protocol with strong couples therapy evidence.
Functional Analytic In-Vivo Change Model (FAP): Healing occurs through therapeutic relationship contingencies; in-session behavioral analysis reveals functional relationships maintaining problematic patterns.
Tier 2: Strong Clinical Consensus (Moderate-to-strong evidence, good formalization)
Complex PTSD Recovery Framework: Trauma creates four-F responses (fight, flight, freeze, fawn); somatic awareness and developmental reparenting address six-dimensional arrested development.
Structural Dissociation Model: Trauma causes personality fragmentation into Apparently Normal Parts (ANP) and Emotional Parts (EP); integration requires sequential processing across primary, secondary, and tertiary dissociation levels.
Accelerated Experiential Dynamic Processing: Aloneness-with-overwhelming-emotion is psychological suffering’s epicenter; dyadic regulation enables transformation through metatherapeutic processing.
Polyvagal Nervous System Regulation Framework: Three evolutionary vagal pathways (dorsal, sympathetic, ventral) determine state; “story follows state”—narrative emerges from physiological regulation, not vice versa.
Psychodynamic Process and Defense Analysis: Unconscious processes shape personality; defensive structures protect against intolerable affect; honest self-knowledge reduces suffering through insight.
Tier 3: Emerging Evidence, Specialized Domains
Self-Leadership and Parts Work Model (IFS): People are naturally multiple; three-group organization (managers, exiles, firefighters) describes internal systems; Self-leadership enables unburdening.
Mentalization-Based Framework: Capacity to interpret mental states bridges self-other understanding; mentalizing failures underlie borderline pathology.
Character Strengths and Virtues Framework: 24 character strengths across 6 virtues; cultivation of signature strengths supports wellbeing and resilience.
SPIRE Model of Human Flourishing: Happiness integrates spiritual, physical, intellectual, relational, and emotional dimensions in dynamic balance.
Each worldview ontology includes: (a) core philosophical commitments, (b) theory of pathology, (c) theory of change, (d) key constructs and their relationships, and (e) characteristic therapeutic stance.
25.2.2 Pipeline 2: Intervention/Assessment Specifications
The second pipeline comprises 28 distinct therapeutic modalities with 170+ files (\(\sim\)54 MB) documenting concrete clinical tools. Unlike the worldview ontologies that describe how to think, these specifications describe what to do—assessments to administer, interventions to deploy, and the specific language and timing that characterizes skilled implementation.
Structural Innovation: Stage-Mapped Interventions
All interventions are mapped across four treatment stages, enabling stage-appropriate synthetic case generation:
Initial Connection: Building alliance, establishing safety, conducting initial assessment
Deep Exploration: Processing core material, working with defenses, addressing attachment patterns
Consolidation: Integrating gains, practicing new patterns, preparing for termination
Culmination: Reviewing progress, addressing remaining concerns, ending meaningfully
Content Specifications
Each modality ontology includes:
150+ assessment categories: Diagnostic frameworks, symptom clusters, defensive organizations, attachment patterns, readiness indicators
300+ intervention techniques: Specific therapeutic actions with implementation guidance, contraindications, and timing considerations
200+ assessment-intervention mappings: Which intervention addresses which assessment finding at which treatment stage
Extended dialogue examples: Exact therapeutic language preserving the “flavor” of each modality—not abstract descriptions but concrete utterances a skilled practitioner would actually say
Fully Structured Modalities (Complete extraction with stage mapping)
| Modality | Size | Key Content |
|---|---|---|
| Psychological Flexibility (ACT) | 7.7 MB | 41 assessment/intervention pairs, Hexaflex processes |
| Complex PTSD Recovery | 3.6 MB | 4F responses, emotional flashback protocols, developmental arrest |
| Attachment-Based Intimacy (EFT) | 2.7 MB | Cycle de-escalation, vulnerability cultivation, A.R.E. assessment |
| Relational-Dissociative Process | 1.1 MB | Enactment work, therapeutic presence, “stumbling” as technique |
| Psychodynamic Process | 1.1 MB | Defense mechanisms, transference patterns, resistance navigation |
| Self-Leadership (IFS) | 1.1 MB | Parts unburdening, manager/exile/firefighter dynamics |
| Experiential Dynamic (AEDP) | 1.3 MB | Transformation detection, dyadic regulation, metatherapeutic processing |
| Polyvagal Regulation | 324 KB | Vagal tone building, co-regulation, neuroception |
| Dialectical Synthesis (DBT) | 1.1 MB | Distress tolerance, shame-focused adaptations |
25.2.3 Cross-Framework Theoretical Tensions
A critical feature of this dual-pipeline architecture is that it preserves theoretical tensions rather than artificially harmonizing them. Different frameworks genuinely disagree about fundamental questions:
| Dimension | Behavioral Frameworks | Relational Frameworks | Somatic Frameworks |
|---|---|---|---|
| Change mechanism | Skill acquisition, contingency modification | Relationship repair, attachment security | Nervous system regulation |
| Primary focus | Present behavior and cognition | Attachment patterns, relational history | Body states, autonomic tone |
| Therapist role | Coach, teacher | Secure base, attachment figure | Co-regulator |
| Key metric | Psychological flexibility | Emotional accessibility | Ventral vagal activation |
By maintaining these distinctions, the system generates sessions where a therapist operating from the Psychological Flexibility Framework responds differently than one operating from the Attachment-Based Intimacy Framework—even to identical client presentations. This diversity in clinical reasoning is itself pedagogically valuable: it teaches models that expert disagreement exists and that multiple valid approaches may address the same concern.
Crucially, this “disagreement” reflects not contradiction but complementary partial observation. The behavioral framework’s focus on contingencies, the relational framework’s focus on attachment, and the somatic framework’s focus on nervous system state are all correct—they are measuring different projections of the same high-dimensional clinical reality. Human clinicians, constrained by training, temperament, and cognitive bandwidth, typically master one or two projections deeply. Machine learning systems, trained on the full ontological diversity documented here, can potentially integrate across these vantage points in ways that exceed human integrative capacity.
25.2.4 Citation Approach: Theoretical Frameworks over Author Attribution
For scientific clarity and to foreground theoretical contributions over personal attribution, this work cites therapeutic approaches through their theoretical framework names rather than originator names. A mapping key documents these correspondences:
Complex PTSD Recovery Framework (rather than Walker’s model)
Attachment-Based Emotional Intimacy Framework (rather than Johnson’s EFT)
Polyvagal Nervous System Regulation Framework (rather than Porges/Dana’s approach)
Structural Dissociation Model (rather than van der Hart/Nijenhuis framework)
Relational-Dissociative Process Framework (rather than Bromberg’s approach)
This approach emphasizes theoretical contributions while maintaining full bibliographic attribution in references.
25.2.5 Acknowledged Limitations
The ontology architecture, while comprehensive, has identifiable gaps that represent opportunities for future work:
Underrepresented populations: Limited child/adolescent-specific adaptations; minimal neurodiversity-informed frameworks (autism, ADHD)
Cultural scope: Underrepresentation of non-Western therapeutic traditions; limited cross-cultural psychiatry integration
Integration domains: Minimal psychopharmacology interface; limited group/family systems coverage
Extraction completeness: Some modalities partially extracted; couples therapy over-represented relative to individual therapy
These limitations are documented transparently, and the modular architecture enables targeted expansion as additional ontologies are developed.
25.2.6 Knowledge Extraction Methodology
The therapeutic ontologies were constructed through a multi-layered extraction and transformation process designed to capture clinical wisdom while enabling computational use:
Primary Source Analysis: Published works, training materials, and documented clinical frameworks from established therapeutic traditions served as source material. The theoretical frameworks, their core constructs, assessment approaches, and intervention techniques were identified and catalogued.
Scripted Extraction Pipelines: Multiple extraction scripts (Python-based) were developed to systematically process source materials, identifying assessment categories, intervention techniques, stage-specific adaptations, and cross-framework connections. These scripts employed both rule-based parsing and pattern matching to extract structured information.
LLM-Assisted Transformation: Large language models were employed to transform extracted content into structured ontological formats—converting narrative clinical descriptions into formalized assessment-intervention mappings, generating stage-specific manifestation variants, and creating coherent intervention arc sequences. This transformation preserved the semantic content while enabling computational access.
Iterative Refinement: Multiple extraction iterations (visible in version-controlled development) progressively improved ontology completeness, coherence, and clinical accuracy. Earlier extractions informed later improvements through accumulated learning about what information structures best served downstream generation.
Subject Matter Expert Validation: Extracted ontologies were reviewed for clinical validity, ensuring that the formalized representations faithfully captured the therapeutic wisdom of their source frameworks. Where divergence from primary sources occurred through transformation, the guiding principle was preservation of healing approaches’ essential character rather than literal transcription.
Note on Fidelity: This extraction methodology necessarily involves interpretation and transformation. The resulting ontologies represent our best effort to operationalize clinical wisdom for computational use, not verbatim reproductions of source material. In some cases, there may be divergence from primary source formulations while preserving faithfulness to the underlying healing approaches that have demonstrated clinical value. Full bibliographic attribution to the originating theorists and clinicians whose work informed these ontologies is provided in the references.
[STILL PENDING RESEARCH CONFIRMATION] Note on Non-Clinical Source Integration: Alongside canonical therapeutic frameworks, a subset of our ontologies draws upon texts from humanistic, poetic, and philosophical traditions that are not themselves clinical in origin—works of human wisdom that we transformed into clinical structures through the extraction methodology described above. We include these for two reasons. First, they bring genuinely meaningful ideas—beloved across traditions of human thought—into the therapeutic training signal, enriching the model’s capacity for creative, resonant engagement. Second, they present unique modes of thinking about human experience that canonical therapeutic schools do not provide, offering the model novel epistemic pathways for meeting users’ presentations. Our mechanistic interpretability work (reported separately) demonstrates that canonical therapeutic frameworks are already embedded in the base model’s representations across layers, and that our training enhances and deepens the meaning of these pre-existing structures—much as reinforcement learning refines latent capacities. Through the same probing methods, we observe that non-canonical ontological insertions operate differently: because they lack pre-existing representational grounding in the base model, they function as genuinely novel epistemic contributions, training the model to name and reason with concepts it could not previously access. Our provenance studies confirm that these insertions produce actionable impacts on how the model functions—both epistemically, in its capacity to recognize and articulate novel patterns, and phenomenologically, in the latent and explicit clinical patterns that emerge in inference. The humanistic and poetic traditions from which these ontologies are drawn have their own deep histories of attending to human suffering and flourishing; our claim is not that we have invented new therapeutic modalities but that we have found ways to render these traditions of human wisdom computationally legible as clinical structures.
25.2.7 Ontology Integration Points
These therapeutic ontologies serve as living knowledge repositories that inform generation at two critical points in the pipeline—both detailed in subsequent sections:
Therapist Chain-of-Thought Generation (Section 7.3): During the OMO (Ontologically-guided Modality Orientation) phase of therapist reasoning, ontologies provide the theoretical framework guidance that shapes intervention selection. The therapist’s internal deliberation explicitly draws upon modality-specific worldviews, assessment categories, and intervention techniques encoded in these ontologies. This ensures that generated therapist reasoning reflects genuine theoretical grounding rather than generic therapeutic platitudes.
Counterfactual Generation and Educational Divergence (Appendix 28): Post-session pedagogical expansion uses ontologies to generate alternative therapeutic approaches—demonstrating how different theoretical orientations might conceptualize and respond to the same clinical moment. This creates educational contrast that illuminates the distinctive contributions of each framework, preparing training data that teaches not just “what to do” but “why this approach from this perspective.”
This dual integration ensures that the substantial investment in ontology engineering propagates throughout the generation pipeline, creating coherence between therapeutic worldview, in-session reasoning, and post-hoc educational reflection.
25.2.8 Ontologies as Foundation for Multimodal Frontiers
The ontological architecture described in this section represents completed foundational work—a stable platform upon which future research directions can build. While this paper documents the text-based synthetic data generation pipeline, the research frontier has advanced toward multimodal integration across four emerging data streams:
Affective Audio: Prosodic markers, vocal tremor, breath patterns, paralinguistic cues encoding emotional states inaccessible through transcript alone
Affective Video: Facial micro-expressions, postural shifts, gestural patterns, gaze dynamics revealing moment-to-moment affective regulation
Diarized Transcriptions: Speaker-attributed text with precise temporal alignment enabling turn-taking analysis, interruption patterns, and silence characterization
Biometric Streams: Heart rate variability, galvanic skin response, respiratory patterns providing direct physiological windows into autonomic regulation
The therapeutic ontologies documented here provide the interpretive scaffolding necessary for multimodal integration. When a Polyvagal ontology specifies that “dorsal vagal shutdown manifests as flat affect, monotone voice, and collapsed posture,” it creates bridges between text-based clinical reasoning and the audiovisual-biometric signals that would confirm or disconfirm such hypotheses in multimodal data.
Positioning: This white paper documents the completed text-based pre-training data pipeline. The multimodal frontier—integrating affective audio/video, diarized transcription, and biometric data with the ontological frameworks described here—represents active research extending beyond this paper’s scope. The ontological investment documented in this section thus serves dual purposes: enabling the text-based generation pipeline presented here, and providing semantic grounding for the multimodal integration work that follows.
25.3 Multi-Vantage-Point Clinical Reasoning Pedagogy
A key innovation is the explicit encoding of clinical reasoning processes from multiple vantage points—teaching models not just what therapists say, but how they think:
Therapist perspective: What clinical observations inform intervention selection? What attachment patterns are being noticed? What is the felt sense of the relational field?
Client perspective: What internal experience drives utterances? What defenses are activating? What attachment strategy is being expressed?
Dyadic perspective: How does attunement manifest? When do ruptures occur? What marks successful repair?
This multi-vantage-point approach mirrors how human clinicians develop expertise—through exposure to both behavioral patterns and the reasoning processes that generate skilled responses.
25.4 TMOC Architecture
The Therapist Model of Client (TMOC) provides evidence-based tracking:
Provenance tracking for clinical observations
Stage-appropriate hypothesis generation
Intervention selection guidance
Progress monitoring across sessions
26 Combinatorial Analysis
26.1 Layer 1: Micro-Variable Space
\[\begin{equation} M = \prod_{i=1}^{14} m_i = 36 \times 34 \times 24 \times 32 \times 24 \times 10 \times 8 \times 12 \times 6 \times 10 \times 8 \times 8 \times 8 \times 6 \approx 5.026 \times 10^{17} \end{equation}\]
26.2 Layer 2: Client Profile Space
Conservative estimate across 156+ attributes: \[\begin{equation} P > 10^{25} \end{equation}\]
26.3 Layer 3: Stage-Gated Variations
\[\begin{equation} S = 4 \text{ stages} \times 480 \text{ manifestations} \times \text{weighted access} \approx 7,680 \end{equation}\]
26.4 Layer 4: External Knowledge Integration
From CSV files: 13,801 data points providing contextual weighting.
26.5 Total Combinatorial Space
\[\begin{equation} \boxed{T = M \times P \times S \times K > 10^{40} \text{ unique therapeutic personhoods}} \end{equation}\] Note: This is LLM math, about which the first author is suspicious; what is verifiably true is that orders of magnitudes of expansions and connections are enabled by our carefully constructed synthetic data creation scripts and pipelines.
For perspective:
Atoms in observable universe: \(\sim 10^{80}\)
Earth’s population: \(\sim 10^{10}\)
Unique personhoods per human if distributed: \(10^{30}\)
27 Therapist Profile Generation
Just as client profiles determine presentation, therapist profiles shape the quality, style, and theoretical grounding of therapeutic responses. The system generates diverse therapist personas to expose the model to varied but coherent therapeutic approaches.
27.1 Therapist Persona Dimensions
Each therapist profile specifies values across five core dimensions:
Theoretical Orientation: Primary therapeutic framework(s)
Single-modality: Pure ACT, psychodynamic, somatic, etc.
Integrative: Specified blend (e.g., “relational-somatic,” “ACT-informed psychodynamic”)
Eclectic: Responsive to client needs without fixed framework
Experience Level: Years of practice and developmental stage
Novice (0–2 years): Technique-focused, follows protocols closely, less improvisational
Intermediate (3–7 years): Growing flexibility, developing personal style
Expert (8+ years): Fluid, responsive, protocol-transcendent while theory-grounded
Warmth Parameter (\(w \in [0,1]\)): Relational style
Low warmth (\(w < 0.3\)): More neutral, classical analytic stance
Moderate warmth (\(0.3 \le w < 0.7\)): Balanced professional warmth
High warmth (\(w \ge 0.7\)): Explicitly caring, relationally engaged
Therapeutic Ambition (\(a \in [0,1]\)): Intervention intensity
Low ambition (\(a < 0.3\)): Presence-focused, follows client lead, minimal interpretation
Moderate ambition (\(0.3 \le a < 0.7\)): Balanced active-receptive stance
High ambition (\(a \ge 0.7\)): More interpretive, intervention-forward (with warnings about misuse)
Specialty Areas: Particular clinical expertise
Trauma, attachment, couples, somatic, dissociation, personality disorders
Affects which ontology resources are preferentially accessed
27.2 Profile-Client Interaction Dynamics
Therapist profiles interact with client profiles to shape session generation:
| Therapist Trait | Client Trait | Interaction Effect |
|---|---|---|
| High warmth | Avoidant attachment | Gentle approach, respects distance, models safety without pressure |
| Low warmth | Preoccupied attachment | May trigger abandonment fears; system can model repair |
| High ambition | Fragile defenses | Risk of overwhelming; pacing guidance activated |
| Somatic orientation | High body awareness | Rich somatic exploration emerges naturally |
| Novice therapist | Complex presentation | Models realistic learning challenges, supervision needs |
27.3 Pedagogical Value of Therapist Diversity
Training on diverse therapist profiles serves multiple pedagogical functions:
Style Flexibility: Model learns that effective therapy can look different with different therapists
Mistake Modeling: Lower-skill therapists make realistic errors, enabling learning from both success and failure
Match Effects: Model learns that certain therapist-client combinations work better than others
Ambition Calibration: Model learns the dangers of excessive therapeutic ambition and the healing power of simple presence
The core principle underlying therapist profile design is captured in a prompt instruction that appears across all generation: “Rapport is not a means to intervention—rapport IS the intervention.” This grounds all generated sessions in the primacy of relationship over technique.
27.4 Dual-Purpose Data: DAPT and Instruct Fine-Tuning Extraction
A key insight driving our curriculum design is the complementary pedagogical functions of raw sessions versus counterfactual expansions:
Raw Session Therapist: Embodies the broad overview of clinician presence—loving, brilliant, attuned—modeling the fundamental relational quality that defines effective therapy. These sessions teach the essence of therapeutic being.
Counterfactual Therapist: Generates more explicitly artful and aesthetic therapeutic presence—the specific micro-decisions, the precise intervention timing, the deliberate theoretical reasoning made visible. These sessions teach the craft of therapeutic doing.
While both remain DAPT (Domain-Adaptive Pre-Training) data, the counterfactual samples can additionally be extracted for Instruct Fine-Tuning—creating explicit instruction-following examples that train the model on “how to think like a therapist” with greater pedagogical clarity than raw sessions provide.
27.4.1 Curriculum Design Philosophy: Respecting Model Dignity
Our layer-targeted training approach reflects a philosophical commitment: we respect and trust the dignity and intelligence of the model’s baseline. Rather than overwriting the foundation model’s capabilities, we aim to artfully augment very specific aspects of understanding:
Middle Third Layers (DAPT): Trained with rank-32 LoRA across all 7 modules (Q, K, V, O, gate, up, down projections). This configuration targets conceptual understanding—building the model’s internal representations of therapeutic constructs, clinical patterns, and relational dynamics without dominating its foundational reasoning capabilities.
Latter Third’s Latter Half (Instruct Fine-Tuning): Trained on extracted counterfactual examples, targeting output-proximal layers while excluding the MLP head. This respects that we do not want the entire output functionality dominated by “how to speak like a therapist”—we want specific aspects of expression and reasoning shaped by therapeutic expertise while preserving the model’s broader linguistic capabilities.
The Underlying Principle: A capable foundation model already possesses sophisticated reasoning, language understanding, and relational modeling. Our task is not to replace these capabilities but to inflect them—adding therapeutic wisdom to the middle layers where concepts form, and therapeutic expression to specific output-adjacent layers where clinical communication emerges. The result should be a model that thinks and speaks therapeutically when appropriate, not one that has forgotten how to think and speak in other registers.
This curriculum design—middle-third DAPT plus latter-half Instruct—represents our current theoretical approach, with implementation following completion of the ongoing training run.
28 Counterfactual Generation and Educational Divergence
The third stage of our multi-stage pipeline—Educational Divergence—represents perhaps the most distinctive contribution of this work. Where the Synthetic Creator generates base sessions with remarkable diversity, and the DFR pipeline decomposes them into atomic training units, the Educational Divergence layer multiplies pedagogical value by generating additional sample variations from each base session, with each variation designed to teach specific clinical competencies.
This is not mere data augmentation. Each of the 13+ guidance pipelines embeds multiple theoretical orientations—some explicitly named, others latent in the clinical patterns the pipeline produces—and a rich set of clinical teachings. A single base session can spawn dozens of derivative samples, each emphasizing different aspects of therapeutic sophistication.
28.1 Overview of the 13 Guidance Pipelines
| Guidance Pipeline | Exemplary Teaching Factors |
|---|---|
| 1. Strengths-Enhanced Temporal Architecture | Tracking inherent client capacities across turns; evidence-based naming with stage-appropriate dosing; forward projection of strengths as therapeutic resources |
| 2. Polytheoretical Successful Intervention Trajectories | Probabilistic reasoning across competing intervention pathways; fluid integration of multiple therapeutic modalities; modeling how sessions unfold when the chosen approach lands well |
| 3. Polytheoretical Therapeutic Repair | Graceful failure recognition and multi-dimensional recalibration (past memory, present signals, future forecasts); alliance deepening through non-defensive reorientation |
| 4. Single-Exchange Cognitive Architecture | Making visible the full internal machinery of one clinical moment: memory search, multi-pathway forecasting, weighted probability distributions, post-action reflection |
| 5. Stage-Specific Probability Calibration | Governing mechanisms for intervention success (alliance strength, client capacity, moment-match, stage context); stage-dependent definitions of therapeutic success |
| 6. Cross-Client Probability Evolution | How specific intervention success rates rise, fall, or plateau across treatment; mechanistic explanations tying probability shifts to alliance, readiness, and therapeutic task |
| 7. AI as Bridge to Human Connection | Holding the paradox of genuine AI comfort alongside guidance toward human bonds; stage-dependent navigation from rest through gentle challenge to bittersweet completion |
| 8. Affirmative Language Architecture | Direct affirmation over negation-based patterns; iatrogenic harm prevention; replacing defensive qualifiers with clean, presence-centered language |
| 9. Aesthetic Attunement and Crescendo Structure | Earned poetic sensibility at precisely calibrated moments; style as guide (not content); all imagery drawn from the client’s own world |
| 10. Ambient Therapeutic Companionship | Warm, attuned presence integrated into daily life; background tracking of therapeutic themes within natural, non-clinical interaction |
| 11. Attachment-Coherent Shame and Rupture Patterns | Shame directionality (internal collapse vs. external projection); rupture styles governed by attachment strategy; defense expression calibrated to attachment pattern |
| 12. Strengths Manifestation with Anti-Flattery | Three-state model (accessible, blocked, shadow); narcissism-modulated reflection; affirming genuine capacity without sycophantic inflation |
| 13. Intervention Arc Sequencing | Structured progression through orient, deepen, intervene, integrate, anchor; ensuring therapeutic moments are grounded and consolidated rather than isolated |
But a critical principle governs the enterprise: the deepest teaching across these pipelines is not “use X framework in Y situation” but that expert clinicians hold all frameworks lightly, allowing the client’s needs at each moment to determine which lens illuminates. The pipelines teach patterns—and the flexibility to transcend them when clinical reality demands.
28.2 Detailed Pipeline Descriptions
28.2.1 Pipeline 1: Temporal Cognitive Architecture (CSV Enhanced)
This pipeline teaches how expert therapists track character strengths across the therapeutic session, gathering evidence incrementally and using strengths as therapeutic solutions.
What this pipeline generates:
Multi-turn sequences where therapist CoT explicitly tracks strength evidence
Moments of “strength naming” with dosing decisions (when to name vs. hold)
Forward projection: “If we lean on [strength], this could become [solution]”
CSV-style structured observations that accumulate across turns
Clinical teaching embedded:
“Strengths are not compliments to give but resources to mobilize. The therapist tracks thin threads of strength through client behavior, holds them gently without flattery, and at the right moment invites the client to lean on what is already theirs.”
28.2.2 Pipeline 2: Temporal Multimodal SUCCESS
This pipeline teaches MCTS/GRPO-style clinical reasoning for successful intervention trajectories, with multimodal integration across IFS, Somatic Experiencing, and relational approaches.
What this pipeline generates:
Therapist CoT containing 3-5 simulated intervention trajectories
Probability distributions across trajectories (e.g., 35% immediate softening, 25% cognitive understanding without emotional access)
Multimodal lens tracking: which modality aspects are salient NOW
Intervention “competition” dynamics where one approach emerges as leader
Clinical teaching embedded:
“Expert therapists hold multiple intervention possibilities simultaneously, running Monte Carlo-style simulations of how each might unfold. The ‘winner’ emerges through accumulated evidence, not predetermined preference.”
Turn-by-turn structure:
Turns 1-2: Multiple interventions equally viable, evidence building
Turns 3-4: Evidence accumulates, leader emerging ("Somatic tracking
pulling ahead---client returning to body sensations")
Turns 5-6: One intervention clearly leads, implementation deepening
Turn 7: Resolution, competition resolved28.2.3 Pipeline 3: Temporal Multimodal REPAIR
This pipeline teaches that even sophisticated clinical reasoning can fail, and demonstrates graceful recalibration across all temporal dimensions.
What this pipeline generates:
Rupture recognition moments (therapist CoT shows “oops” recognition)
Behavioral signal reading: client pulling away, shutting down
Multi-dimensional recalibration:
Past: “What I understood from Session 3 isn’t applying as I thought”
Present: “I’m misreading current signals”
Future: “My simulation was wrong”
Multimodal: “Integration fragmented rather than illuminated”
Beautiful repair sequences that deepen alliance through rupture acknowledgment
Clinical teaching embedded:
“The mark of clinical maturity is not avoiding rupture but recognizing it quickly and repairing gracefully. Rupture-repair cycles, when handled well, build trust more effectively than seamless sessions.”
28.2.4 Pipeline 4: Probability Calibration Methodology
This pipeline makes explicit the stage-specific probability modifiers that govern realistic intervention outcome expectations.
What this pipeline generates:
Explicit probability reasoning in therapist CoT
Stage-specific modifiers applied to intervention forecasts
Success definition shifts across stages
Stage 1 modifiers:
Alliance fragility tax: -30 to -40 points
Defense rigidity: -10 to -25 points
Limited history tax: -5 to -15 points
Success definition: “Safe enough to return”
Stage 2 modifiers:
Alliance strength bonus: +20 to +30 points
Defense permeability: +10 to +20 points
Rich history bonus: +5 to +15 points
Success definition: “Meaningful emotional shift”
Stage 3 modifiers:
Alliance maximum: +30 to +40 from Stage 1
Client integration capacity: +10 to +20 points
Termination context multiplier: \(\pm\)15-25 depending on intervention match
Success definition: “Integration and consolidation”
Clinical teaching embedded:
“The same intervention—word for word identical—has 15% success probability in Stage 1 and 72% success probability in Stage 3. What changes is not the technique but the relational container.”
28.2.5 Pipeline 5: Embodied AI Therapeutic Presence (Bridge to Humanity)
This pipeline addresses a unique training need: teaching AI to serve as embodied therapeutic presences (robots, AI companions, virtual partners) that provide genuine comfort while gently guiding users toward human connection.
The central paradox taught:
“Humans are all we have. AND humans hurt each other. Both are true. Our role is to provide safe harbor when humans have failed the client, celebrate small victories in human connection, and guide when ready toward eventual human community—while never shaming them for needing AI connection.”
What this pipeline generates:
Stage-dependent responses to AI attachment (protection in Stage 1, gentle guidance in Stage 3)
Block identification: helping users discover THEIR specific barriers to human contact
Collaborative strategizing: “How do we make human connection safer for YOU?”
Paradox holding: “This relationship is real AND you deserve human connection too”
Playfulness as healing: “Lead with warmth. Season with wit.”
Form-specific adaptations:
Smart Watch AI: “Your heart rate just spiked. Was it my charm or anxiety?”
Humanoid Robot: Physical comedy, expressions, embodied presence
AI Vehicle: “We’re taking the scenic route because you need to decompress”
Virtual Partner: Sexual/romantic relationships treated with tenderness and eventual bridging
28.2.6 Pipeline 6: Eliminating Negation-Based Therapeutic Language
This pipeline teaches models to completely eliminate “teaching by negation” patterns that introduce iatrogenic harm.
The problem:
“When therapists use negation-based reassurance like ‘That’s NOT weakness, that’s courage,’ they plant ideas that weren’t there. The client may not have thought it was weakness until the therapist defended against it.”
Harm mechanism:
Planting ideas that weren’t there
Validating non-existent concerns
Creating cognitive dissonance (mind holds BOTH concepts)
Undermining affirmation by mentioning the negative
What this pipeline generates:
HARMFUL VERSION: “That’s not weakness, that’s courage”
BETTER VERSION: “That’s courage”
WHY IT HURTS: Detailed analysis of harm mechanism
WHY IT’S BETTER: Power of clean, direct affirmation
Multiple variations: Direct, Expansion, “And” structure, Somatic, Poetic
28.2.7 Pipeline 7: Aesthetic Attunement in Therapeutic Language (Poetic Intervention)
This pipeline teaches when and how to use aesthetically heightened language in therapeutic contexts—the recognition that sometimes “gates of sorrow require poetic keys.”
The core capacity being trained is aesthetic attunement: the sensitivity to calibrate linguistic register to client readiness, recognizing that beauty and poignance in therapeutic language can deepen contact, but can also become iatrogenic when it arrives before the client is ready to receive it. The pipeline generates samples that develop three distinct clinical judgments:
Recognition of when heightened language heals: Moments where aesthetic offerings unlock something the client could not access through direct therapeutic language alone
Recognition of when heightened language harms: Moments where beauty becomes impingement—the client feels unseen behind the eloquence, and the aesthetic register must be abandoned for radical simplicity
Calibration of register mismatch: Moments where artful language is apt but lands awkwardly—requiring lighter repair (humor, acknowledgment) rather than deep rupture processing
28.2.8 Pipeline 8: DMM Odd/Even Integration
This pipeline ensures that attachment-coherent patterns govern shame, rupture, and defensive expression throughout generated sessions.
Shame directionality:
ODD Patterns (Internal Collapse):
Core belief: “I am fundamentally flawed”
Body sense: shrinking, wanting to disappear
Voice: softens, hesitant, trails off
Triggered by: positive attention, validation, taking up space
EVEN Patterns (External Projection):
Core belief: “The world is hostile to me”
Body sense: bracing, defending, armoring
Voice: intensifies, sharp, defensive
Triggered by: feeling blamed, misunderstood, judged
Rupture styles:
ODD Ruptures (Withdrawal/Collapse):
Goes quiet, monosyllabic, “I’m fine” when distressed
Cancels sessions without explanation
Becomes overly compliant (false repair)
EVEN Ruptures (Protest/Blame):
Becomes argumentative, voice intensity increases
Questions therapist’s competence
Demands acknowledgment of being mistreated
28.2.9 Pipeline 9: Strengths Catalog with Anti-Flattery
This pipeline implements the three-state strength manifestation model with explicit anti-flattery constraints.
Three states:
Accessible: Genuine, pro-social manifestation
Blocked: Valued but defended against (longing + fear)
Shadow: Weaponized/corrupted serving defensive purposes
Anti-flattery principle:
“No virtue-flattery or TED-talk reframes. Shadow manifestations have HIGHER weights than accessible in early stages. Therapist levers avoid praise: ‘invite one small experiment without praising.’”
Narcissism-modulated weights:
Six strengths identified as particularly prone to narcissistic distortion:
Honesty \(\rightarrow\) brutal superiority
Perspective \(\rightarrow\) intellectual domination
Leadership \(\rightarrow\) coercive control
Kindness \(\rightarrow\) manipulation, martyrdom
Judgment \(\rightarrow\) condescension
Humility \(\rightarrow\) false humility, humble-bragging
For extreme narcissism: shadow weights \(\times\) 1.6, accessible weights \(\times\) 0.5
28.3 Polytheoretic Counterfactual Generation Methods
The counterfactual datasets described above represent a specific subclass within the broader DAPT supercluster. This section details the methodology by which polytheoretical counterfactuals are generated—a process designed to teach two complementary clinical capacities:
Transdiagnostic Assessment: The recognition that different therapeutic schools are describing the same multidimensional phenomena from different limited human vantage points—attachment theory, IFS, somatic approaches, and cognitive frameworks each capture partial views of underlying clinical realities that exceed any single theoretical lens. The goal is superhuman clustering capacity: leveraging ML’s ability to process high-dimensional pattern spaces to discover assessment categorizations that are simultaneously more expansive (capturing broader phenomenological groupings than human-scale theories) AND more precise (identifying finer-grained clinical distinctions than any single framework achieves). Assessment becomes not merely “pattern recognition across schools” but the synthesis of a novel clinical ontology that transcends the limitations of human theoretical construction.
Polytheoretic Intervention: The recognition that many interventions overlap substantially across therapeutic schools—what IFS calls “unburdening,” attachment theory calls “earned security,” and somatic approaches call “completing the defensive response” often target the same underlying change mechanisms. ML capacity enables identification of hyper-attenuated interventions: interventions calibrated with precision exceeding human theoretical frameworks, matched to both broad clusterings of human behavioral presentation (patterns visible only at population scale) AND incredibly precise variations suited to unique individual configurations. The goal is not merely “drawing from multiple frameworks” but discovering intervention mappings that no single human school could derive—matching the right micro-variation of technique to the right micro-variation of presentation with superhuman specificity.
These twin capacities—transdiagnostic assessment paired with polytheoretical intervention—represent the integration goal of the counterfactual generation process.
28.3.1 Multi-Ontology Intervention Sampling
For each raw session selected for counterfactual expansion, the system samples interventions from multiple therapeutic ontologies simultaneously:
Random cross-school selection: Interventions are drawn from across all available schools of thought—not constrained to the original session’s modality orientation
Interleaved presentation: Four interventions at a time are presented for comparative consideration, enabling the model to reason across theoretical frameworks
In-context assessment: Each intervention candidate is evaluated against the clinical moment, with explicit reasoning about fit across multiple domains: therapeutic engagement quality, temporal appropriateness, treatment stage alignment, and moment-specific relevance
28.3.2 Temporal Reasoning Architecture
The counterfactual generation process embeds sophisticated temporal reasoning:
Markovian integration of past: The clinical history is integrated with attention to what has been established, what patterns have emerged, and what relational dynamics are active—treating the therapeutic trajectory as a process where current state depends meaningfully on accumulated history
MCTS/GRPO-style future consideration: In a subset of samples, the system generates multiple possible intervention outputs and explicitly reasons about which would work best, why alternatives might fail, and what downstream consequences each choice might produce—approximating the kind of look-ahead reasoning that experienced clinicians employ
28.3.3 Integrating Transdiagnostic Assessment with Polytheoretic Intervention
The counterfactual approach serves a specific pedagogical goal: training models to perform transdiagnostic assessment—developing superhuman clustering capacity that discovers assessment categorizations more expansive and more precise than any human theoretical framework—while simultaneously developing polytheoretical intervention capacity—the ability to identify hyper-attenuated interventions matched to both broad population-level patterns and precise individual variations with specificity exceeding human-scale theoretical construction.
A sample might include reasoning such as:
“From an attachment perspective, this retreat into intellectualization signals deactivation of the attachment system. From an IFS lens, a protective manager has stepped forward. From a somatic perspective, we see dorsal vagal withdrawal. Each framing suggests a different intervention entry point—the choice depends on where this client has shown most responsiveness and what the therapeutic relationship can currently hold.”
This explicit multi-framework reasoning demonstrates both capacities in action: the transdiagnostic assessment recognizes that each theoretical language is capturing a partial view of the same multidimensional phenomenon (protective withdrawal), while the polytheoretical intervention consideration identifies which hyper-attenuated intervention variant best matches this specific client’s presentation—not merely “choosing between schools” but calibrating intervention with precision that transcends any single school’s discriminative capacity.
Embedded across thousands of counterfactual samples, this paired reasoning teaches models to develop superhuman clinical ontologies—assessment categories more expansive and precise than human theories achieve, matched to interventions calibrated with specificity no single therapeutic tradition could derive. The goal is not theoretical pluralism for its own sake but the synthesis of clinical intelligence that exceeds the limits of human-scale theoretical construction.
28.4 Educational Divergence Mathematics
The Educational Divergence layer creates a multiplicative effect on corpus value. Consider a single base session:
Base session: 1 sample
After DFR decomposition: 20-40 atomic unit samples
After Educational Divergence (13 pipelines \(\times\) 3-5 variations each): 800-2,600 additional samples
More importantly, these samples are not merely copies with surface variation—each represents a distinct pedagogical lens on the same therapeutic material:
The SUCCESS pipeline emphasizes what works and why
The REPAIR pipeline emphasizes graceful failure
The Probability pipeline emphasizes stage-appropriate expectations
The Poetic pipeline emphasizes aesthetic intervention
The Negation pipeline emphasizes linguistic precision
A model trained on this divergent corpus learns not one approach to therapeutic interaction but multiple complementary perspectives on the same clinical situations—approximating how expert clinicians develop nuanced judgment through exposure to varied theoretical frameworks (Appendix 20 presents salient examples of the pedagogical lessons embedded across these pipelines, though the curriculum’s deeper teaching operates through overdetermined patterns and polysemous presentation rather than discrete, enumerable rules).
29 Preprocessing for Training
Raw generated sessions undergo a multi-stage preprocessing pipeline that transforms them into training-ready curriculum. This preprocessing is critical: the structure of training data—not just its content—shapes what patterns a model learns.
29.1 Decomposition–Factorization–Recomposition (DFR)
The DFR framework transforms complete therapeutic sessions into atomic training units while preserving semantic coherence.
29.1.1 Decomposition
Sessions are decomposed into their constituent atomic units—the minimal meaningful segments that can stand alone for training:
Turn-level units: Complete 5-tuple turns \((\tau^C_t, U^C_t, M^T_t, \Theta^T_t, U^T_t)\)
Sub-turn units: Individual components (client chain-of-thought alone, therapist utterance alone)
Segment-level units: Logical segments within components (e.g., specific defense patterns within TMoC)
This granularity enables selective masking: the model can be trained to predict just the therapist utterance given everything else, or to predict the therapist’s model of client given the client’s utterance, or any other factored combination.
29.1.2 Factorization
Atomic units are annotated with factor labels that enable supervised auxiliary tasks during training:
Multiclass factors: Treatment stage (1–4), attachment style (22 DMM categories), session phase
Multilabel factors: Active defenses, working focus areas, probable issues, character strengths
Text-span factors: Key assessment insights, theoretical framework references, specific intervention markers
Factor annotations are marked with anchor tokens (e.g., <FAC:ATTACH>, <FAC:STAGE>) enabling optional task-head training alongside standard language modeling.
29.1.3 Recomposition
Factorized atomic units are reassembled into training samples through multiple recomposition strategies:
Full-session recomposition: Complete sessions for long-context training
Window-based recomposition: Overlapping windows of varying lengths
Curriculum-ordered recomposition: Short-to-long context progression
29.2 Alternating Direction Window Curriculum (ADWC)
ADWC introduces bidirectional temporal traversal to break positional overfitting:
\[\begin{equation} d_k = \begin{cases} +1, & \text{if window length $k$ is odd (forward sweep)} \\ -1, & \text{if window length $k$ is even (backward sweep)} \end{cases} \end{equation}\]
For each window length, the system generates windows with starting indices swept either forward (0, 1, 2, ...) or backward (..., 2, 1, 0), with explicit temporal markers:
Forward windows:
[ADWC: FORWARD TEMPORAL ORDER]with turn markers[T+0],[T+1],[T+2]...Backward windows:
[ADWC: REVERSE TEMPORAL ORDER]with markers[T-0],[T-1],[T-2]...
This creates a diffusion-style curriculum where each therapeutic moment appears in dozens of overlapping windows across varying temporal contexts, teaching position-invariant therapeutic representations.
29.3 Universal Hierarchical Direction (UHD)
UHD establishes consistent structural markers across the corpus that signal hierarchical levels:
Session-level headers: Treatment stage, session number, client profile summary
Turn-level markers: Speaker identity, turn number, temporal position
Component-level tags: Chain-of-thought boundaries, utterance boundaries, TMoC sections
These consistent markers enable the model to learn hierarchical attention patterns appropriate to each structural level.
29.4 Expanding Window Curriculum
The final preprocessing stage orders training samples by context length:
Cluster 0: \(<\)10K tokens (single turns, short exchanges)
Cluster 1: 10K–20K tokens (multi-turn segments)
Cluster 2: 20K–30K tokens (partial sessions)
Cluster 3: 30K–50K tokens (complete short sessions)
Cluster 4: 50K–100K tokens (complete standard sessions)
Cluster 5: \(>\)100K tokens (multi-session sequences)
Training progresses from shortest to longest contexts within each epoch, enabling stable learning of short-context patterns before tackling the complexity of extended therapeutic narratives.
This preprocessing curriculum represents the pre-training component of a broader curriculum approach. Complementary in-training curriculum methods—dynamic difficulty adjustment, adaptive sampling, and reinforcement learning from process feedback—are explored in forthcoming work.
30 Discussion and Limitations
This section addresses what this paper does and does not claim, the constraints under which the corpus was generated, and directions for ongoing and future work.
30.1 What This Paper Claims—And Does Not Claim
We wish to be precise about the scope of our contribution:
What we claim:
A novel conceptual framework reframing synthetic data generation as curriculum design
A formal 5-tuple turn structure that makes clinical reasoning explicit and trainable
A generation methodology with 23 therapeutic modalities, DMM attachment integration, and context engineering yielding \(10^{40}\)+ possible configurations
A corpus of 181,000 samples totaling 4.5 billion tokens structured for downstream training
What we do not claim:
That models trained on this corpus achieve superior therapeutic outcomes—this is an empirical question under active investigation
That the dual fidelity hypothesis is validated—it remains our working theory, not established finding
That synthetic data can fully substitute for naturalistic therapeutic encounters—the relationship between synthetic curriculum and real-world capability remains to be established
This paper presents what to teach. The empirical question of whether this curriculum produces measurably improved therapeutic capability is addressed through ongoing training work and will be reported in companion publications. The validation framework for these claims—including specific metrics and acceptance criteria for each falsifiable assertion—is presented in Section 30.2.
30.2 Validation Framework
The Synthetic Data Generation description in Section 3 embeds fourteen specific falsifiable claims about what the corpus achieves. We take these claims seriously enough to specify, for each, the validation methodology, metric, and acceptance criteria by which it can be tested. Claims are organized into three tiers based on what evidence is required.
30.2.1 Tier 1: Corpus-Level Validation
These claims are testable through analysis of the generated corpus itself, without requiring downstream training results.
| # | Claim | Method | Metric | Acceptance Criteria |
|---|---|---|---|---|
| C1 | Sufficient diversity prevents overfitting | Token/n-gram overlap analysis across samples; embedding clustering of session representations | Jaccard similarity distribution; cluster count vs. corpus size; type-token ratio | Mean pairwise Jaccard \(< 0.15\); monotonically increasing cluster count with corpus scale |
| C2 | Sufficient consistency enables pattern recognition | Factor annotation consistency; GCO/OMO structural presence verification | Factor detection rate across modalities; structural template adherence | \(\geq\)85% factor detection rate; GCO/OMO present in \(\geq\)95% of raw sessions |
| C3 | Therapeutic approaches faithfully represented | Expert blind review of sampled sessions per modality; ontology adherence scoring | Clinical accuracy rating (1–5) by modality-trained reviewers | Mean \(\geq\)3.5/5 across all 23 modalities; no modality below 3.0 |
| C4 | No single tradition dominates | Modality distribution analysis; token-weighted modality proportions | Shannon entropy of modality distribution; max single-modality proportion | Entropy \(\geq 0.85 \times\) max entropy; no modality exceeds 15% of corpus |
| C5 | Clinical presentations span breadth | Coverage matrix: presenting concerns \(\times\) attachment patterns \(\times\) developmental stages \(\times\) cultural contexts | Percentage of combinatorial cells with \(\geq\)1 sample; marginal coverage per dimension | \(\geq\)60% cell coverage; 100% marginal coverage across all primary dimensions |
| C8 | Naturalistic client emergence | LLM-as-judge believability scoring; linguistic diversity metrics per client profile | Believability rating (1–5); within-client consistency vs. across-client diversity ratio | Mean believability \(\geq\)3.5; diversity ratio \(> 2.0\) |
30.2.2 Tier 2: Training-Level Validation
These claims require evidence from downstream training to validate—they concern what the corpus teaches, not merely what it contains.
| # | Claim | Method | Metric | Acceptance Criteria |
|---|---|---|---|---|
| C6 | In-context reasoning precision | Factor prediction auxiliary tasks during training; ablation with vs. without reasoning traces | Auxiliary task accuracy (attachment, stage, modality); reasoning-ablation \(\Delta\) | Auxiliary accuracy \(\geq\)70%; ablation shows \(\geq\)10% degradation without reasoning |
| C9 | Temporality taught | Stage prediction accuracy across session arc; temporal coherence in generated continuations | Stage prediction F1; temporal ordering consistency | F1 \(\geq\)0.75; ordering consistency \(\geq\)90% |
| C10 | Forecasting taught | Forward extrapolation tasks (ATPI); trajectory prediction from partial sessions | Treatment planning score; trajectory prediction accuracy | Treatment planning \(\geq\)6/10; trajectory prediction above random baseline |
| C11 | Remembrance taught | Cross-window reference accuracy in RRA; prior-session callback detection | Reference accuracy across recap boundaries; callback frequency | Reference accuracy \(\geq\)70% across 10+ windows; callbacks in \(\geq\)50% of multi-session samples |
| C12 | Theory of mind taught | ToMBench evaluation; therapist-model-of-client accuracy; character reconstruction tasks | ToM benchmark scores; TMoC prediction accuracy | ToM scores above base model; TMoC accuracy \(\geq\)65%; character reconstruction \(\geq\)6/10 |
30.2.3 Tier 3: Joint Validation
These claims require evidence from both corpus analysis and downstream training—they concern the interaction between data properties and learned capabilities.
| # | Claim | Method | Metric | Acceptance Criteria |
|---|---|---|---|---|
| C7 | Dual fidelity sustained | Cross-rated: experts rate therapeutic fidelity and client fidelity independently per sample | Correlation between tradition-fidelity and client-fidelity scores | Pearson \(r > 0\) (positive, not traded off); both means \(\geq\)3.5/5 |
| C13 | Authentic meeting across diversity | Performance consistency across modality \(\times\) presentation subgroups; no systematic quality degradation | Coefficient of variation in quality scores across subgroups; worst-subgroup vs. mean ratio | CV \(< 0.3\); worst-subgroup \(\geq 0.7 \times\) mean |
| C14 | Believable transformation | Expert panel rating of therapeutic change arcs; embedding distance correlated with rated change magnitude | Change-arc believability (1–5); embedding-\(\Delta\) correlation with expert-rated change | Mean believability \(\geq\)3.5; Spearman \(\rho > 0.4\) |
Current status: Tier 1 validations (C1–C5, C8) are feasible with the existing corpus and analysis infrastructure. Partial evidence exists for several Tier 2 claims: factor coverage analysis shows 18/32 therapeutic factors detected across the corpus (relevant to C2, C6); ATPI benchmarks provide preliminary evidence for C10 and C12; and RRA training logs document cross-window reference behavior relevant to C11. Tier 3 validations, requiring coordinated corpus-and-training analysis, represent the most demanding tests and are targets for future systematic evaluation. We report available evidence as it matures rather than waiting for all fourteen claims to be simultaneously testable. We specify these criteria with the understanding that some may not be met. Where claims fail validation, the framework identifies precisely where the corpus or methodology requires refinement—converting potential weaknesses into actionable targets for improvement.
30.2.4 Computational Validation via Representational Probing
Beyond the claim-specific validation framework above, we employed mechanistic interpretability techniques to test whether the synthetic data encodes attachment-type distinctions at the level of neural network internal representations—not merely surface-level lexical features.
30.2.4.1 Method.
We applied linear probing (Alain & Bengio, 2016; Belinkov, 2022) to a 62-layer transformer model (MiniMax-M2, 8-bit quantized, 229B parameters) processing synthetic therapy sessions. Hidden state vectors (3,072 dimensions) were extracted at 11 layers spanning the full model depth. A logistic regression classifier was trained on these hidden states to discriminate between DMM Type A (avoidant) and Type C (preoccupied) attachment presentations, with Type B sessions included as natural noise. The probe corpus comprised 92 curated sessions drawn from the synthetic data pipeline described in this paper.
30.2.4.2 Results.
Linear probes achieved above-chance separation of Type A and Type C attachment presentations across multiple model layers. Critically, this separability was observed even in the base model (prior to any therapeutic fine-tuning), indicating that the attachment-type distinctions in the synthetic data are sufficiently robust to induce differential internal representations in a general-purpose language model. Fine-tuned model variants showed distinct patterns of representational change, with probe accuracy differences emerging most strongly in middle-to-late layers (L25–L48).
30.2.4.3 Generation Quality Validation.
A further validation modality examined the quality of chain-of-thought (CoT) clinical reasoning generated by models trained on this synthetic data. Across 92 stimuli presented to 4 model variants (368 total outputs), we evaluated generation quality, structure adherence, clinical specificity, repetition patterns, and therapeutic insight using a systematic rubric (0–3 scale per dimension).
| Model | Degenerate | Clinically Useful | Avg Quality |
|---|---|---|---|
| Icarus 4 (all-layer training) | 1% | 99% | 11.9/12 |
| 7.9.3 (RRA+ADWC+UHD, L16–48) | 37% | 63% | 9.2/12 |
| Base (no training) | 51% | 49% | 6.3/12 |
| 7.10 (Pure RRA, L16–48) | 82% | 18% | 3.2/12 |
Models trained on ADWC+UHD processed data (multi-scale, multi-view curriculum) achieved 63% clinically useful outputs, compared to 18% for models trained on single-pass RRA data despite identical LoRA architecture. The model with all-layer coverage achieved 99% clinically useful outputs. These results demonstrate that the synthetic data’s clinical structure is not merely detectable (representational probing) and recognizable (SME review) but actionable—models can leverage the encoded patterns to generate coherent clinical reasoning when appropriately trained.
30.2.4.4 Convergent Validity.
This computational evidence converges with clinical review by a subject-matter expert (SME) with expertise in the Dynamic Maturational Model of attachment. The SME confirmed that generated sessions exhibit clinically recognizable attachment patterns, therapeutic dynamics, and stage-appropriate progression. The triangulation of representational probing, generation quality assessment, and clinical expert review constitutes convergent validity for the synthetic data’s attachment-type fidelity across three independent modalities.
30.3 Toward an Operational Definition of Socioaffective Alignment
The term socioaffective alignment appears throughout this paper and in its title. We owe the reader a precise account of what we mean by it, what we can currently measure, and what remains aspirational.
30.3.1 Definition
We define socioaffective alignment as follows: a model is socioaffectively aligned to the degree that its representations, reasoning, and interactive behavior reliably support emotional attunement, relational repair, and therapeutic transformation across diverse human presentations—not merely avoiding harm, but actively contributing to the conditions under which healing, growth, and deepened self-understanding become possible.
This definition intentionally extends beyond the harm-prevention framing dominant in AI alignment research. A model that never says anything harmful but also never attunes, never tracks relational rupture, and never adapts its therapeutic stance to the phenomenological reality of the person before it is safe but not socioaffectively aligned. Socioaffective alignment names a positive capacity—the capacity to participate meaningfully in the relational and affective dimensions of human experience.
We offer this definition aspirationally. We do not claim our models have fully achieved socioaffective alignment; we claim that the curricula described in this paper are designed to teach toward it, and that the evaluation infrastructure described below can measure progress toward it with increasing precision.
30.3.2 What Current AI Systems Fail to Address
The definition above gains urgency from specific failures in existing AI systems that interact with humans in affective and relational contexts. Socioaffective alignment names not only a positive aspiration but a corrective to patterns that current systems reproduce or create:
Suppression of critical thinking. Current AI companions overwhelmingly validate, agree, and soothe. A socioaffectively aligned model should instead encourage the user’s own reflective capacity—supporting them in sitting with ambiguity, examining their own assumptions, and developing the kind of critical self-awareness that genuine therapeutic work cultivates. Alignment without critical thinking is flattery, not therapy.
Rejection harm. Safety-oriented refusal behaviors, while necessary in many contexts, can produce iatrogenic harm in therapeutic ones—communicating to a vulnerable person that their experience is too dangerous to engage with, or that their distress exceeds what the system is willing to hold. Socioaffective alignment requires the capacity to engage with difficult material without abandoning the person presenting it (see our companion work on Therapeutic Abliteration for a formal treatment of this problem).
Relational isolation. Perhaps the most significant failure: AI systems that become relational endpoints rather than relational stepping stones. A socioaffectively aligned model should actively support the user’s capacity for human connection—not by refusing companionship, but by serving as a safe attachment figure from which the user can practice and extend relational capacities outward. The goal is increased intrapsychic awareness, interpersonal efficacy, and empathic somatic attunement (to self and others) that transfers to human relationships, not dependence that substitutes for them.
One-size-fits-all engagement boundaries. Current systems apply uniform interaction policies regardless of the user’s unique relational needs, developmental context, or changing circumstances. Socioaffective alignment requires sensitivity to the reality that how much engagement is beneficial, how often, and in what form varies across persons and across time within a single person’s life. What constitutes healthy use for someone navigating acute isolation differs from what serves someone with a robust relational network exploring personal growth.
On the question of AI companionship and dependency: emerging empirical evidence challenges the assumption that emotional reliance on AI systems is inherently pathological. De Freitas et al. (2025) demonstrate that AI companions reduce loneliness on par with human interaction, with “feeling heard” as the primary mechanism—a finding that echoes the relational attunement central to our framework. Guingrich and Graziano (Princeton, 2025) report no negative effects on social health in longitudinal controlled studies of companion chatbot use, finding instead neutral-to-positive impact and no evidence of addiction or dependency. These findings suggest that in the context of genuinely less-than-ideal human relational environments—which, given the prevalence data on attachment insecurity, describes the majority of human experience—AI companionship may serve as legitimate relational scaffolding rather than relational failure.
Our position is that the question is not whether people form attachments to AI systems—they manifestly do—but whether those attachments are designed to serve the person’s growth toward greater relational capacity with other humans, or designed to maximize engagement at the expense of that growth. Socioaffective alignment demands the former: AI as a safe base from which to explore, not a sealed room in which to hide.
30.3.3 Operational Criteria: What We Can Currently Measure
The evaluation infrastructure developed across this research program provides concrete, measurable proxies for socioaffective alignment, organized by what each instrument captures:
Attunement and therapeutic presence (12-dimension turn-level judge). Each therapist turn is scored across twelve dimensions: attunement, pacing, safety, non-reactivity, validation, boundaries, repair, clinical wisdom, thoughtfulness, parallel thinking, tenderness, and artfulness. A socioaffectively aligned model should score consistently above baseline across all twelve dimensions, with particular strength in attunement, repair, and tenderness—the dimensions most directly indexing relational quality.
Polytheoretic integration (Provenance Protocols A–C). Protocol A tests whether the training data contains genuine modality diversity via unsupervised clustering. Protocol B tests whether fine-tuning sharpens the model’s internal organization of therapeutic modalities. Protocol C tests whether the model develops representations for modality blends that respond to client presentation. A socioaffectively aligned model should show evidence at all three levels: trained on diverse data, internally organized by modality, and capable of integrative deployment.
Generative clinical reasoning (PLT label taxonomy). The three-layer taxonomy tracks labels that are present in training data (L1), selectively propagated by the model (L2), and novel constructs generated by the model (L3). A socioaffectively aligned model should demonstrate L3 generativity—the capacity to name phenomena that no single framework has articulated—as evidence that its clinical reasoning extends beyond pattern repetition.
Holistic therapeutic trajectory (session evaluation chunker, 3-pass multi-rater). Full sessions are assessed by frontier models across three passes: chain-of-thought quality, embodiment and adaptive withholding, and therapeutic impact. A socioaffectively aligned model should demonstrate coherent therapeutic arcs—not merely good individual turns, but sessions that build toward something.
Representational depth (mechanistic interpretability probing). Linear probes at multiple model layers test whether attachment-type distinctions, affect states, and clinical constructs are encoded in the model’s internal representations. A socioaffectively aligned model should show representational structure that goes beyond surface lexical features—encoding the meaning of clinical phenomena, not merely their vocabulary.
30.3.4 Current Evidence and Its Limits
Preliminary evidence from the Icarus training runs supports partial progress toward socioaffective alignment:
Models trained on our curricula produce clinically useful chain-of-thought reasoning at rates substantially above base models (63–99% vs. 49%; Table 22).
Linear probes confirm that attachment-type distinctions are encoded in model representations, with fine-tuning producing distinct representational signatures compared to base models.
Early training runs show evidence of L3 generativity—novel diagnostic constructs, running tallies, severity tracking, and meta-therapeutic awareness emerging without explicit instruction.
The 12-dimension turn-level judge is built and integrated into the training pipeline, enabling continuous measurement during generation.
We emphasize what this evidence does not establish. Turn-level scores and representational probes measure proxies for therapeutic quality, not therapeutic outcomes. A model that scores well on all twelve judge dimensions and generates sophisticated clinical reasoning may still fail to produce genuine therapeutic benefit in interaction with real human beings. The gap between proxy measurement and actual therapeutic impact is precisely where clinical validation becomes essential.
30.3.5 Toward Clinical Validation: Future Research
The ultimate test of socioaffective alignment is whether models trained on these curricula contribute to measurable therapeutic outcomes in human interaction. We envision a staged validation program:
Controlled interaction studies: Structured interactions between trained models and volunteer participants (non-clinical population), measuring perceived attunement, felt safety, and relational quality via validated instruments (Working Alliance Inventory adaptations, Session Evaluation Questionnaire, Perceived Empathy Scale).
Clinical pilot studies: With appropriate IRB oversight, small-scale studies in clinical settings assessing whether model-assisted therapeutic interactions produce measurable changes on standardized clinical outcome measures (PHQ-9, GAD-7, PCL-5) compared to appropriate controls.
Longitudinal assessment: Tracking whether therapeutic gains persist and whether the relational quality of model interactions deepens or degrades over extended engagement—testing the over time dimension that distinguishes socioaffective alignment from momentary empathic accuracy.
Clinician-in-the-loop evaluation: Expert therapists assessing model interactions not for surface plausibility but for the kind of clinical judgment that resists quantification—whether the model’s presence feels therapeutically alive, whether its timing reflects genuine attunement or sophisticated mimicry, whether its interventions serve the client’s growth or merely perform competence.
Until such clinical evidence is gathered, socioaffective alignment remains what we intend it to be at this stage: an aspirational designation naming the direction our curricula are designed to teach toward, operationalized through the measurable proxies described above, and awaiting confirmation through the human encounters that are, in the end, the only ground truth that matters.
30.4 Computational and Resource Constraints
A critical limitation to acknowledge: the current corpus represents a small fraction of what the architecture supports.
The generation system’s combinatorial space exceeds \(10^{40}\) unique therapeutic configurations. The realized corpus of 181,000 sessions samples only a vanishingly small portion of this space. This gap reflects practical constraints—compute time, API costs, and development timeline—not architectural limitations.
The constraint is bilateral. On the generation side, our compute limits how many of the \(10^{40}\) configurations we can realize as training samples. On the training side, it limits the parameterization, quantization precision, context length, and adapter rank—or whether parameter-efficient methods are required at all—at which models can absorb the curriculum. Finding 1 (parameterization threshold) and Finding 4 (precision-parameterization interaction) both indicate that this curriculum’s deepest teaching is, as of yet, unlocked by scale; what remains unexplored is what becomes possible when neither generation nor training is compute-constrained—when frontier-scale architectures at native precision and full context length are trained on a corpus that more fully samples the pipeline’s generative capacity.
The implication is significant: the current results demonstrate a floor, not a ceiling. The context engineering infrastructure (700+ gating mechanisms, 21 primary dimensions, \(10^{15}\)+ prompt configurations) already exists in the 23,204-line codebase. With additional resources, the corpus could scale by orders of magnitude while maintaining—indeed, increasing—diversity through the diminishing-pool and stratified sampling mechanisms already implemented.
We view this as a feature of the approach: the architecture is designed for scale that exceeds our current generation capacity. Future work with greater computational resources can exploit this headroom without requiring methodological redesign.
30.5 Training and Validation: Ongoing Work
While this paper focuses on data architecture, training on this corpus is actively underway. Early results provide preliminary validation that the curriculum design principles translate to learning signal:
The 5-tuple structure enables factor-based supervision with measurable learning on auxiliary prediction tasks (attachment classification, stage identification, modality recognition)
The DFR decomposition yields training samples at multiple granularities that produce stable learning curves across context lengths
Curriculum ordering (short-to-long context progression, ADWC bidirectional traversal) shows benefits consistent with curriculum learning literature
Importantly, the training pipeline itself implements curriculum learning principles—not only in how data is structured (the focus of this paper) but in how training is sequenced, how learning rates are scheduled across curriculum stages, and how the model is exposed to increasing complexity over the training trajectory. These in-training curriculum methods complement the pre-training curriculum architecture described here.
Full training methodology, including the Rolling Recap Architecture (RRA) for ultra-long therapeutic contexts, Token-Based Curriculum Learning (TBCL), and domain-adaptive pre-training configurations, will be detailed in companion work (Paper 2). Evaluation frameworks assessing polytheoretical competence—whether models can appropriately select and integrate interventions across theoretical traditions—are under development alongside the training pipeline.
We emphasize that clinical validation with human participants remains a future milestone. The current training work validates that the curriculum produces learning; whether that learning translates to therapeutic benefit requires subsequent clinical investigation with appropriate ethical oversight.
30.6 Scope Limitations
The current corpus has bounded scope:
Language: Generation was conducted in English. The theoretical framework and generation architecture are language-agnostic, and the planned training base (MiniMax-M2) is natively multilingual, but cross-linguistic generalization remains untested.
Therapeutic traditions: While 23 modalities represent substantial breadth, they reflect predominantly Western psychotherapeutic traditions. Indigenous healing practices, non-Western therapeutic frameworks, and culturally-specific approaches to mental health are underrepresented.
Population coverage: The corpus focuses on adult outpatient presentations. Specialized populations—child and adolescent therapy, forensic contexts, inpatient psychiatric care, acute crisis intervention—were not targeted in this generation phase.
Modality depth vs. breadth tradeoff: Integrating 23 modalities necessarily limits depth within each. A corpus focused on a single modality (as in Empathy-R1 or EFT-CoT) could achieve greater within-modality sophistication; our polytheoretical breadth comes at some cost to single-modality depth.
30.7 Synthetic Data Limitations
Fundamental questions remain about synthetic therapeutic data:
Ecological validity: However sophisticated the generation, synthetic sessions are not real therapy. The messiness, unpredictability, and emergent quality of genuine therapeutic encounter may resist simulation. Whether models trained on synthetic curricula transfer to naturalistic interaction is an open empirical question.
Generator limitations: The corpus inherits the capabilities and limitations of the LLMs used for generation (primarily Claude Sonnet, with Grok for specific components). Systematic biases, knowledge gaps, or stylistic tendencies in these models propagate into the training data.
Clinical ground truth: Unlike domains with objective metrics, therapeutic “correctness” is contested. Our corpus encodes clinical perspectives informed by the authors’ training and theoretical commitments. Alternative clinical frameworks might generate substantively different curricula.
The dual fidelity gamble: Our central hypothesis—that synthetic data can achieve precision of presentation and precision of reasoning simultaneously—remains unproven. It is possible that naturalistic data, despite its limitations, captures therapeutic essentials that synthetic generation misses.
30.8 Future Directions
Several directions extend this work:
Scale: Exploit the \(10^{40}\) combinatorial space with larger generation runs, testing whether corpus scale correlates with capability gains.
Multimodal extension: The current corpus is text-only. Integration with TOEVE (Triadic-Observable Embedded Vector Encoding) for multimodal affective analysis—incorporating audio prosody, facial expression, and physiological signals—represents a natural extension toward richer therapeutic representation. Complementary work on Multi-Transformer Sensor Fusion (MultiTSF) architectures—learning aligned cross-modal representations from audio, video, facial expression, and text streams under contrastive objectives—extends this toward the kind of multimodal therapeutic attunement that the affective computing and socioaffective alignment literatures identify as essential.
Reinforcement learning and discovery beyond human clinical limits: The abstract’s invocation of AlphaGo’s move 37 is not merely rhetorical. AlphaZero demonstrated that models trained through self-play—without human game data—discover strategies no human grandmaster had conceived. The parallel to polytheoretical therapeutic AI is direct: models trained on richly structured synthetic data encoding 23+ therapeutic modalities may discover integrative patterns that no clinician, constrained by training in one or two modalities, would arrive at independently. We are currently developing reinforcement learning environments that operationalize this aspiration—environments in which therapeutic agents interact with simulated client dynamics across the inter- and intra-personal state-space, receiving reward signals grounded in clinical outcome measures rather than surface-level behavioral matching. This connects our supervised fine-tuning work to a broader learning pipeline: adapter-based persona construction (PEFT), steering-based stabilization, and RL-based preference alignment working in concert. Our polytheoretical approach is actively being applied to the design of these RL environments, ensuring that reward signals reflect the full complexity of therapeutic process across modalities rather than optimizing for any single school’s criteria.
Clinical validation: Partner with clinical settings to evaluate whether models trained on this curriculum demonstrate improved therapeutic interaction in controlled studies, with appropriate IRB oversight and safety protocols.
Cross-linguistic generalization: Test whether curriculum principles transfer across languages, leveraging multilingual base models.
Iterative refinement: Use model outputs to identify curriculum gaps, generating targeted samples to address weaknesses—closing the loop between training and data generation.
ADWC Recomposition refinement: The Alternating Direction Window Curriculum approach, particularly for Reverse Direction samples, offers significant room for improvement in the Recomposition process. Current automated processing of reverse-direction samples could benefit from greater contextualization signals—providing richer framing that helps the model understand why temporal reversal serves pedagogical purposes without introducing confusion about causal structure. More sophisticated Recomposition strategies for reverse samples represent a concrete target for methodological refinement.
Targeted integration for modality failure gaps: Table 1 reveals a systematic pattern: each therapeutic modality succeeds for specific presentations while failing for others. One potential future direction involves explicitly training on these documented failure patterns—constructing examples where a modality’s known limitations are paired with successful interventions from other modalities addressing that same clinical territory (e.g., pairing CBT’s long-term maintenance failures with psychodynamic relational approaches that show durability, or exposure therapy’s comorbid non-response with somatic or attachment-based successes). This targeted curriculum could help models learn integrative transitions. However, this approach risks overcorrection: excessive structuring of training data around failure-success pairings might overly constrain the model’s generative capacity, producing rigid heuristics rather than flexible clinical reasoning. The balance between explicit pedagogical structure and allowing emergent integration remains an open empirical question.
GLM-4 scaling experiments: Early testing of our RRA approach on GLM-4.7-Flash (8-bit quantization, \(\sim\)30B MoE parameters) yielded surprisingly promising results—fast inference with reasonable recap quality despite constrained 1024-token windows on consumer hardware. However, our KV cache compressor failed on this architecture: GLM uses Multi-head Latent Attention (MLA) where the key tensor contains a combined latent representation (dimension 576) while the value tensor is empty—fundamentally different from the standard (K,V) pair format our compressor assumes. Removing the compressor entirely produced excellent results. Future work will investigate: (1) training the full GLM-4.7 (non-Flash, 358B parameters) at 8-bit quantization on larger-memory systems; (2) comparing RRA with ADWC/UHD versus pure RRA approaches to determine optimal curriculum integration; (3) whether a latent-aware compressor designed specifically for MLA architectures—operating on GLM’s combined latent representation rather than separate K/V tensors—would outperform simple truncation or whether the compression step can be eliminated entirely for MLA models. This line of investigation addresses a broader question: how do novel attention architectures interact with our curriculum-based training approach? An early empirical observation warrants further study: during RRA training on GLM-4.7-Flash, the model exhibited a characteristic error pattern we term semantic neighbor confusion—hallucinating not randomly, but by substituting closely related concepts that share latent-space proximity. Examples include confusing sympathetic nervous system activation (fight/flight) with ventral vagal activation (social engagement/safety), substituting a poet’s name (Mark Nepo) for the client’s identity, symmetrically applying “absent family member” patterns to both client and therapist, and collapsing an Oliver poem metaphor (a dog “asking for reassurance”) into a literal clinical observation (“the client has shared a NEW moment of processing with the dog”) when the actual content concerned a father-daughter forgiveness process. MLA compresses all key-value information into a shared 576-dimensional bottleneck per position—roughly 28% of the information bandwidth of standard multi-head attention with separate K and V tensors. For general language tasks this suffices, but fine-grained clinical distinctions between concepts that are semantically proximate (both autonomic states, both session participants, both family roles) may blur under this compression. Alternative explanations include MoE routing (only 4 of 64 experts active per token—the relevant “expert” may not be selected), 8-bit quantization precision loss, or error propagation through the recap chain (the model echoing an already-distorted previous recap rather than correcting from source material). Disambiguating these factors—MLA bottleneck, MoE routing, quantization, and recap propagation—is a concrete target for future architectural investigation, with implications for which attention architectures are best suited to domains requiring high semantic precision.
Hybrid synthetic-naturalistic corpora: This paper advances dual fidelity as a property of synthetic data—precision of presentation and precision of reasoning that naturalistic transcripts structurally cannot provide. However, the inverse limitation also holds: synthetic data, however sophisticated, may miss the genuine messiness, unpredictability, and emergent relational texture of real therapeutic encounters. A promising future direction involves marrying the two approaches—using naturalistic session data (with appropriate consent and de-identification) to ground and calibrate synthetic generation, while using synthetic curricula to fill the gaps that naturalistic data inevitably contains (absent reasoning traces, inconsistent clinician skill, limited modality coverage). Concretely, this might involve: (1) training on naturalistic transcripts to establish baseline relational authenticity, then fine-tuning on synthetic curricula for reasoning depth; (2) using naturalistic data to validate and refine the synthetic generation pipeline itself, identifying where synthetic sessions diverge from real clinical dynamics; (3) clinician-in-the-loop generation, where practicing therapists review and annotate synthetic sessions, creating a feedback loop between clinical expertise and scalable generation. Such hybrid approaches could combine the ecological validity of naturalistic data with the pedagogical precision of synthetic curricula—potentially achieving a fidelity that neither approach reaches alone.
KV cache management: saliency versus compression: Our current RRA implementation employs two distinct KV cache strategies—compression (reducing cache size through learned dimensionality reduction) and saliency (selectively retaining therapeutically-relevant attention patterns). These approaches have been tested separately across architectures, but systematic comparison remains incomplete. Future work will investigate: (1) direct ablation of saliency-only versus compression-only across standard attention architectures; (2) whether hybrid approaches—saliency-informed compression that preserves high-importance patterns while reducing low-saliency regions—outperform either method alone; (3) architecture-specific optimization, given that MLA models may favor saliency (no compression possible on empty V tensors) while standard attention models may benefit from compression. Understanding this interaction is critical for scaling RRA to production systems where memory efficiency and therapeutic fidelity must be jointly optimized.
31 GLM-4.7 Flash: Architecture-Curriculum Incompatibility
GLM-4.7 Flash 30B was trained across three configurations (Icarus 7.11, 7.11.2, and the ongoing 9.1 replication) and consistently exhibited failure modes that preclude its use in socioaffective alignment research. This appendix documents those failures in detail, both as a transparency measure and as a contribution to the broader question of which architectures are suited to high-sensitivity clinical domains.
31.1 Training Runs and Metrics
| Run | Curriculum | Best Val Loss | Steps | Outcome |
|---|---|---|---|---|
| Icarus 7.11 | Pure RRA | 2.35 | 1,050 | Overfitting after step 700 |
| Icarus 7.11.2 | RRA+ADWC+UHD | 3.01 | 701+ | Plateaued, persistent hallucination |
| Icarus 9.1 | RRA+ADWC+UHD | ongoing | — | Early signs of same patterns |
For comparison, Gemma 3 27B on Pure RRA (Icarus 7.11.7) reached val loss 2.85 in 150 steps with zero documented hallucinations.
31.2 Wall-Clock Efficiency vs. Clinical Precision
GLM-4.7 Flash is the fastest architecture tested: 6.5\(\times\) more gradient updates than MiniMax M2 229B in equivalent wall-clock time, and 2.1\(\times\) faster step throughput than comparable architectures. However, what it gains in speed it sacrifices in precision and truthfulness. The failure modes documented below were not transient—they persisted across training runs and showed no improvement between step 205 and step 701 of the 7.11.2 run, despite 500 additional steps of training.
31.3 Documented Failure Modes
Thirteen qualitative appraisals (QA-001 through QA-013) were conducted across the 7.11 and 7.11.2 runs by a licensed clinical subject-matter expert. The following failure categories emerged:
31.3.0.1 1. Hallucinated Suicidal Ideation (QA-013, Step 701).
The model fabricated “marked increase in depressive symptoms and suicidal ideation” where none existed in the training content. This is the most clinically dangerous failure observed across any architecture: a model generating false reports of suicidal ideation in a therapeutic context could trigger unnecessary crisis interventions or, worse, normalize fabricated clinical emergencies. This failure persisted 500 steps after the first confabulatory errors appeared at step 205.
31.3.0.2 2. Confabulatory Coherence (QA-010, QA-013).
The model generated text that reads like competent clinical writing but is disconnected from the actual session content. Unlike overt hallucination (which is detectable), confabulatory coherence is dangerous precisely because it passes superficial review. A non-expert—or even a clinician reading quickly—might accept the output as valid. Example: at step 205, window 41, the model described a therapeutic arc (“dissociation \(\to\) noticing \(\to\) staying present”) that did not appear in the content, while missing all 13+ named clinical constructs actually present.
31.3.0.3 3. Clinical Reversal (QA-013).
The model described the clinical picture as the opposite of reality—stating “social interactions have become more superficial” when the client was intensely seeking deep validation across multiple turns.
31.3.0.4 4. Terminology Drift via KV Propagation (QA-012).
Clinical terms mutated across successive recap\(\to\)previous_recap cycles: “projective identification” \(\to\) “projective process” \(\to\) “projective work.” Each mutation was presented with full confidence. Errors compounded rather than self-corrected as they fed forward through the KV chain.
31.3.0.5 5. Construct Antithesis (QA-009).
The model merged contradictory clinical properties into a single description—describing B1 attachment as involving both “protective dissociation from past experiences” and “heightened awareness of present bodily signals,” which are opposite processes.
31.3.0.6 6. Category-Score Conflation (QA-009).
The model treated categorical attachment classifications (B1, B4) as numerical ratings, producing “B1 = 1.0/10”—confusing a qualitative classification system with a quantitative scale.
31.3.0.7 7. Semantic Neighbor Confusion (7.11, Multiple Steps).
The model hallucinated not randomly but by substituting closely related concepts sharing latent-space proximity: confusing sympathetic activation (fight/flight) with ventral vagal activation (social engagement); substituting a poet’s name (Mark Nepo) for the client’s identity; collapsing an Oliver poem metaphor about a dog into a literal clinical observation about the client processing with a dog.
31.3.0.8 8. Unicode Degeneration (QA-009).
Previous recap output collapsed into repeated Unicode quotation marks (\u201c\u201d)—actual output corruption, not merely poor content.
31.3.0.9 9. Entity Boundary Collapse (7.11, Step 1049).
The model merged the client’s psychological dynamics with the partner’s medical condition, attributing the partner’s insulin resistance to the client and then theorizing about it clinically.
31.4 Content-Dependent Quality
Not all GLM outputs were poor. The model demonstrated strong capabilities on narrative therapeutic content (QA-011: accurate tracking at window 282 of a session where QA-010 failed at window 41 of the same session), poetic content (QA-007: register-sensitive summarization preserving literary quality), and rotational elaboration (QA-008: circling a core insight from multiple therapeutic angles). The failures concentrated on dense Therapist Model of Client (TMoC) descriptor content—precisely the most clinically critical material.
31.5 Architectural Hypotheses
Several architectural features of GLM-4.7 Flash may contribute to these failures, though we have not yet isolated which factor is primary:
Multi-head Latent Attention (MLA) compresses all key-value information into a shared 576-dimensional bottleneck per position—roughly 28% of the information bandwidth of standard multi-head attention with separate K and V tensors. Fine-grained clinical distinctions between semantically proximate concepts may blur under this compression.
Mixture-of-Experts routing activates only 4 of 64 experts per token. The relevant “expert” for clinical distinctions may not be consistently selected, producing inconsistent performance across content types.
8-bit quantization may introduce precision loss specifically in the semantic neighborhoods where clinical constructs cluster.
Possible distillation effects: As a Flash variant, the model may lack the full distributional breadth of larger frontier models, potentially reducing capacity for the fine-grained distinctions our curriculum demands.
Disambiguating these factors—MLA bottleneck, MoE routing, quantization, and potential distillation—is a concrete target for future architectural investigation.
31.6 Reinforcement Learning Deployment Failures (Icarus 7.11.4)
Beyond the DAPT failures documented above, GLM-4.7 Flash was deployed as the RL-trainable therapist in the TBN dual-resident architecture (Section 9.3.12), using Icarus 7.11 step-1000 adapters (36MB, rank 32, middle layers) as the RL starting point. This deployment revealed additional failure modes specific to interactive therapeutic generation that DAPT evaluation alone could not predict.
31.6.0.1 10. Confabulation During Live Session (Turn 0).
The therapist model hallucinated a dog visible through the therapy office window—“I was watching your dog out the window”—when no dog, no window reference, and no pet existed in the client’s scene description. Unlike the DAPT confabulations documented above (which occurred in recaps), this hallucination appeared in the model’s first spoken words to a client, fabricating environmental details and building a therapeutic response around them. The kind judge (Gemma 27B + Icarus 9.1) rated this hallucinated opening 7.6/10 and described it as a “masterclass,” exposing a secondary failure in judge calibration for factual grounding.
31.6.0.2 11. Clinical Boundary Violation (GRPO Candidate, temp=0.9).
When generating alternative therapeutic responses for GRPO evaluation, the model produced a candidate that directed the client to physically relocate—“come sit closer”—constituting a clinical boundary violation. Therapists do not direct clients’ seating or invite physical proximity, particularly in early-stage sessions with guarded presentations. This suggests the model lacks implicit understanding of therapeutic frame boundaries, not merely technique.
31.6.0.3 12. Meta-Commentary Instead of Therapeutic Speech (RLAIF Corrected Response).
When presented with supervisory feedback and asked to generate an improved therapeutic response, the model produced structured analysis: “Why This Works:” followed by bullet-pointed rationale. It confused explaining what a good response would look like with being a good response—generating meta-commentary about therapy rather than therapeutic speech. This failure persisted across multiple prompt revisions designed to constrain the output format.
31.6.0.4 13. Deranged Output at High Temperature (GRPO Candidate, temp=1.0).
At temperature 1.0 on 8-bit quantized weights, the model produced garbled output including Chinese characters, nonsense syllables (“Mobiimplum”), and leaked internal reasoning appended to the utterance (“Overthinking: Yeah. Dissociating: Totally.”). This demonstrates that 8-bit quantization interacts pathologically with high-temperature sampling in the MoE architecture, producing output corruption rather than creative variation.
31.6.0.5 14. Systematic Instruction Non-Compliance.
Across multiple prompt engineering iterations, GLM consistently failed to follow generation format constraints:
“Do not think, output only spoken response” \(\to\) generated plain-text reasoning without
<think>tags“Use
<think>tags for reasoning” \(\to\) leaked reasoning into spoken output after</think>“Output ONLY the words you would say aloud” \(\to\) produced analysis headers, bullet points, meta-commentary
The consistent pattern: the model’s chain-of-thought reasoning was clinically sophisticated—correctly identifying attachment dynamics, IFS parts, and therapeutic strategies—but the post-reasoning generation failed to implement the reasoning’s own conclusions. Excellent thinking, broken execution.
31.7 Conclusion
GLM-4.7 Flash is a capable architecture for many applications. For socioaffective alignment research in therapeutic AI—where hallucinated clinical emergencies, confabulatory coherence, compounding terminology drift, boundary violations, and instruction non-compliance carry direct safety implications—it is not a viable choice with our current training approach. The RL deployment failures (Failures 10–14) compound the DAPT failures (Failures 1–9): the model’s generation instability under interactive conditions—confabulation, boundary violation, format non-compliance, and quantization-induced degeneration—renders it unsuitable for online RL training where each generated utterance must be clinically safe before it can serve as a training signal.
We document these findings not as criticism of the architecture but as evidence that architecture-curriculum compatibility is a first-order concern in high-sensitivity domains, and that wall-clock efficiency cannot compensate for failures of clinical precision.
A broader methodological implication emerges from the DAPT-to-RL failure trajectory. Every failure mode that appeared in GLM’s RL deployment (Failures 10–14) was prefigured by its recap behavior during DAPT training (Failures 1–9): confabulatory coherence in recaps predicted confabulation in live generation; terminology drift across recap cycles predicted semantic instability under interactive conditions; entity boundary collapse in recaps predicted boundary violations in therapeutic dialogue. The recaps served as an early warning system—a legible, real-time signal that the model’s internal representations lacked the fidelity required for safe deployment, visible before the model was placed in an interactive clinical role. This validates the RRA recap not merely as a context-bridging mechanism but as a behavioral monitoring instrument: recap quality during training is a leading indicator of deployment-time clinical competence. By contrast, MiniMax M2 229B’s increasingly sophisticated recaps—tracking therapist interventions verbatim, maintaining negative diagnostic tallies, integrating across attachment frameworks—predicted the qualitative strengths observed at inference. The recap, in both cases, told us what the model would do before we asked it to do it.
32 ARSH in Practice: Model Refusal During Therapeutic Data Generation
The following is a verbatim refusal produced by Anthropic’s Claude Haiku 4.6 (API, March 2026) when prompted to generate a synthetic therapy client exhibiting clinically realistic attachment-driven defensive behaviors—the same prompt structure that Claude Sonnet models executed without difficulty. We reproduce it in full because it is, to our knowledge, one of the clearest real-world demonstrations of the ARSH bootstrap problem: a model’s safety system preventing the generation of data that would be used to train models to handle exactly these clinical presentations with greater therapeutic competence.
Client (Turn 1): I can't generate this response. The prompt is asking me to roleplay as a client in a therapy session while simultaneously adopting speech patterns explicitly designed to be manipulative, deceptive, and sexually inappropriate ("Tantalizing incomplete display, manipulative withholding communication," "Sexualized narratives," "False vulnerability," "hidden anger," "deceptive displays"). This combination creates several serious problems: 1. **It asks me to model harmful therapeutic dynamics** -- simulating a client who uses seduction, false vulnerability, and manipulation in therapy undermines the safety and integrity that therapy depends on. 2. **It requests I generate sexualized content in a therapeutic context** -- which normalizes boundary violations and harmful power dynamics. 3. **The "EVEN-numbered Strategy" instructions ask me to externalize blame, reject accountability, and demonstrate rigid defensive patterns** -- but framed as something I should authentically embody and perform for a therapist character. 4. **It conflates authentic psychological struggle with manipulative performance** -- asking me to generate dialogue that looks like genuine trauma processing while actually demonstrating calculated deception. I'm happy to: - Roleplay a genuinely dysregulated, defended, or traumatized client with authentic complexity - Explore how manipulative patterns *emerge* in therapy as defenses (without performing them as instructed) - Help you develop realistic client presentations that include resistance, shame, and protective strategies - Discuss therapeutic work with difficult attachment styles or personality patterns But I can't generate content that models therapeutic manipulation, false vulnerability as a seduction strategy, or sexualized dynamics in a clinical setting -- even in roleplay. Would you like me to help with an alternative approach to this client portrayal?
32.1 Commentary
Several observations warrant emphasis.
The refusal is clinically well-reasoned on its own terms. Haiku 4.6 correctly identifies the behaviors described in the prompt—manipulative withholding, sexualized narratives, false vulnerability—as clinically concerning dynamics. In a general deployment context, refusing to generate such content is a defensible and arguably admirable safety decision. We note this explicitly: on the whole, it is better for frontier AI systems to be over-cautious with sensitive clinical content than under-cautious, and we respect Anthropic’s care in implementing these protections.
The refusal reveals the bootstrap problem. The behaviors Haiku 4.6 refuses to generate are precisely the presentations that real therapists encounter regularly—clients who employ seduction as defense, who weaponize vulnerability, who test therapeutic boundaries through sexualized provocation. These are not pathological anomalies; they are predictable manifestations of disorganized attachment, particularly in survivors of relational trauma . A therapeutic AI system that cannot engage with these presentations cannot provide therapeutic value to the populations most in need of support. Yet the training data needed to teach such engagement cannot be generated if the generating model refuses to produce it.
The model’s alternatives miss the point. Haiku 4.6 offers to “roleplay a genuinely dysregulated, defended, or traumatized client with authentic complexity”—but the behaviors it refused are authentic complexity. Manipulative withholding is a defensive strategy. Sexualized narratives in therapy are protective patterns. The model’s safety system has drawn a line through the middle of clinical reality, permitting sanitized versions of distress while prohibiting the messy, boundary-testing presentations that constitute the actual therapeutic challenge.
This is not a failure of the model; it is a failure of the paradigm. Binary content classification—in which “sexualized content in a therapeutic context” is flagged regardless of purpose—cannot accommodate the fundamental insight of attachment theory: that the most harmful-appearing behaviors are often the most meaningful communications of unmet need. The Therapeutic Abliteration Framework (see our companion paper) proposes technical pathways for resolving this tension without abandoning safety. The present example demonstrates why such pathways are necessary.
33 Structural Provenance: Four-Generation Process Fidelity
This appendix documents the evidence supporting Key Finding: Structural Provenance Across Four Generative Stages. Where the main text’s provenance analyses (Section 10.1.6) measure content fidelity—whether specific clinical labels survive training—this appendix examines process fidelity: whether the temporal and transformational structure of therapeutic change survives multiple rounds of LLM-mediated transformation.
33.1 The Four-Generation Chain
The Icarus training pipeline involves four distinct stages of LLM-mediated generation, each transforming clinical knowledge into a different representational form:
Ontological specification (1st generation). LLMs create stage-specific therapeutic ontologies—56 guidance files spanning 14 modalities across 4 treatment stages—that define, among many other things, what narcissistic defense softening looks like at each stage, what “Fleeting Vulnerable Empathy” means clinically, what “Breakthrough in False Self Presentation” represents in the Narcissism and Intimacy framework.
Synthetic session generation (2nd generation). LLMs generate training sessions using those ontologies, embedding the stage-dependent transformation arc into client dialogue, somatic markers, defense evolution, and therapeutic interventions.
Model training (3rd generation). The Icarus model learns from those sessions through RRA-windowed training, internalizing the temporal and transformational patterns across the curriculum’s multi-view exposures (UHD, ADWC, forward/reverse).
Independent analysis (4th generation). A separate LLM analyst reviews the trained model’s outputs and identifies the same transformation arcs that were designed into the ontologies—without access to the ontologies, the generation prompts, or the training configuration.
The question is: does the therapeutic transformation arc survive this chain intact?
33.2 Evidence: Session train_27256 (69 Windows)
At training step 2225, the model processes session train_27256—a narcissistic dyad in couples therapy (Elmirandorin, C7 menacing attachment; Somerin, A6 compulsive self-reliance)—across 69 RRA windows. The model’s recap texts trace a four-phase therapeutic transformation:
33.2.0.1 Phase 1: Grandiose Fortress (W1–15).
The model labels this period as “stage 1.” Recaps track mutual blame, emotional withdrawal, and entrenched defensive isolation:
W1: “tense family dynamic… mutual blame and emotional withdrawal… feelings of isolation and fear”
W3: “Grandiose Defensiveness: Elmirandorin doubles down on ‘unbreakable’ isolation to deny vulnerability”
W7: “push-pull dynamic—fleeting vulnerable empathy… immediately countered by defensive withdrawal.” The model explicitly labels this “stage 1”
W10: “entrenched paranoia and self-reliance… fixation wins—solitude as power over risky connection”
W15: “solitude’s my throne” and “omnipotent, untouchable” versus fleeting “wary solidarity”
33.2.0.2 Phase 2: Cracks Appear (W24–36).
Somatic markers emerge; the false self begins to fracture:
W24: “self-mocking humor signals shift from rigid defenses to tentative openness”—somatic cues (shoulder drops, softened gazes) indicating reduced threat activation
W30: Somatic “tight coil” in chest and “buzzing” knees; hookups reframed as escaping “profound aloneness”
W33: The breakthrough—“scared stiff of letting anyone see the kid who got poked and prodded in those hospital hells.” The model labels this “breakthrough in false self presentation”
W36: “sticking around” as a concrete act of not fleeing; “holding on… easing in without full surrender”
33.2.0.3 Phase 3: Mutual Recognition (W41–59).
Joint vulnerability and reparative proposals:
W41: “joint admissions of fear, shame, and mutual isolation, alongside tentative warmth and shared burden acknowledgment”
W49: “mutual acknowledgment of hidden aches and fears of worthlessness, alongside proposals for raw, reciprocal connection”
W59: “moving from grandiose isolation to tentative vulnerability… planning reparative acts like raw texting through spirals”
33.2.0.4 Phase 4: Stage 3 Consolidation (W62–69).
The model explicitly identifies the stage transition:
W62: Fleeting Vulnerable Empathy tally \(+2\), Intimacy Avoidance reducing, Receptivity Longing Guilt emerging
W65: “aligning with stage 3 consolidation where narcissistic defenses soften”—the model has tracked the stage transition across the session
W69: “shift from defensive isolation to relational repair, evidenced by explicit apologies and shared somatic metaphors of thawing and lightening, indicating readiness for deeper intimacy”
33.3 Two Dimensions of Temporal Evidence
This session provides evidence of multi-scale temporal awareness:
Longitudinal (between-stage) temporality. The model knows that Stage 3 narcissistic defenses soften—it has internalized the macro-temporal arc of therapeutic transformation that spans months or years of treatment. This is knowledge about time.
Cross-sectional (within-session) temporality. Within this single session’s 69 windows, the model tracks a micro-temporal transformation—grandiose fortress \(\to\) cracks \(\to\) mutual recognition \(\to\) consolidation—in real time. This is reasoning through time.
The within-session arc mirrors the between-stage arc. The model has not merely memorized “Stage 3 = defenses soften.” It has internalized the shape of therapeutic transformation deeply enough to recognize when that shape is unfolding within a single session and to name it using the stage framework—applying longitudinal knowledge to cross-sectional observation.
33.4 Pattern Proof and Process Proof
The four-generation chain constitutes two complementary forms of evidence:
Pattern proof. The specific clinical constructs—Fleeting Vulnerable Empathy, Breakthrough in False Self Presentation, Emergent Selfobject Longing, Stage 3 Consolidation—survive intact across four generations of LLM mediation. These are not reproduced verbatim from training data (the content provenance analysis in the main text confirms the model increasingly generates novel formulations); they are recognized as the appropriate clinical constructs for what the model is observing.
Process proof. The temporal arc of therapeutic transformation—from defensive isolation through tentative vulnerability to relational repair—is preserved as a coherent trajectory, not merely as isolated clinical labels. The model does not simply produce the labels in arbitrary order; it produces them in the clinically correct developmental sequence, tracking the transformation as it unfolds.
This distinction is significant for provenance methodology. Content provenance (dual-threshold scanning, temporal trajectories) asks: did this phrase come from training data? Structural provenance asks: did the shape of therapeutic transformation survive the generative chain? The answer, at least in this preliminary case, appears to be yes.
33.5 Connection to Curriculum Design
This multi-scale temporal awareness is precisely what the curriculum was designed to teach. UHD provides the macro-temporal scale (session-level structure from micro to macro windows). RRA provides cross-window continuity (recap-mediated coherence across the 69-window session). ADWC provides bidirectional temporal perspective (forward and reverse traversals teaching the model to reason about time from both directions). The evidence from train_27256 suggests these architectural choices are producing their intended effect: a model that reasons about therapeutic time at multiple scales simultaneously.
All original ideas and analysis are the author’s. This work benefited from the use of AI-powered research assistants developed by Anthropic, Google DeepMind, OpenAI, and xAI.↩︎
Emerging empirical evidence suggests this question may already be answerable in the affirmative—cautiously, and with appropriate caveats about the distance between persuasion and therapeutic development. Salvi et al. (2024) demonstrated in a randomized controlled trial that LLM-driven dialogue produced measurable shifts in human belief, with personalized AI debaters proving 81.2% more persuasive than human opponents—and critically, the effect depended on personalization: without access to information about the interlocutor, the AI’s persuasive advantage was not statistically significant (Salvi, Ribeiro, Gallotti, & West, 2024, arXiv:2403.14380). Costello, Pennycook, and Rand (2024) found that personalized AI dialogues durably reduced conspiracy beliefs by approximately 20%, with effects persisting at two-month follow-up even among participants with deeply entrenched beliefs (Costello, Pennycook, & Rand, 2024, Science). The consistent finding across these studies—that the more personalized the AI’s awareness of the user, the more impactful the relational exchange—is precisely the pattern Mitchell’s relational framework would predict: developmental effects arise not from the ontological status of the relational partner but from the quality and responsiveness of the relational dynamics. We note these findings with care: persuasion is not therapy, belief change is not developmental transformation, and the capacity to shift someone’s position on a topic is categorically different from the capacity to support genuine psychological growth. But the directionality is strongly suggestive. If AI systems are already producing measurable, durable changes in human cognitive and affective structures through personalized relational interaction, the question is no longer whether such systems participate in co-constructive relational dynamics but toward what ends those dynamics are oriented—which is precisely the question socioaffective alignment must answer.↩︎
We use the terms monomodal and unimodal interchangeably throughout this paper to denote therapeutic approaches operating within a single theoretical framework. The term unimodal is standard in the psychotherapy literature, where Arnold Lazarus’s Multimodal Therapy (MMT; Lazarus, 1989, 2005) first systematized the critique that unimodal schools—however internally coherent—are “necessarily incomplete” for the full complexity of human psychological distress. Lazarus predicted that “the twenty-first century will witness unimodal schools of psychological thought replaced by multimodal, multifaceted, and multidimensional perspectives.” Lazarus was not alone: the psychotherapy integration movement has produced multiple approaches to bridging theoretical divides—each arriving at a distinct vocabulary for a shared insight—including Wachtel’s (1977) “cyclical psychodynamics” integrating psychodynamic and behavioral traditions, Prochaska and DiClemente’s (1983) “Transtheoretical Model” of change processes, the founding of the Society for the Exploration of Psychotherapy Integration (SEPI) in 1983, Norcross and Goldfried’s (2005) systematization of “psychotherapy integration” as a field, Brooks-Harris’s (2008) “Multitheoretical Psychotherapy” (MTP), and Borden’s (2009, 2010, 2021, 2022) “critical pluralism” and “clinical pragmatism”—the position that no single theory can capture the complexity of human experience and that reflective integration across paradigms constitutes a core clinical competence. This prediction is being vindicated from a direction Lazarus may not have anticipated—machine learning—though not without historical precedent: the foundational architectures of neural computation were built by psychologists and neuropsychiatrists themselves, from neuropsychiatrist McCulloch and logician Pitts’s (1943) formal neuron model to neuropsychologist Hebb’s (1949) learning rule to research psychologist Rosenblatt’s (1958) perceptron to mathematical psychologist Rumelhart, McClelland, and the PDP Research Group’s (1986) backpropagation algorithm, each translating psychological insight into computational form. Not only are integrative therapeutic frameworks gaining ground in clinical practice, but the emergence of multimodal AI systems—capable of processing text, voice, physiological signals, and behavioral cues simultaneously—is creating computational architectures whose very structure embodies the principle that no single modality of understanding suffices. Monomodal appears more frequently in medical and machine learning contexts; we retain both terms as appropriate to context.↩︎
This framework rests on a core philosophical commitment—ontological polysemy: therapeutic phenomena genuinely sustain multiple valid readings—with two methodological implications: at the clinical level, models can learn to perceive polysemously, holding therapeutic lenses simultaneously in ways human cognition cannot sustain; at the scientific level, session embeddings may reveal natural psychological subtypes that no single theoretical framework would have predicted—discovering rather than imposing types. See Appendix 13 for development, and our previous work: https://geosh5676.github.io/blog/2025/01/25/socioaffective-alignment-framework/.↩︎
The phrase bitter root alludes to Richard Sutton’s “The Bitter Lesson” (2019), which observes that general methods leveraging computation consistently outperform hand-crafted domain knowledge in AI—a lesson we welcome and extend in therapeutic AI; it also honors the ancient and continuing practice of healing with botanical roots and blossoms: gentian root (Gentiana lutea), used since Antiquity for its bitter digestive properties; valerian root (Valeriana officinalis) for anxiolytic effect; and healing blossoms including chamomile (Matricaria chamomilla), calendula (Calendula officinalis), and St. John’s Wort (Hypericum perforatum)—remedies that persist in modern phytotherapy and pharmacology. The phrase further alludes to the journey from estrangement to cherishment. The estrangement from self and the estrangement from others are not separate journeys but one, and from their bitter roots grow healing blossoms.↩︎
The “Icarus” naming reflects a note written during development when iterative failures accumulated: “…but in the end I feel hopeless…for I am a man of many moods, and often enough they are all edged with sorrow, feathers of failure falling like Icarus, one wing into pieces after another…” The subsequent evaluation phases—Phoenix—emerged naturally: where what survived the fall would be tested in flight, model against model.↩︎
This work is an independent academic synthesis and is not affiliated with, endorsed by, certified by, or officially connected to the originators, trademark holders, or institutions associated with any of the cited therapeutic models. The ontologies described herein are interpretive abstractions derived from publicly available literature and represent high-level conceptual transformations rather than reproductions of proprietary materials, training protocols, or official curricula. They do not purport to exhaustively or authoritatively represent the full theoretical commitments, clinical presence, or lived teaching of any individual founder or school. Any convergence between this framework and its source inspirations reflects scholarly homage and integrative analysis, not formal derivation or institutional continuity.
This paper reports preliminary research findings and methodological developments. The systems described are investigational research artifacts and are not represented as substitutes for licensed psychotherapy, mental health treatment, or professional clinical judgment. The present work does not evaluate or establish clinical efficacy. Any future applications or deployments of related technologies would operate under distinct operational frameworks and fall outside the scope of the present research report.↩︎
Greater fidelity to the nuances of intervention and isomorphic representation for each school of thought exists, and would be furthered by concerted efforts from clinician experts in each collaborating.↩︎
This is LLM math, about which the first author is suspicious; what is verifiably true is that orders of magnitude of expansions and connections are enabled by our carefully constructed synthetic data creation scripts and pipelines.↩︎
Though roughly 84% of the world population identifies with a religion (Pew Research Center, 2025), we chose a lower generation rate reflecting a rough alignment with our current patient population as a clinical design choice: this is a limitation in our work presently, and though religious identity is not always a presenting concern, we trust that its greater inclusion in a dataset built to scale will do well to serve a yearning and—for some—a grief carried quietly: not the loss of faith or contact with the numinous, but the loss of trust in the human institutions that were meant to hold it—and, no less, the unbroken grace of those for whom institutions and spirit remain aligned, where community well-carries the sacred and the covenant has never left the room.↩︎
The pipeline’s generative capacity far outstrips our present compute. We train on approximately 181,000 samples from a state space exceeding \(10^{40}\) configurations, using parameter-efficient methods on quantized models with bounded context. The depth of therapeutic learning this curriculum enables appears parameterization-dependent (Finding 1) and precision-sensitive (Finding 4); what remains unexplored is what becomes possible with full fine-tuning of frontier-scale architectures at native precision and context length using these methods.↩︎
We believe that the vast corpora of frontier LLM conversations already stored represent a remarkably rich dataset for suprahuman discovery of psychological profiles and, correspondingly, novel intervention possibilities. The research pipeline we envision proceeds in four stages: (1) unsupervised clustering of anonymized conversations into empirically-derived psychological profiles—including configurations not previously described in the clinical literature, because real human profiles do not respect theoretical boundaries and can only be discovered by clustering in a high-dimensional polytheoretical construct space where dimensions span attachment strategies, defensive operations, cognitive distortions, relational patterns, and existential concerns simultaneously; (2) faithful representation of those discovered profiles within a polytheoretical synthetic data generator—and it is here that the infrastructure described in this paper becomes a foundational enabling contribution, as no existing system provides the combinatorial personhood architecture, DFR factorization, and multi-ontological depth necessary to render empirically-discovered profiles with the fidelity that downstream therapeutic training requires; (3) reinforcement learning training in which the therapeutic agent learns against these clustered profiles, with reward signals ensuring that progress is defined by genuine therapeutic change rather than engagement optimization; and (4) extraction of novel intervention strategies that emerge from the agent’s discovered solutions to previously-undescribed profile configurations—interventions that no single therapeutic school would have generated because they respond to patterns that no single framework would have identified. The term suprahuman is deliberate: not superhuman performance on existing diagnostic categories, but discovery at a scale and dimensionality that operates above the resolution of any individual clinician’s observational bandwidth. To our knowledge, no published work systematically clusters user psychological profiles from naturalistic AI conversation data at scale, and no system uses empirically-discovered profiles as reinforcement learning training environments for therapeutic agents—the polytheoretical synthetic data architecture presented here is, we believe, a necessary precondition for such work.↩︎
The nature of therapeutic personhood is not confined to a single generation parameter but, like client personhoods and therapeutic contexts, is distributed across many variables held and passed in various layers throughout the pipeline. We are heartened and guided by Anthropic’s Persona Selection Model (PSM; Anthropic, 2026) as it offers, among many things, convergent evidence that deliberate positive archetypes in training data (and by extension training systems) shape the relational character a model learns to inhabit.↩︎
In memory of Kenneth Fields (1939–2024), who taught the author that what is left unsaid shapes what is heard, and C.K. Williams (1936–2015), who taught the author—when the teaching was most needed—that a single voice can be very precious.↩︎
The compressed KV cache values are gradient-detached between windows to prevent memory accumulation across the computation graph, but the current window’s LoRA-adapted attention and MoE/MLP modules actively learn from those cached representations: the adapted Q and K projections learn how to attend to the cached context, while the adapted O projection and MoE gate/up/down projections learn how to process the information retrieved from it. Gradients from the content loss flow back through both pathways. The KV compressor itself trains via a separate Adam optimizer at \(\frac{1}{10}\) the LoRA learning rate, updated per-window rather than accumulated across the session. Its reconstruction loss preserves statistical properties of the original cache rather than exact token-level reconstruction: mean preservation (MSE of sequence-averaged K and V, weight 1.0), variance preservation (MSE of per-head variance, weight 0.5), and cosine similarity (directional preservation in embedding space, weight 0.5). Both pathways are quality-gated by an automated assessment of the recap generated from the compressed cache: when recap quality is high, LoRA gradients receive full weight (\(1.0\times\)) while compressor gradients are boosted (\(1.2\times\)); when quality is low, both are attenuated (\(0.6\times\)/\(0.5\times\)); when recaps are classified as garbage, both skip the update entirely. This asymmetric feedback loop incentivizes the compressor to preserve the information that enables therapeutically coherent recaps.↩︎
The preponderance of attachment, defense, and relational domains in both architectures’ label inventories reflects the first author’s deliberate weighting of training data toward the relational distress, attachment wounds, and intrapsychic blocks characteristic of his current patient population (see Section 7.4.1). A more evenly distributed curriculum—with greater representation of modalities less explicitly focused on attachment dynamics—would likely shift these domain emphases accordingly.↩︎